Building
- Create a Large Language Model from Scratch with Python - Tutorial - YouTube
- Understanding Large Language Models - by Sebastian Raschka
- Large language models, explained with a minimum of math and jargon
- Catching up on the weird world of LLMs
- Llama from scratch (or how to implement a paper without crying) | Brian Kitano
- Llama - EXPLAINED! - YouTube
- LLM2 Module 1 - Transformers | 1.6 Base/Foundation Models - YouTube
- 20 papers to master Language modeling? - YouTube
- Bringing Llama 3 to Life | Joe Spisak, Delia David, Kaushik Veeraraghavan & Ye (Charlotte) Qi - YouTube
- GitHub - rasbt/reasoning-from-scratch: Implement a reasoning LLM in PyTorch from scratch, step by step ⭐ 4.2k
Architecture
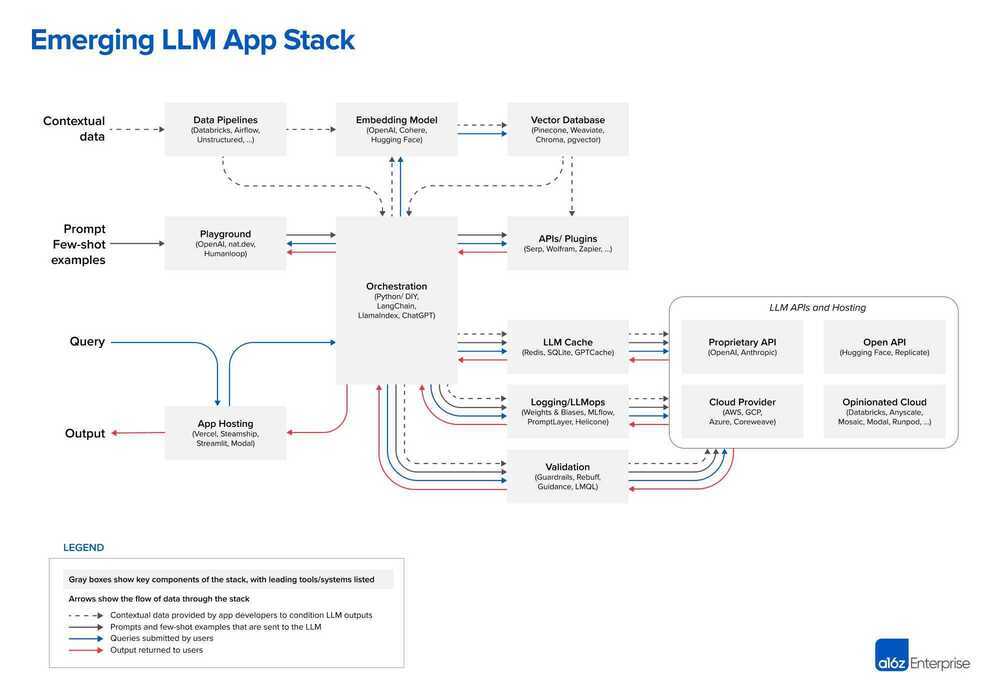
Emerging Architectures for LLM Applications | Andreessen Horowitz
Transformers, explained: Understand the model behind GPT, BERT, and T5 - YouTube
- Positional encodings
- Attention
- Self attention
- GPT3 - 45tb of text data
Let’s Architect! Discovering Generative AI on AWS | AWS Architecture Blog
Building
Decoding Strategies
- Greedy Search
- Beam search in Large Language Models (LLMs) is a decoding strategy that explores multiple potential output sequences simultaneously, keeping track of the most promising "beams" (or sequences) at each step, to find the most likely output.
- Decoding Demystified : How LLMs Generate Text - III - DEV Community
- Decoding Strategies in Large Language Models – Maxime Labonne
- Decoding Strategies in Large Language Models
- Decoding Strategies: How LLMs Choose The Next Word
- Understanding greedy search and beam search | by Jessica López Espejel | Medium
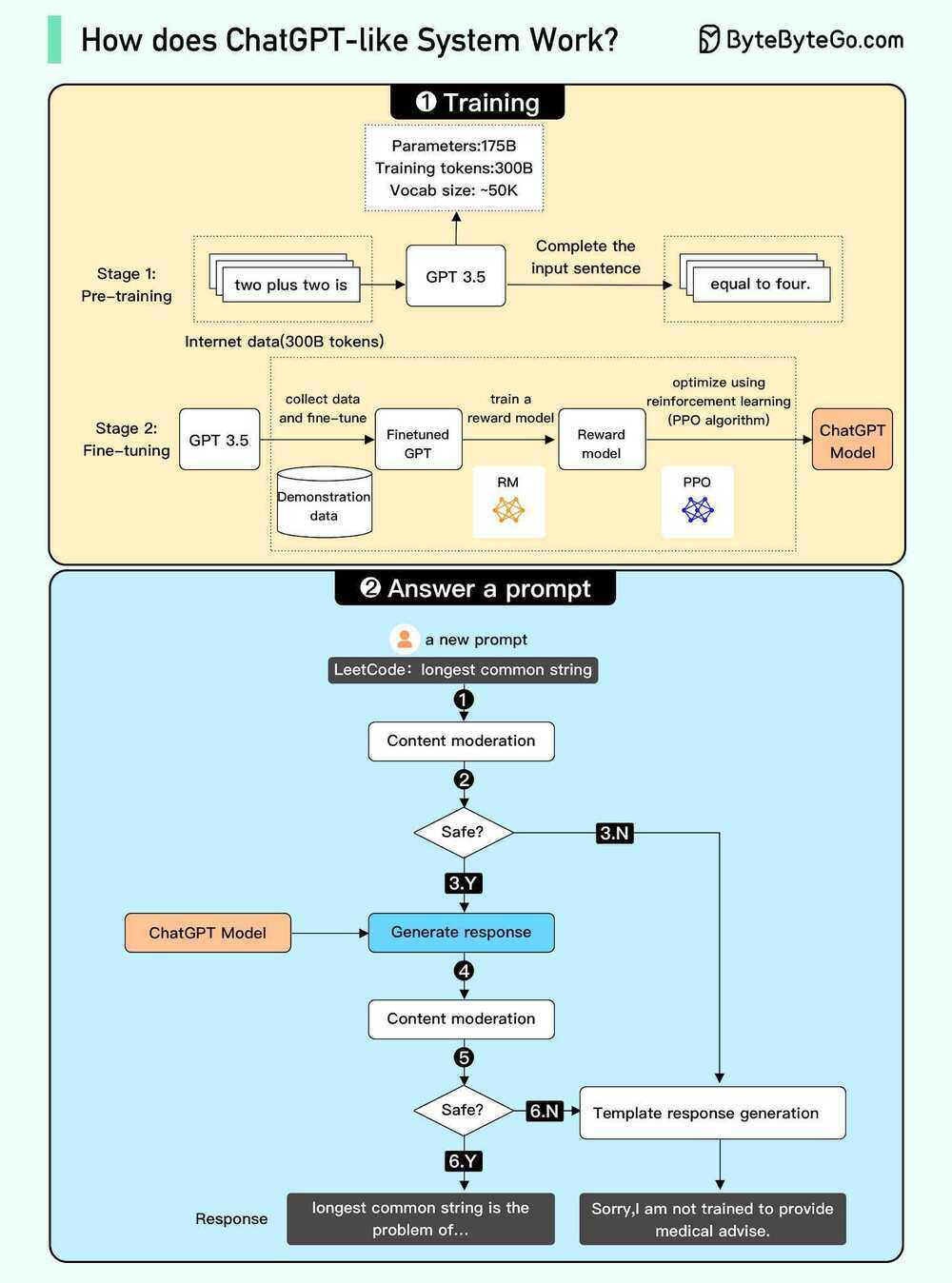
How to train your ChatGPT
Stage 1: Pretraining
- Download ~10TB of text
- Get a cluster of ~6,000 GPUs
- Compress the text into a neural network, pay ~$2M, wait ~12 days
- Obtain base model
Stage 2: Finetuning
- Write labeling instructions
- Hire people (or use scale.ai!), collect 100K high quality ideal Q&A responses, and/or comparisons
- Finetune base model on this data, wait ~1 day
- Obtain assistant model
- Run a lot of evaluations
- Deploy
- Monitor, collect misbehaviors, go to step 1
LLM Security
- Jailbreaking
- Prompt injection
- Backdoors & data poisoning
- Adversarial inputs
- Insecure output handling
- Data extraction & privacy
- Data reconstruction
- Denial of service
- Escalation
- Watermarking & evasion
- Model theft
1hr Talk Intro to Large Language Models - YouTube
Awesome ChatGPT Prompts | This repo includes ChatGPT prompt curation to use ChatGPT better.
Distillation Attack
A distillation attack occurs when someone systematically queries a proprietary AI model and uses its outputs to train a smaller or competing model, effectively ‘stealing’ its capabilities without access to the original weights.
Instead of copying parameters, the attacker copies behaviour by treating the target model as a teacher and learning from its responses at scale. For developers building AI products, this raises serious concerns around API exposure, rate limits, watermarking, and model output monitoring.
Others
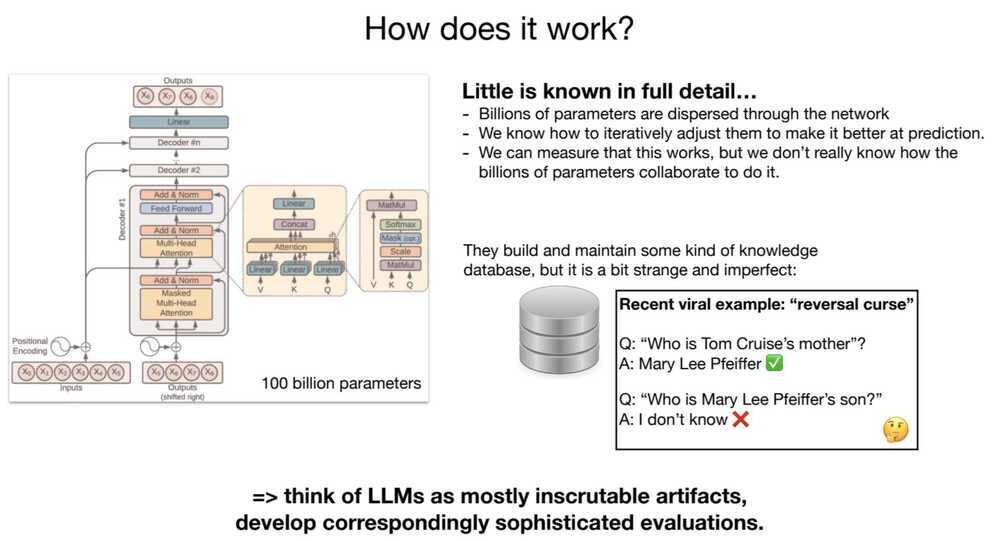
People have a lot of implicit knowledge — things we know but struggle to fully explain. People often use body-oriented metaphors for this phenomenon. We say that an insight is “on the tip of our tongue,” that we “can’t put our finger on” an idea, or that we know something “in our gut.”
Something similar is true of LLMs: their ability to perform cognitive tasks greatly exceeds their ability to explicitly explain how and why they’re able to perform them.
Dev Tools
-
LangChain
-
Langfuse
-
Eden AI
-
Langdock
-
LLM Spark
-
Introducing Code Llama, a state-of-the-art large language model for coding
-
GitHub - jerryjliu/llama_index: LlamaIndex (GPT Index) is a data framework for your LLM applications ⭐ 49k
-
Building your Generative AI apps with Meta's Llama 2 and Databricks | Databricks Blog
-
GitHub - stoyan-stoyanov/llmflows: LLMFlows - Simple, Explicit and Transparent LLM Apps ⭐ 706
-
GitHub - ShishirPatil/gorilla: Gorilla: An API store for LLMs ⭐ 13k
-
GitHub - Chainlit/chainlit: Build Python LLM apps in minutes ⚡️ ⭐ 12k
-
GitHub - tensorchord/Awesome-LLMOps: An awesome & curated list of best LLMOps tools for developers ⭐ 5.8k
-
GitHub - bentoml/OpenLLM: Operating LLMs in production ⭐ 12k
-
GitHub - agiresearch/AIOS: AIOS: LLM Agent Operating System ⭐ 5.6k
-
AirLLM Unleashed. Efficiently Running 70B LLM Inference… | by Haribaskar Dhanabalan | Medium
Ollama / LM Studio
The easiest way to get up and running with large language models locally.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker exec -it ollama ollama run llama2
docker exec -it ollama ollama run llama2-uncensored
docker exec -it ollama ollama run mistral
>>> /? # for help
- Docker
- LM Studio - SUPER EASY Text AI - Windows, Mac & Linux / How To - YouTube
- LM Studio - Discover, download, and run local LLMs
- Ollama Course – Build AI Apps Locally - YouTube
- Run DeepSeek-R1 on Your Laptop with Ollama - DEV Community
- Jan: Open source ChatGPT-alternative that runs 100% offline - Jan
- NodeShift - Sovereign AI Cloud
Options
- LM Studio – A polished desktop application with a built-in search for finding and downloading models from Hugging Face. It is the easiest way to visually manage models and adjust hardware settings like GPU offloading without touching a terminal.
- Ollama – A lightweight command-line tool that runs as a background service to serve models via a simple API. It is the best choice for developers who want to integrate local AI into other apps or run models with a single terminal command.
- MLX-LM – Apple’s official framework optimized specifically for Apple Silicon to achieve the highest possible inference speeds. It is the "performance king" for those comfortable with Python who want to squeeze every drop of power from their Mac's GPU.
- Jan.ai – An open-source, privacy-focused assistant that provides a clean chat interface similar to ChatGPT but entirely offline. It is ideal for users who want organized chat history, file uploads, and a "set-it-and-forget-it" local workspace.
- GPT4All – A beginner-friendly app designed to run efficiently on standard CPUs without needing a powerful graphics card. It features a built-in "LocalDocs" tool that lets you chat privately with your own PDF and text collections out of the box.
Ludwig
Ludwig is an open-source, declarative machine learning framework that makes it easy to define deep learning pipelines with a simple and flexible data-driven configuration system. Ludwig is suitable for a wide variety of AI tasks, and is hosted by the Linux Foundation AI & Data.
Ludwig enables you to apply state-of-the-art tabular, natural language processing, and computer vision models to your existing data and put them into production with just a few short commands.
Others
SAAS
- DataRobot AI Platform | Deliver Value from AI
- Accelerating Systems with Real-time AI Solutions - Groq
- CrewAI
Resources
- LLM Visualization
- Development with Large Language Models Tutorial - OpenAI, Langchain, Agents, Chroma - YouTube
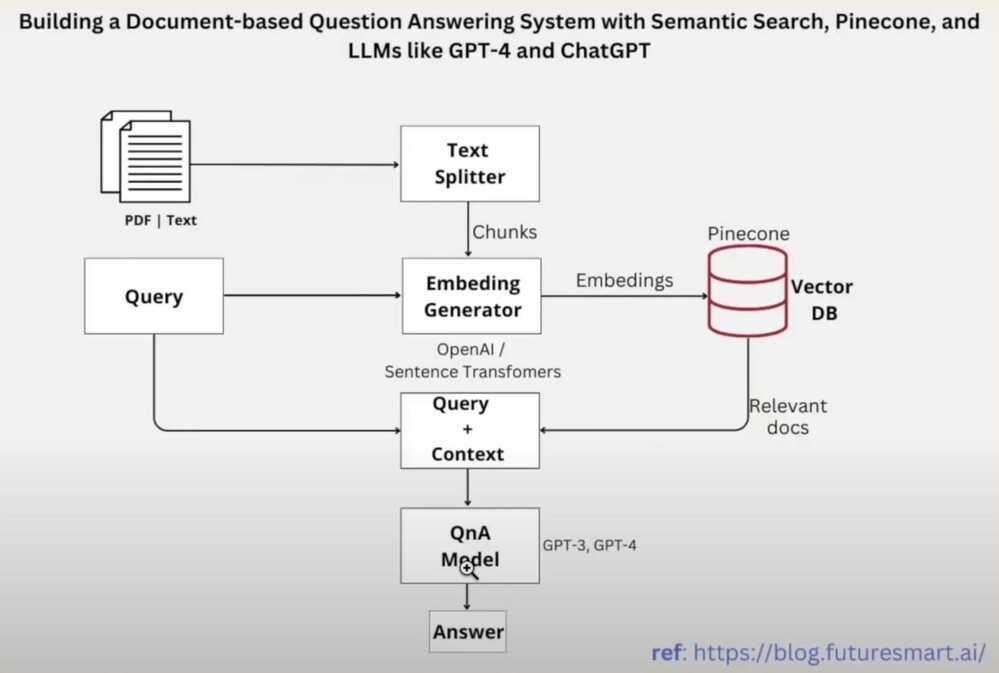
- GitHub - openai/openai-cookbook: Examples and guides for using the OpenAI API ⭐ 73k
- Vector Embeddings Tutorial - Create an AI Assistant with GPT-4 & Natural Language Processing - YouTube
- This new AI is powerful and uncensored… Let’s run it - YouTube
- Learn Generative AI in 30 Hours
- AI Watermarking 101: Tools and Techniques
- Optimize generative AI applications with pgvector indexing: A deep dive into IVFFlat and HNSW techniques | AWS Database Blog
- V-JEPA: The next step toward advanced machine intelligence
- GitHub - GoogleCloudPlatform/generative-ai: Sample code and notebooks for Generative AI on Google Cloud, with Gemini on Vertex AI ⭐ 17k
- ThunderKittens to make the GPUS go brr - by Bugra Akyildiz
- RoCE networks for distributed AI training at scale - Engineering at Meta
- GitHub - naklecha/llama3-from-scratch: llama3 implementation one matrix multiplication at a time ⭐ 15k
- What We’ve Learned From A Year of Building with LLMs – Applied LLMs
- Let's reproduce GPT-2 (124M) - YouTube
- Scaling and Reliability Challenges of LLama3
- Building LLMs from the Ground Up: A 3-hour Coding Workshop - YouTube
- How AWS engineers infrastructure to power generative AI
- Advanced RAG Pipelines with LlamaIndex & Amazon Bedrock - YouTube
- Deep Dive into LLMs like ChatGPT - YouTube
- How Do AI Agents Actually Work? - YouTube
- What makes LLM tokenizers different from each other? GPT4 vs. FlanT5 Vs. Starcoder Vs. BERT and more - YouTube
- LLM Visualization
- [Full Workshop] Reinforcement Learning, Kernels, Reasoning, Quantization & Agents — Daniel Han - YouTube
- How Meta animates AI-generated images at scale - Engineering at Meta
- How LLMs Handle Infinite Context With Finite Memory | Towards Data Science
- GitHub - OpenPipe/ART: Agent Reinforcement Trainer: train multi-step agents for real-world tasks using GRPO. Give your agents on-the-job training. Reinforcement learning for Qwen3.6, GPT-OSS, Llama, and more! · GitHub ⭐ 9.8k