Langchain
Welcome to LangChain - 🦜🔗 LangChain 0.0.180
- Building LLM applications for production
- Introduction to LangChain LLM: A Beginner’s Guide
- How to Build LLM Applications with LangChain | DataCamp

python -m pip install --upgrade langchain[llm]
pip install chromadb
pip install pypdf
pip install chainlit
chainlit hello
chainlit run document_qa.py
Langchain vs LlamaIndex
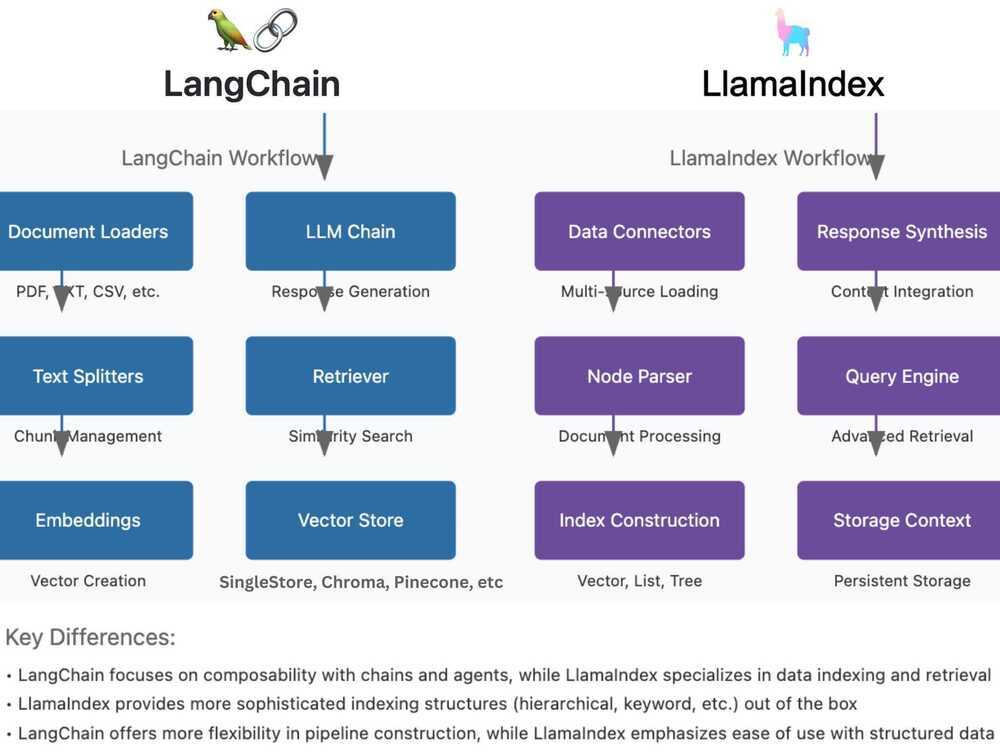
Both LangChain & LlamaIndex offer distinct approaches to implementing RAG workflows.
LangChain follows a modular pipeline starting with Document Loaders that handle various file formats, followed by Text Splitters for chunk management, and Embeddings for vector creation.
It then utilizes Vector Stores like SingleStore, FAISS or Chroma for storage, a Retriever for similarity search, and finally, an LLM Chain for response generation. This framework emphasizes composability and flexibility in pipeline construction.
On the other hand, LlamaIndex begins with Data Connectors for multi-source loading, employs a Node Parser for sophisticated document processing, and features diverse Index Construction options including vector, list, and tree structures.
It implements a Storage Context for persistent storage, an advanced Query Engine for retrieval, and Response Synthesis for context integration. LlamaIndex specializes in data indexing and retrieval, offering more sophisticated indexing structures out of the box, while maintaining a focus on ease of use with structured data.
The key distinction lies in their approaches: LangChain prioritizes customization and pipeline flexibility, while LlamaIndex emphasizes structured data handling and advanced indexing capabilities, making each framework suitable for different use cases in RAG implementations.
No matter what AI framework you pick, I always recommend using a robust data platform like SingleStore that supports not just vector storage but also hybrid search, low latency, fast data ingestion, all data types, AI frameworks integration, and much more.
A Beginner’s Guide to Building LLM-Powered Applications with LangChain! - DEV Community
Understanding LlamaIndex in 9 Minutes! - YouTube
LangGraph
- GitHub - wassim249/fastapi-langgraph-agent-production-ready-template: A production-ready FastAPI template for building AI agent applications with LangGraph integration. This template provides a robust foundation for building scalable, secure, and maintainable AI agent services. · GitHub ⭐ 2.4k
- Swagger UI - http://localhost:8000/docs
- Grafana dashboards - http://localhost:3000 - admin,admin
- Prometheus metrics - http://localhost:9090
- Build Agentic Workflows Using LangGraph! - YouTube
- LangChain vs. LangGraph: Which AI Framwork Is Right for You?
- AI Agent Workflows: A Complete Guide on Whether to Build With LangGraph or LangChain | by Sandi Besen | Towards Data Science
- GitHub - neo4j-labs/llm-graph-builder: Neo4j graph construction from unstructured data using LLMs ⭐ 4.8k
- Neo4j LLM Knowledge Graph Builder - Extract Nodes and Relationships from Unstructured Text
- GraphRAG Python Package: Accelerating GenAI With Knowledge Graphs
- User Guide: RAG — neo4j-graphrag-python documentation
- GenAI Stack
- Building LangGraph: Designing an Agent Runtime from first principles
- How to Build Effective Agentic Systems with LangGraph | Towards Data Science
Getting Started
Quickstart - Docs by LangChain
- Define tools and model
- Define state
- Define model node
- Define tool node
- Define end logic
- Build and compile the agent
pip install -U "langchain[google-genai]"
export GEMINI_API_KEY=AIabc123
python app.py
# Step 1: Define tools and model
from langchain.tools import tool
from langchain.chat_models import init_chat_model
model = init_chat_model(
"google_genai:gemini-2.5-flash-lite",
temperature=0
)
# Define tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply `a` and `b`.
Args:
a: First int
b: Second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds `a` and `b`.
Args:
a: First int
b: Second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide `a` and `b`.
Args:
a: First int
b: Second int
"""
return a / b
# Augment the LLM with tools
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
model_with_tools = model.bind_tools(tools)
# Step 2: Define state
from langchain.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
llm_calls: int
# Step 3: Define model node
from langchain.messages import SystemMessage
def llm_call(state: dict):
"""LLM decides whether to call a tool or not"""
return {
"messages": [
model_with_tools.invoke(
[
SystemMessage(
content="You are a helpful assistant tasked with performing arithmetic on a set of inputs."
)
]
+ state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}
# Step 4: Define tool node
from langchain.messages import ToolMessage
def tool_node(state: dict):
"""Performs the tool call"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# Step 5: Define logic to determine whether to end
from typing import Literal
from langgraph.graph import StateGraph, START, END
# Conditional edge function to route to the tool node or end based upon whether the LLM made a tool call
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""Decide if we should continue the loop or stop based upon whether the LLM made a tool call"""
messages = state["messages"]
last_message = messages[-1]
# If the LLM makes a tool call, then perform an action
if last_message.tool_calls:
return "tool_node"
# Otherwise, we stop (reply to the user)
return END
# Step 6: Build agent
# Build workflow
agent_builder = StateGraph(MessagesState)
# Add nodes
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
# Add edges to connect nodes
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
# Compile the agent
agent = agent_builder.compile()
from IPython.display import Image, display
# Show the agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# Invoke
from langchain.messages import HumanMessage
messages = [HumanMessage(content="Add 3 and 4.")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
Thinking in LangGraph - Docs by LangChain
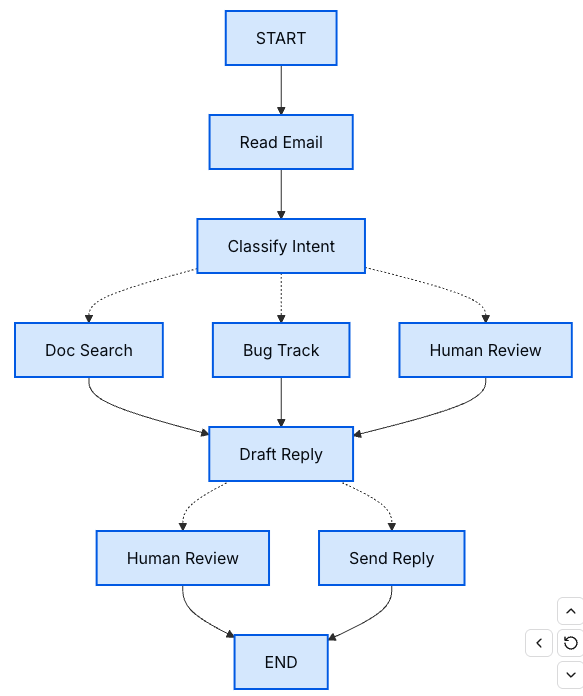
Start with the process you want to automate
- Step 1: Map out your workflow as discrete steps
- Step 2: Identify what each step needs to do
- LLM steps
- Data steps
- Action steps
- User input steps
- Step 3: Design your state
- What belongs in state?
- Include in state - Does it need to persist across steps? If yes, it goes in state.
- Don't store - Can you derive it from other data? If yes, compute it when needed instead of storing it in state.
- Keep state raw, format prompts on-demand
- What belongs in state?
- Step 4: Build your nodes
- Handle errors appropriately
- Implementing our email agent nodes
- Step 5: Wire it together
Courses
- GraphAcademy — Free, Self-Paced, Hands-on Online Training
- Graph Data Modeling Fundamentals
- Persistence - Docs by LangChain
- Durable execution - Docs by LangChain
LangSmith
- LangSmith
- What is LangSmith and why should I care as a developer? | by Logan Kilpatrick | Around the Prompt | Medium