Interview Questions
Can you provide a high-level overview of Transformers' architecture?
Let’s begin by looking at the model as a single black box. In a machine translation application, it would take a sentence in one language, and output its translation in another, as illustrated below,

Getting closer into the black box, transformers have on the inside:
- An encoding component: which is a stack of
Nencoders. - A decoding component: which is a stack of
Ndecoders, - and connections between them.
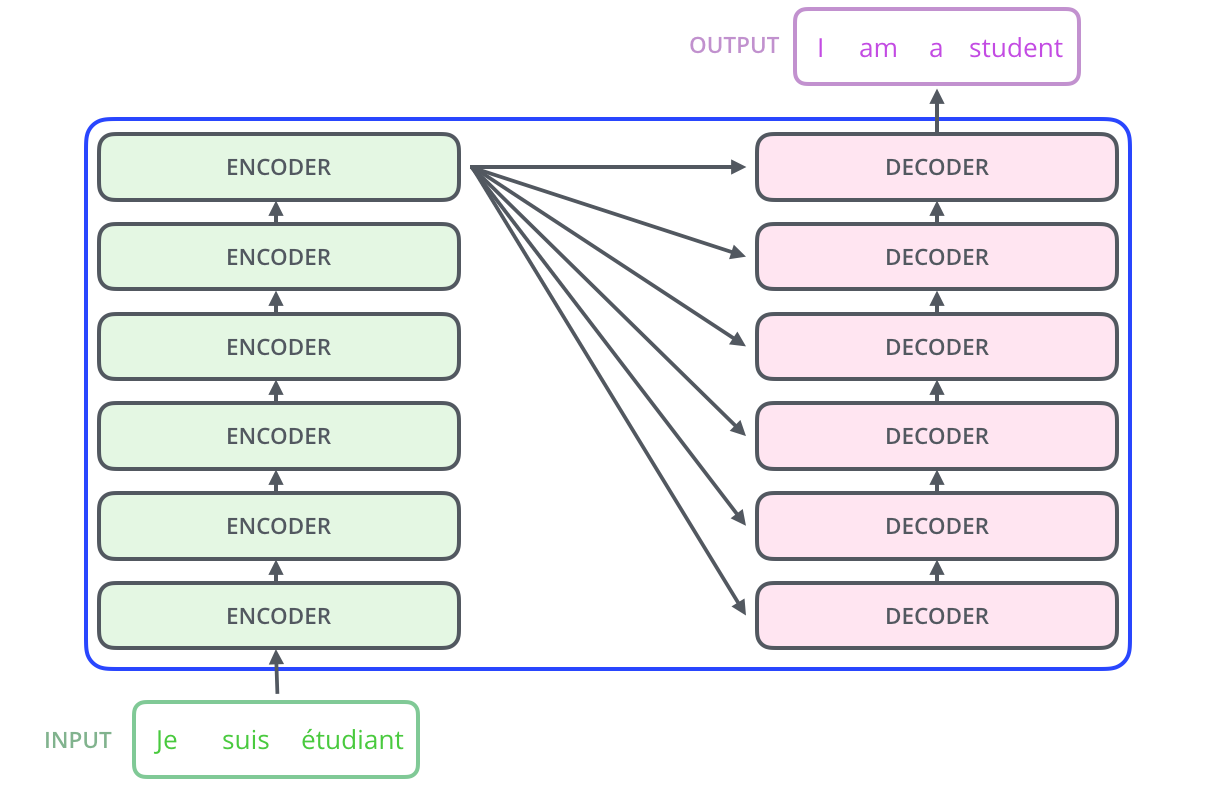
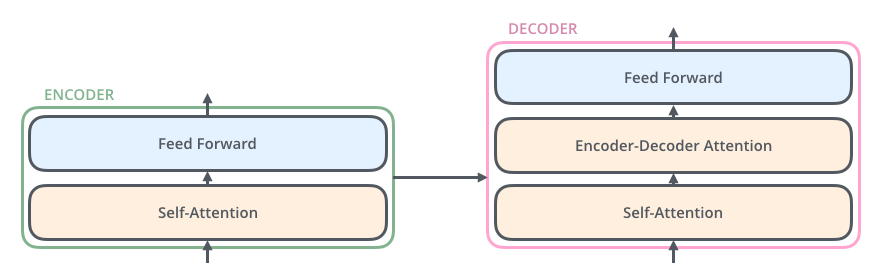
Now, each encoder is broken down into two sub-layers: the self-attention layer and the feed-forward neural network layer.
The inputs first flow through a self-attention layer, and the outputs of the self-attention layer are fed to a feed-forward neural network. And this sequence is repeated till reaches the last encoder.
Finally, the decoder receives the output of the encoder component and also has both the self-attention layer and feed-forward layer, and the flow is similar to before, but between them there is an attention layer that helps the decoder focus on relevant parts of the input sentence.
How next sentence prediction (NSP) is used in language modeling?
Next sentence prediction (NSP) is used in language modeling as one-half of the training process behind the BERT model (the other half is masked-language modeling (MLM)). The objective of next-sentence prediction training is to predict whether one sentence logically follows the other sentence presented to the model.
During training, the model is presented with pairs of sentences, some of which are consecutive in the original text, and some of which are not. The model is then trained to predict whether a given pair of sentences are adjacent or not. This allows the model to understand longer-term dependencies across sentences.
Researchers have found that without NSP, BERT performs worse on every single metric - so its use it’s relevant to language modeling.
How can you evaluate the performance of Language Models?
There are two ways to evaluate language models in NLP: Extrinsic evaluation and Intrinsic evaluation.
- Intrinsic evaluation captures how well the model captures what it is supposed to capture, like probabilities.
- Extrinsic evaluation (or task-based evaluation) captures how useful the model is in a particular task.
A common intrinsic evaluation of LM is the perplexity. It's a geometric average of the inverse probability of words predicted by the model. Intuitively, perplexity means to be surprised. We measure how much the model is surprised by seeing new data. The lower the perplexity, the better the training is. Another common measure is the cross-entropy, which is the Logarithm (base 2) of perplexity. As a thumb rule, a reduction of 10-20% in perplexity is noteworthy.
The extrinsic evaluation will depend on the task. Example: For speech recognition, we can compare the performance of two language models by running the speech recognizer twice, once with each language model, and seeing which gives the more accurate transcription.
How do generative language models work?
The very basic idea is the following: they take n tokens as input, and produce one token as output.
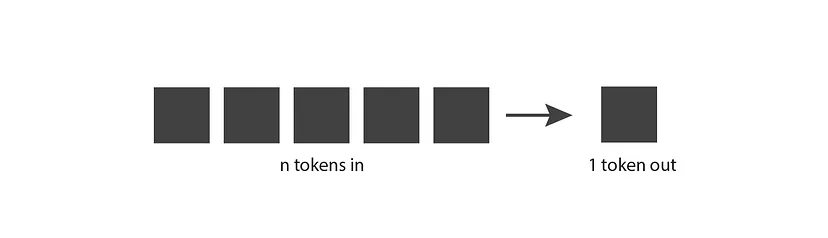
A token is a chunk of text. In the context of OpenAI GPT models, common and short words typically correspond to a single token and long and less commonly used words are generally broken up into several tokens.
This basic idea is applied in an expanding-window pattern. You give it n tokens in, it produces one token out, then it incorporates that output token as part of the input of the next iteration, produces a new token out, and so on. This pattern keeps repeating until a stopping condition is reached, indicating that it finished generating all the text you need.
Now, behind the output is a probability distribution over all the possible tokens. What the model does is return a vector in which each entry expresses the probability of a particular token being chosen.
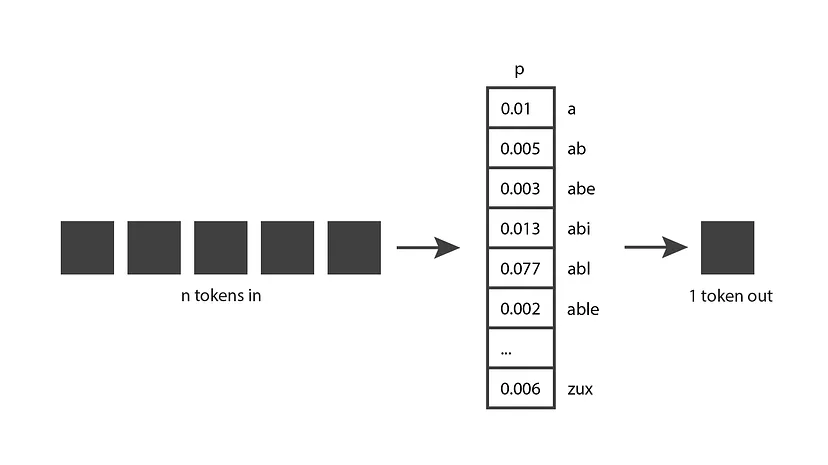
This probability distribution comes from the training phase. During training, the model is exposed to a lot of text, and its weights are tuned to predict good probability distributions, given a sequence of input tokens.
GPT generative models are trained with a large portion of the internet, so their predictions reflect a mix of the information they’ve seen.
What is a token in the Large Language Models context?
ChatGPT and other LLMs rely on input text being broken into pieces. Each piece is about a word-sized sequence of characters or smaller. We call those sub-word tokens. That process is called tokenization and is done using a tokenizer.
Tokens can be words or just chunks of characters. For example, the word "hamburger" gets broken up into the tokens "ham", "bur" and "ger", while a short and common word like "pear" is a single token. Many tokens start with whitespace, for example, " hello" and " bye".
The models understand the statistical relationships between these tokens and excel at producing the next token in a sequence of tokens.
The number of tokens processed in a given API request depends on the length of both your inputs and outputs. As a rough rule of thumb, the 1 token is approximately 4 characters or 0.75 words for English text.
Consider:
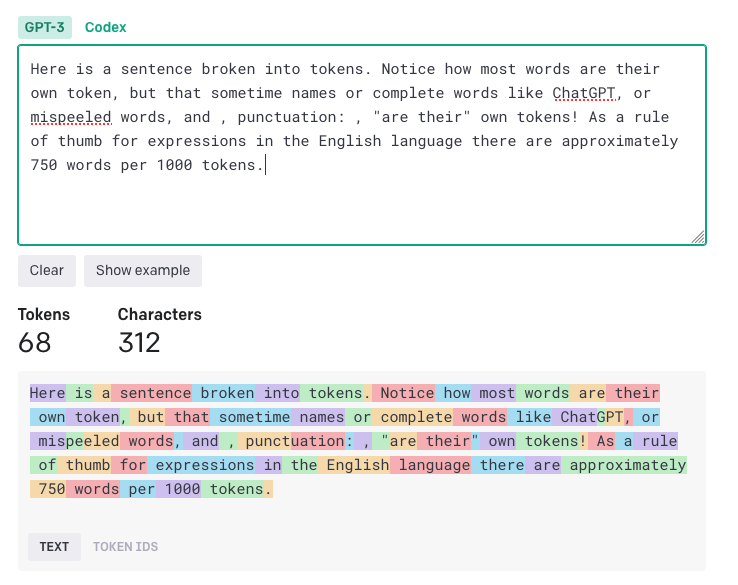
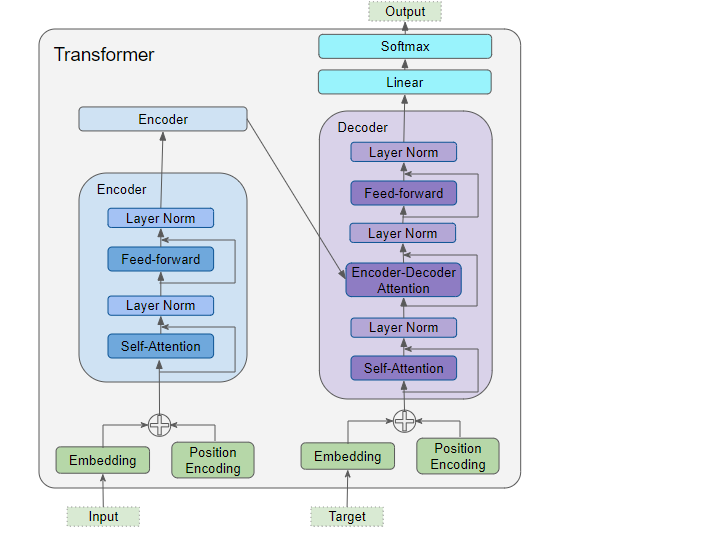
What's the advantage of using transformer-based vs LSTM-based architectures in NLP?
To create sequence-to-sequence models before the Transformer, we used the famous LSTM with its Encoder-Decoder architecture, where
- The "Encoder" part that creates a vector representation of a sequence of words.
- The "Decoder" returns a sequence of words from the vector representation.
The LSTM model takes into account the interdependence of words, so we need inputs of the previous state to make any operations on the current state. This model has a limitation: it is relatively slow to train and the input sequence can't be passed in parallel.
Now, the idea of the Transformer is to maintain the interdependence of the words in a sequence without using a recurrent network but only the attention mechanism that is at the center of its architecture. The attention measures how closely two elements of two sequences are related.
In transformer-based architectures, the attention mechanism is applied to a single sequence (also known as a self-attention layer). The self-attention layer determines the interdependence of different words in the same sequence, to associate a relevant representation with it. Take for example the sentence: "The dog didn't cross the street because it was too tired". It is obvious to a human being that "it" refers to the "dog" and not to the "street". The objective of the self-attention process will therefore be to detect the link between "dog" and "it". This feature makes transformers much faster to train compared to their predecessors, and they have been proven to be more robust against noisy and missing data.
As a plus, in contextual embeddings, transformers can draw information from the context to correct missing or noisy data and that is something that other neural networks couldn’t offer.
Can you provide some examples of alignment problems in Large Language Models?
The alignment problem refers to the extent to which a model's goals and behavior align with human values and expectations.
Large Language Models, such as GPT-3, are trained on vast amounts of text data from the internet and are capable of generating human-like text, but they may not always produce output that is consistent with human expectations or desirable values.
The alignment problem in Large Language Models typically manifests as:
- Lack of helpfulness: when the model is not following the user's explicit instructions.
- Hallucinations: when the model is making up unexisting or wrong facts.
- Lack of interpretability: when it is difficult for humans to understand how the model arrived at a particular decision or prediction.
- Generating biased or toxic output: when a language model that is trained on biased/toxic data may reproduce that in its output, even if it was not explicitly instructed to do so.
How Adaptative Softmax is useful in Large Language Models?
Adaptive softmax is useful in large language models because it allows for efficient training and inference when dealing with large vocabularies. Traditional softmax involves computing probabilities for each word in the vocabulary, which can become computationally expensive as the vocabulary size grows.
Adaptive softmax reduces the number of computations required by grouping words together into clusters based on how common the words are. This reduces the number of computations required to compute the probability distribution over the vocabulary.
Therefore, by using adaptive softmax, large language models can be trained and run more efficiently, allowing for faster experimentation and development.
How does BERT training work?
BERT (Bidirectional Encoder Representations from Transformers) utilizes a transformer architecture that learns contextual relationships between words in a text and since BERT’s goal is to generate a language representation model, it only needs the encoder part.
The input to the encoder for BERT is a sequence of tokens, which are first converted into vectors and then processed in the neural network. Then, the BERT algorithm makes use of the following two training techniques:
- Masked LM (MLM): Before feeding word sequences into BERT, a percentage of the words in each sequence are replaced with a
[MASK]token. The model then attempts to predict the original value of the masked words, based on the context provided by the other, non-masked, words in the sequence. - Next Sentence Prediction (NSP): the model concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, and sometimes not. The model then has to predict if the two sentences were following each other or not.
Now, to help the model distinguish between the two sentences in training, the input is processed with some extra metadata such as:
- Token embeddings: A
[CLS]token is inserted at the beginning of the first sentence and a[SEP]token is inserted at the end of each sentence. - Segment embeddings: these assign markers to identify each sentence and allows the encoder to distinguish between them.
- Positional embeddings: to indicate the token position in the sentence.
Then, to predict if the second sentence is indeed connected to the first, the following steps are performed:
- The entire input sequence goes through the Transformer model.
- The output of the
[CLS]token is transformed into a2×1shaped vector, using a simple classification layer (learned matrices of weights and biases). - Calculating the probability of
IsNextSequencewith softmax.
When training the BERT model, Masked LM and Next Sentence Prediction are trained together, with the goal of minimizing the combined loss function of the two strategies.
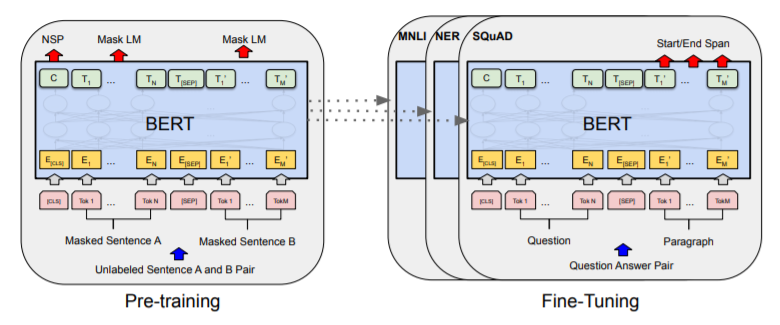
How is the Transformer Network better than CNNs and RNNs?
- With RNN, you have to go word by word to access to the cell of the last word. If the network is formed with a long reach, it may take several steps to remember, each masked state (output vector in a word) depends on the previous masked state. This becomes a major problem for GPUs. This sequentiality is an obstacle to the parallelization of the process. In addition, in cases where such sequences are too long, the model tends to forget the contents of the distant positions one after the other or to mix with the contents of the following positions. In general, whenever long-term dependencies are involved, we know that RNN suffers from the Vanishing Gradient Problem.
- Early efforts were trying to solve the dependency problem with sequential convolutions for a solution to the RNN. A long sequence is taken and the convolutions are applied. The disadvantage is that CNN approaches require many layers to capture long-term dependencies in the sequential data structure, without ever succeeding or making the network so large that it would eventually become impractical.
- The Transformer presents a new approach, it proposes to encode each word and apply the mechanism of attention in order to connect two distant words, then the decoder predicts the sentences according to all the words preceding the current word. This workflow can be parallelized, accelerating learning and solving the long-term dependencies problem.
Is there a way to train a Large Language Model (LLM) to store a specific context?
The only way at the moment to "memorize" past conversations is to include past conversations in the prompt.
Consider:
You are a friendly support person. The customer will ask you questions, and you will provide polite responses
Q: My phone won't start. What do I do? <-- This is a past question
A: Try plugging your phone into the charger for an hour and then turn it on. The most common cause for a phone not starting is that the battery is dead.
Q: I've tried that. What else can I try? <-- This is a past question
A: Hold the button for 15 seconds. It may need a reset.
Q: I did that. It worked, but the screen is blank. <-- This is a current question
A:
You will hit a token limit at some point (if you chat long enough). Each GPT-3 model has a maximum number of tokens you can pass to it. In the case of text-davinci-003, it is 4096 tokens. When you hit this limit, the OpenAI API will throw an error.
What Transfer learning Techniques can you use in LLMs?
There are several Transfer Learning techniques that are commonly used in LLMs. Here are three of the most popular:
- Feature-based transfer learning: This technique involves using a pre-trained language model as a feature extractor, and then training a separate model on top of the extracted features for the target task.
- Fine-tuning: involves taking a pre-trained language model and training it on a specific task. Sometimes when fine-tuning, you can keep the model weights fixed and just add a new layer that you will train. Other times you can slowly unfreeze the layers one at a time. You can also use unlabelled data when pre-training, by masking words and trying to predict which word was masked.
- Multi-task learning: involves training a single model on multiple related tasks simultaneously. The idea is that the model will learn to share information across tasks and improve performance on each individual task as a result.
What is Transfer Learning and why is it important?
A pre-trained model, such as GPT-3, essentially takes care of massive amounts of hard work for the developers: It teaches the model to do a basic understanding of the problem and provides solutions in a generic format.
With transfer learning, given that the pre-trained models can generate basic solutions, we can transfer the learning to another context. As a result, we will be able to customize the model to our requirements using fine-tuning without the need to retrain the entire model.
What's the difference between Encoder vs Decoder models?
Encoder models:
- They use only the encoder of a Transformer model. At each stage, the attention layers can access all the words in the initial sentence.
- The pretraining of these models usually revolves around somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence.
- They are best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more general word classification), and extractive question answering.
Decoder models:
- They use only the decoder of a Transformer model. At each stage, for a given word the attention layers can only access the words positioned before it in the sentence.
- The pretraining of decoder models usually revolves around predicting the next word in the sentence.
- They are best suited for tasks involving text generation.
What's the difference between Wordpiece vs BPE?
WordPiece and BPE are both subword tokenization algorithms. They work by breaking down words into smaller units, called subwords. We then define a desired vocabulary size and keep adding subwords till the limit is reached.
- BPE starts with a vocabulary of all the characters in the training data. It then iteratively merges the most frequent pairs of characters until the desired vocabulary size is reached. The merging is done greedily, meaning that the most frequent pair of characters is always merged first.
- WordPiece also starts with a vocabulary of all the characters in the training data. It then uses a statistical model to choose the pair of characters that is most likely to improve the likelihood of the training data until the vocab size is reached.
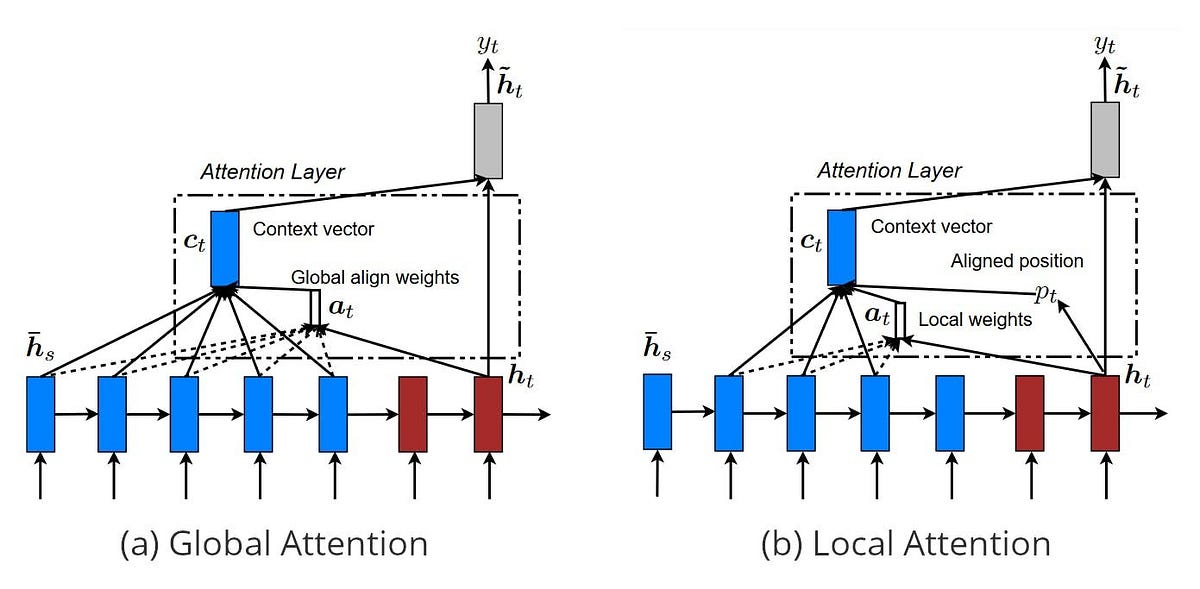
What's the difference between Global and Local Attention in LLMs?
Consider the example sentence "Where is Wally" which should be translated to its Italian counterpart "Dove è Wally". In the transformer architecture, the encoder processes the input word by word, producing three different hidden states.
Then, the attention layer produces a single fixed-size context vector from all the encoder hidden states (often with a weighted sum) and it represents the "attention" that must be given to that context when processing such input word. Here is when global and local attention comes into play.
Global attention considers all the hidden states in creating the context vector. When is applied, a lot of computation occurs. This is because all the hidden states must be taken into consideration, concatenated into a matrix, and processed by a NN to compute their weights.
On the other hand, local attention considers only a subset of all the hidden states in creating the context vector. The subset can be obtained in many different ways, such as with Monotonic Alignment and Predictive Alignment.
What's the difference between next-token-prediction vs masked-language-modeling in LLM?
Both are techniques for training large language models and involve predicting a word in a sequence of words.
-
Next token prediction: the model is given a sequence of words with the goal of predicting the next word. For example, given the phrase Hannah is a ____, the model would try to predict:
-
Hannah is a sister
-
Hannah is a friend
-
Hannah is a marketer
-
Hannah is a comedian
-
Masked-language-modeling: the model is given a sequence of words with the goal of predicting a masked word in the middle. For example, given the phrase, Jako mask reading, the model would try to fill the gap as,
-
Jacob fears reading
-
Jacob loves reading
-
Jacob enjoys reading
-
Jacon hates reading
Why a Multi-Head Attention mechanism is needed in a Transformer-based Architecture?
Take for example the sentence:
Bark is very cute and he is a dog.
Here, if we take the word ‘dog’, grammatically we understand that the words ‘Bark’, ‘cute’, and ‘he’ should have some significance or relevance with the word ‘dog’. These words say that the dog’s name is Bark, it is a male dog, and that he is a cute dog.
In simple terms, just one attention mechanism may not be able to correctly identify these three words as relevant to ‘dog’, and we can sense that three attentions are better here to signify the three words with the word ‘dog’.
Therefore, to overcome some of the pitfalls of using single attention, multi-head attention is used. This reduces the load on one attention to find all significant words and also increases the chances of finding more relevant words easily.
Why would you use Encoder-Decoder RNNs vs plain sequence-to-sequence RNNs for automatic translation?
A plain sequence-to-sequence RNN would start translating a sentence immediately after reading the first word of a sentence, while an Encoder-Decoder RNN will first read the whole sentence and then translate it.
In general, if you translate a sentence one word at a time, the result will be terrible. For example, the french sentence "Je vous en prie" means "You are welcome" but if you translate it one word at a time using plain sequence-to-sequence RNN, you get "I you in pray" which it does not have sense. So in automatic translation cases is much better to use Encoder-Decoder RNNs to read the whole sentence first and then translate it.
Explain what is Self-Attention mechanism in the Transformer architecture?
We can think of self-attention as a mechanism that enhances the information content of an input embedding by including information about the input’s context. In other words, the self-attention mechanism enables the model to weigh the importance of different elements in an input sequence and dynamically adjust their influence on the output.
Imagine that we have a text x, which we convert from raw text using an embedding algorithm. To then apply the attention, we map a query (q) as well as a set of key-value pairs (k, v) to our output x. Both q, k, as well as v, are vectors. The result z is called the attention-head and is then sent along a simple feed-forward neural network.
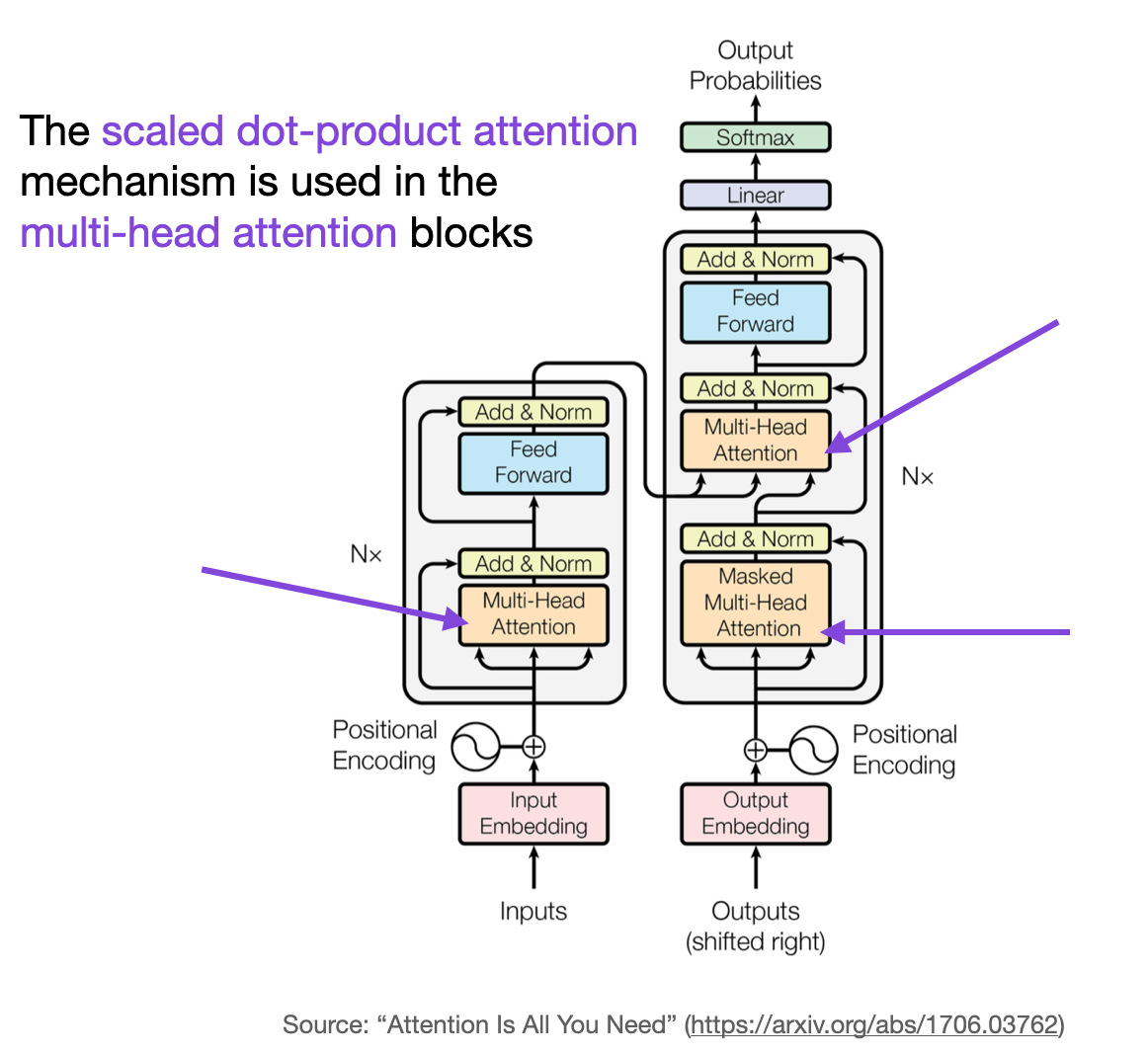
How does Transfer Learning work in LLMs?
Transfer learning in LLMs involves training a language model on a large corpus of text, and then fine-tuning the model on a specific task. The process involves several steps:
-
Pre-training: In this step, the language model is trained on a large corpus of text to learn the patterns and relationships within the language. The goal of pre-training is to generate a set of general-purpose language representations that can be used for a wide range of NLP tasks.
-
Fine-tuning: Once the language model is pre-trained, it can be fine-tuned on a specific NLP task, such as sentiment analysis or text classification. Fine-tuning involves taking the pre-trained model and training it on a smaller dataset specific to the target task. The goal of fine-tuning is to adapt the general-purpose language representations to the specific task at hand.
-
Inference: Once the model is fine-tuned, it can be used to make predictions on new data. During inference, the model takes in the input text and generates an output that represents the model’s prediction for the task at hand.

How does an LLM parameter relate to a weight in a Neural Network?
Yes, the parameters in a large language model (LLM) are similar to the weights in a standard neural network. In both LLMs and neural networks, these parameters are numerical values that start as random coefficients and are adjusted during training to minimize loss. These parameters include not only the weights that determine the strength of connections between neurons but also the biases, which affect the output of neurons. In a large language model (LLM) like GPT-4 or other transformer-based models, the term "parameters" refers to the numerical values that determine the behavior of the model. These parameters include weights and biases, which together define the connections and activations of neurons within the model. Here's a more detailed explanation:
- Weights: Weights are numerical values that define the strength of connections between neurons across different layers in the model. In the context of LLMs, weights are primarily used in the attention mechanism and the feedforward neural networks that make up the model's architecture. They are adjusted during the training process to optimize the model's ability to generate relevant and coherent text.
- Biases: Biases are additional numerical values that are added to the weighted sum of inputs before being passed through an activation function. They help to control the output of neurons and provide flexibility in the model's learning process. Biases can be thought of as a way to shift the activation function to the left or right, allowing the model to learn more complex patterns and relationships in the input data.
The training process involves adjusting these parameters (weights and biases) iteratively to minimize the loss function. This is typically done using gradient descent or a variant thereof, such as stochastic gradient descent or Adam optimizer. The loss function measures the difference between the model's predictions and the true values (e.g., the correct next word in a sentence). By minimizing the loss, the model learns to generate text that closely resembles the patterns in its training data.
Researchers often use the term "parameters" instead of "weights" to emphasize that both weights and biases play a crucial role in the model's learning process.
What are some downsides of fine-tuning LLMs?
- Fine-tuning requires manually creating tons of data, and the model may memorize portions of the data you provide.
- Every time you want to add a new capability, instead of adding a few lines to a prompt, you need to create a bunch of fake data and then run the finetune process and then use the newly fine-tuned model.
- It is more expensive.
What is the difference between Word Embedding, Position Embedding and Positional Encoding in BERT?
- A Word embedding is a learned lookup map i.e. every word is given a one hot encoding which then functions as an index, and the corresponding to this index is a
ndimensional vector where the coefficients are learned when training the model. - A Positional embedding is similar to a word embedding. Except it is the position in the sentence is used as the index, rather than the one hot encoding. Those positions then correspond to a
n-vector whose coefficients come from the trained model. - On the other hand, the Positional encoding is a static function that maps an integer input to real-valued vectors in a way that captures the inherent relationships among the positions. That is, it captures the fact that position
4in input is more closely related to position5than it is to position17. In other words, positional encoding is not learned but a chosen mathematical function,N -> R^n.
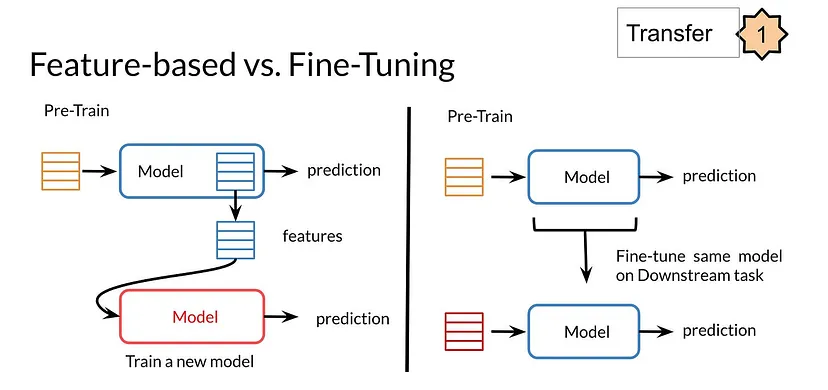
What’s the difference between Feature-based Transfer Learning vs. Fine Tuning in LLMs?
- In Feature-based Transfer Learning, you can train word embeddings by running a model
Aand then using those features from modelA(i.e. word vectors) on a different task, or modelB. - When Fine Tuning, you can use the exact same model
Aand just run it on a different task. Sometimes when fine-tuning, you can keep the model weights fixed and just add a new layer that you will train. Other times you can slowly unfreeze the layers one at a time. You can also use unlabelled data when pre-training, by masking words and trying to predict which word was masked.
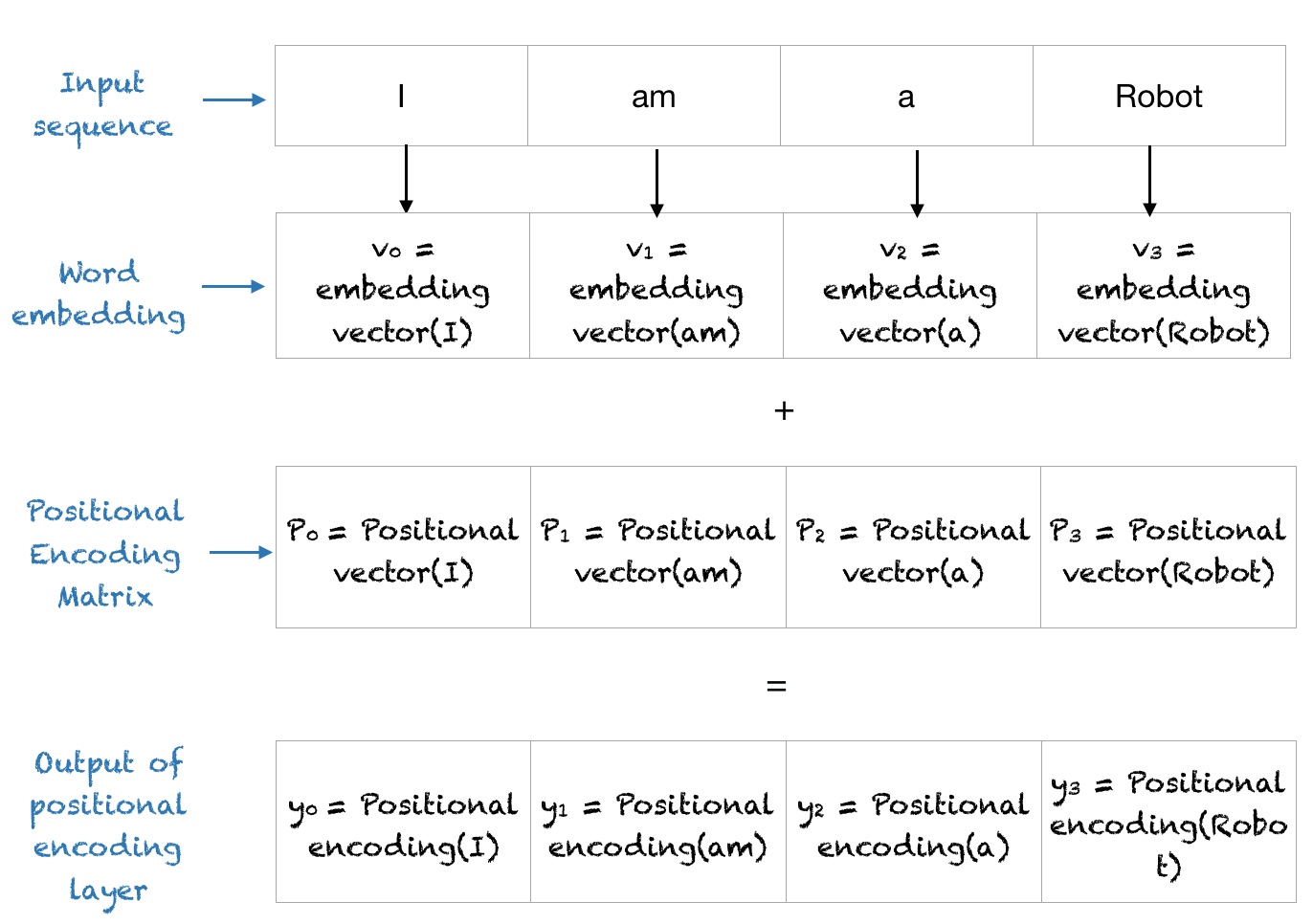
Why do transformers need Positional Encodings?
Consider the input sentence - "I am good".
In RNNs, we feed the sentence to the network word by word. That is, first the word "I" is passed as input, next the word "am" is passed, and so on. We feed the sentence word by word so that our network understands the sentence completely.
But with the transformer network, we don't follow the recurrence mechanism. So, instead of feeding the sentence word by word, we feed all the words in the sentence parallel to the network. Feeding the words in parallel helps in decreasing the training time and also helps in learning the long-term dependency.
When we feed the words parallel to the transformer, the word order (position of the words in the sentence) is important. So, we should give some information about the word order to the transformer so that it can understand the sentence.
If we pass the input matrix directly to the transformer, it cannot understand the word order. So, instead of feeding the input matrix directly to the transformer, we need to add some information indicating the word order (position of the word) so that our network can understand the meaning of the sentence. To do this, we introduce a technique called positional encoding. Positional encoding, as the name suggests, is an encoding indicating the position of the word in a sentence (word order).
What's the difference between Monotonic alignment and Predictive alignment in transformers?
What is OpenAI GPT model temperature?
Temperature is a parameter of OpenAI ChatGPT, GPT-3 and GPT-4 models that governs the randomness and thus the creativity of the responses.
It is always a number between 0 and 1. A temperature of 0 means the responses will be very straightforward, almost deterministic (meaning you almost always get the same response to a given prompt) A temperature of 1 means the responses can vary wildly.
How exactly does the temperature work?
Under the hood, large language models try to predict the next best word given a prompt. One word at a time. They assign a probability to each word in their vocabulary, and then picks a word among those.
A temperature of 0 means roughly that the model will always select the highest probability word. A higher temperature means that the model might select a word with slightly lower probability, leading to more variation, randomness and creativity. A very high temperature therefore increases the risk of "hallucination", meaning that the AI starts selecting words that will make no sense or be offtopic.
Since all characters count, the ratio of words to tokens is language dependent.
Rules of thumb for temperature choice
Your choice of temperature should depend on the task you are giving GPT.
For transformation tasks (extraction, standardization, format conversion, grammar fixes) prefer a temperature of 0 or up to 0.3. For writing tasks, you should juice the temperature higher, closer to 0.5. If you want GPT to be highly creative (for marketing or advertising copy for instance), consider values between 0.7 and 1.
If you want to experiment and create many variations quickly, a high temperature is better.
How to use OpenAI GPT-3 temperature • Gptforwork.com
Flex processing - OpenAI Platform
- Flex processing provides significantly lower costs for Chat Completions or Responses requests in exchange for slower response times and occasional resource unavailability. It is ideal for non-production or lower-priority tasks such as model evaluations, data enrichment, or asynchronous workloads.
Topics
- token embeddings
- positional embeddings
- self-attention
- transformers
- intuitive understanding of Q, K, V
- causal and multi-head attention
- temperature, top-k, top-p
- classification & instruction fine-tuning
- rotary positional encoding (RoPE)
- KV Cache
- infini-attention (long context windows)
- mixture of experts (MoE)
- grouped query attention
- basic understanding of llama-2 architecture and techniques which is actually a recap of all the previous subjects