Context Engineering
Context engineering is rapidly becoming a crucial skill for AI engineers. It's no longer just about clever prompting; it's about the systematic orchestration of context.
Here’s the current problem:
Most AI agents (or LLM apps) fail not because the models are bad, but because they lack the right context to succeed.
For instance, a RAG workflow is typically 80% retrieval and 20% generation.

Thus:
- Good retrieval could still work with a weak LLM.
- But bad retrieval can NEVER work with even with the best of LLMs.
If your RAG isn't working, most likely, it's a context retrieval issue.
In the same way, LLMs aren't mind readers. They can only work with what you give them.
Context engineering involves creating dynamic systems that offer:
- The right information
- The right tools
- In the right format
This ensures the LLM can effectively complete the task.
But why was traditional prompt engineering not enough?
Prompt engineering primarily focuses on “magic words” with an expectation of getting a better response.
But as AI applications grow complex, complete and structured context matters far more than clever phrasing.

These are the 4 key components of a context engineering system:
- Dynamic information flow: Context comes from multiple sources: users, previous interactions, external data, and tool calls. Your system needs to pull it all together intelligently.
- Smart tool access: If your AI needs external information or actions, give it the right tools. Format the outputs so they're maximally digestible.
- Memory management:
- Short-term: Summarize long conversations
- Long-term: Remember user preferences across sessions
- Format optimization: A short, descriptive error message beats a massive JSON blob every time.
Context engineering is becoming the new core skill since it addresses the real bottleneck, which is not model capability, but setting up an architecture of information.
Providing Context
6 ways to provide context to AI Agents
INSTRUCTIONS - Set the stage clearly
- Who: Give your AI a role ("Act as a senior developer")
- Why: Explain the bigger picture and business value
- What: Define success criteria and expected outcomes
REQUIREMENTS - The "how-to" blueprint
- Step-by-step processes
- Style guidelines and coding standards
- Performance constraints and security requirements
- Response formats (JSON, plain text, etc.)
- Examples of what TO do and what NOT to do
- Pro tip: Negative examples are gold for fixing common mistakes!
KNOWLEDGE - Feed your AI the right information
- External context: Industry knowledge, business models, market facts
- Task context: Workflows, documentation, structured data
- Think of it as giving your AI a comprehensive briefing
MEMORY - Enable your AI to remember
- Short-term: Chat history, current reasoning steps
- Long-term: User preferences, past experiences, learned procedures
- Note: Memory isn't just prompt text—it's managed by your orchestration layer
TOOLS - Describe available functions clearly
- What each tool does
- How to use it properly
- Expected parameters and return values
- Remember: Tool descriptions are micro-prompts that guide AI reasoning!
TOOL RESULTS - The feedback loop
- AI requests tool execution in special format
- System responds with results
- AI continues with enriched context
My opinion: Context engineering is no longer optional, it's a key pillar in building reliable AI agents.
Context Engineering is the secret to reliable AI Agents | Om Nalinde | 52 comments
The RIGHT Method for Context Engineering (+3 Advanced Techniques) - YouTube
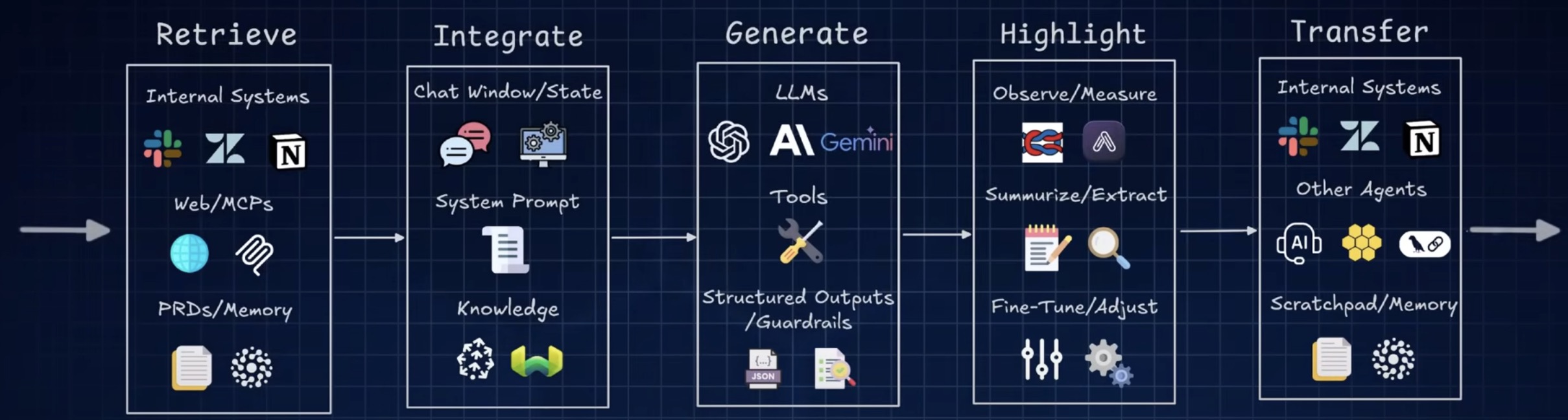
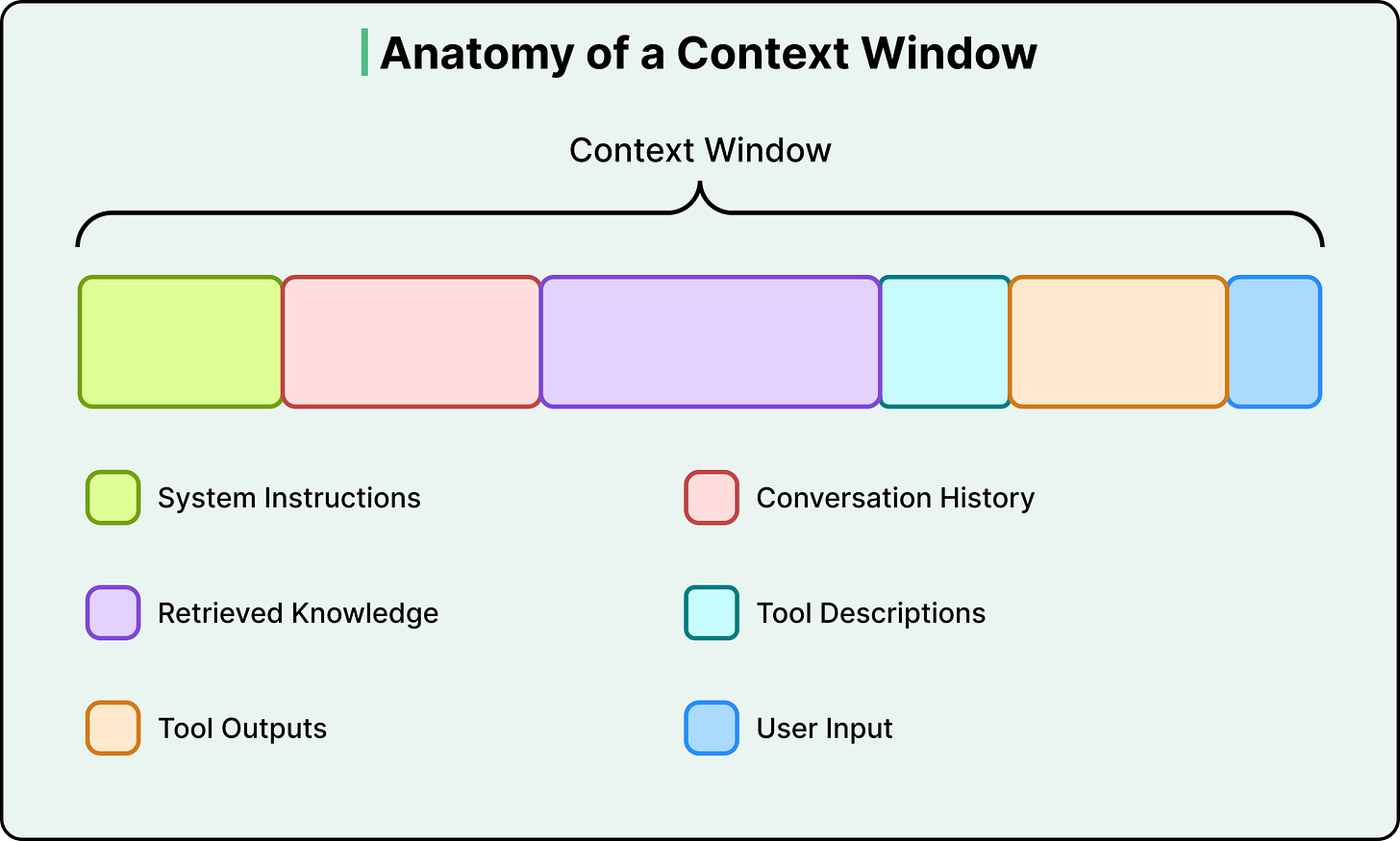
Core Strategies
Developers have converged on four broad strategies for managing context, categorized as write, select, compress, and isolate. Each one is a direct response to a specific constraint we’ve already covered.
Write: Save Context Externally
The constraint it addresses is that the context window is finite, and statelessness means information is lost between calls.
Instead of trying to keep everything inside the context window, save important information to external storage and bring it back when needed. This takes two main forms.
- The first is scratchpads, where an agent saves intermediate plans, notes, or reasoning steps to external storage during a long-running task. Anthropic’s multi-agent research system does exactly this. The lead researcher agent writes its plan to external memory at the start of a task, because if the context window exceeds 200,000 tokens, it gets truncated and the plan would be lost.
- The second form is long-term memory, which involves persisting information across sessions. ChatGPT auto-generates user preferences from conversations, Cursor and Windsurf learn coding patterns and project context, and Claude Code uses CLAUDE.md files as persistent instruction memory. All of these systems treat external storage as the real memory layer, with the context window serving as a temporary workspace.
Select: Pull In Only What’s Relevant
The constraint it addresses is that more context isn’t better, and the model needs the right information rather than all available information.
The most important technique here is Retrieval-Augmented Generation, or RAG. Instead of stuffing all your knowledge into the context window, we store it externally in a searchable database. At query time, retrieve only the chunks most relevant to the current question and inject those into the context, giving the model targeted knowledge without the noise of everything else.
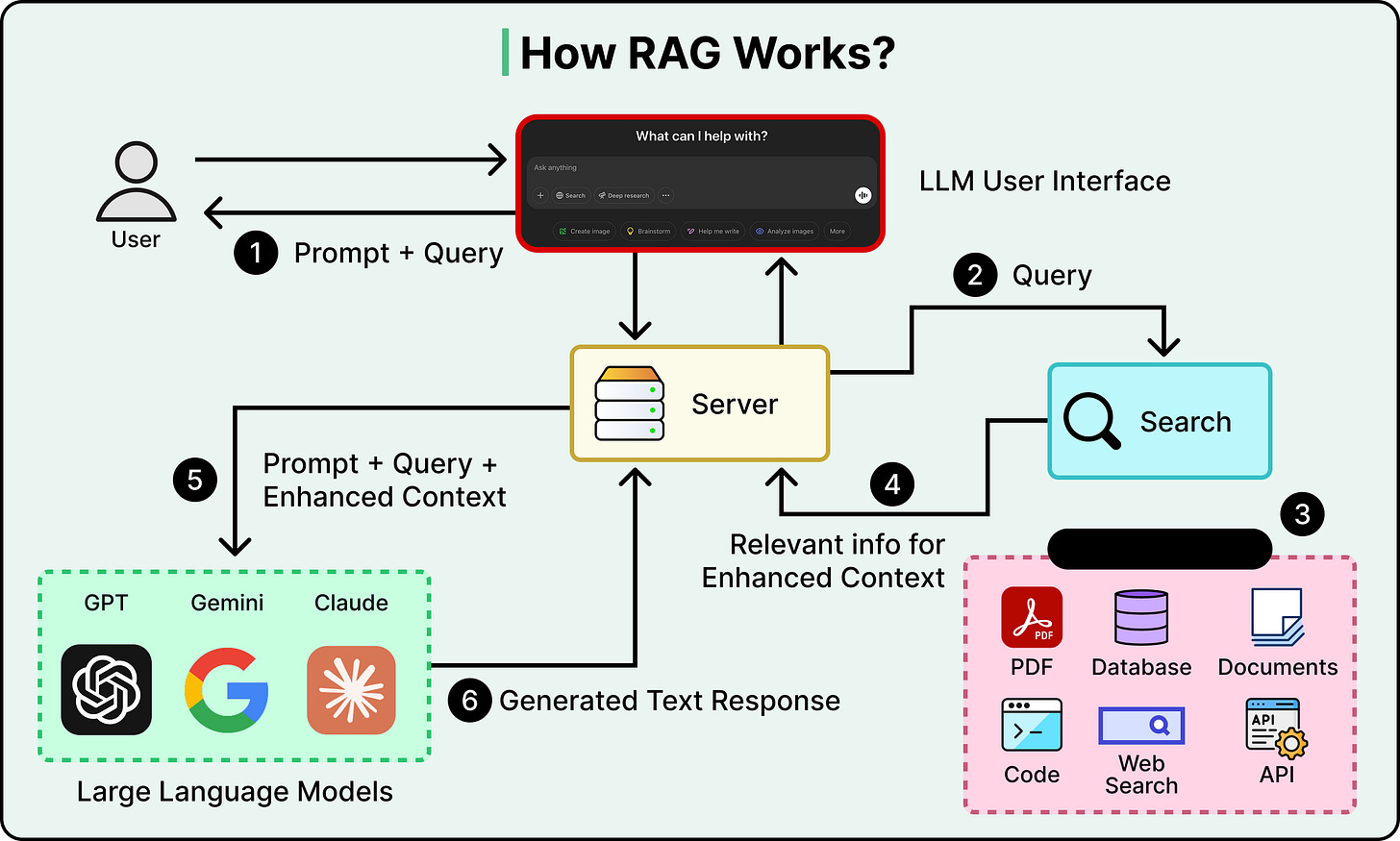
Selection also applies to tools. When an agent has dozens of available tools, listing every tool description in every prompt wastes tokens and confuses the model. A better approach is to retrieve only the tool descriptions relevant to the current task.
The critical tradeoff with selection is precision. If the retrieval pulls in documents that are almost relevant but not quite, they become distractors that add tokens and push important context into low-attention zones. The retrieval step itself has to be good, or the whole strategy backfires.
Compress: Keep Only What You Need
The constraint it addresses is the context rot and the escalating cost of attention across more tokens.
As agent workflows span dozens or hundreds of steps, the context window fills up with accumulated conversation history and tool outputs. Compression strategies reduce this bulk while trying to preserve the essential information.
Conversation summarization is the most common approach. Claude Code, for instance, triggers an “auto-compact” process when the context hits 95% capacity, summarizing the entire interaction history into a shorter form. Cognition, the company behind the Devin coding agent, trained a separate, dedicated model specifically for summarization at agent-to-agent boundaries. The fact that they built a separate model just for this step tells us how consequential bad compression can be, since a specific decision or detail that gets summarized away is gone permanently.
Simpler forms of compression include trimming (removing older messages from the history) and tool output compression (reducing verbose search results or code outputs to their essentials before they enter the context).
Isolate: Split Context Across Agents
The constraint it addresses is that of attention dilution and context poisoning when too many types of information compete in one window.
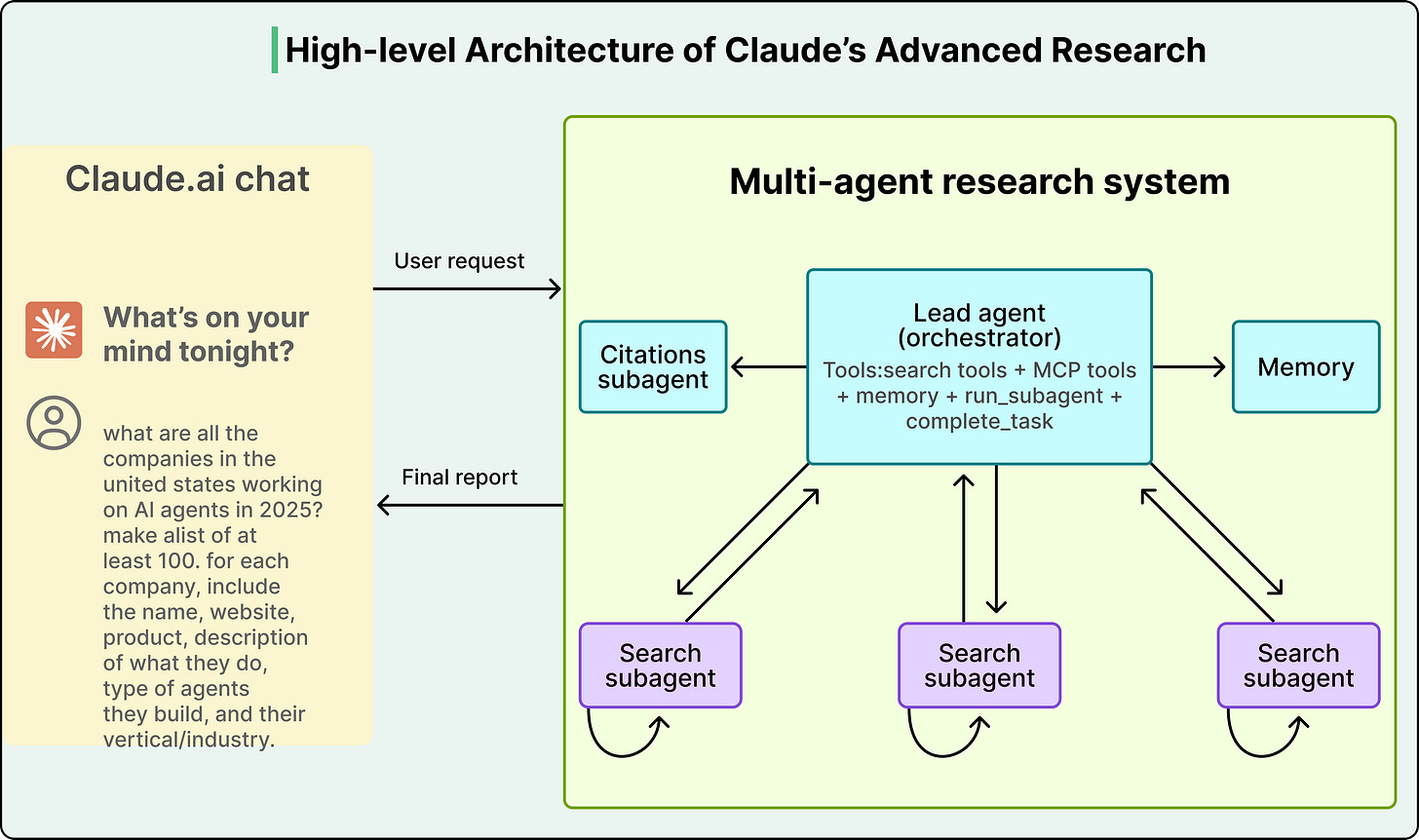
Instead of one agent trying to handle everything in a single bloated context window, this strategy splits the work across multiple specialized agents, each with its own clean, focused context. A “researcher” agent gets a context loaded with search tools and retrieved documents, while a “writer” agent gets a context loaded with style guides and formatting rules, so neither is distracted by the other’s information.
Anthropic demonstrated this with their multi-agent research system, where a lead Opus 4 agent delegated sub-tasks to Sonnet 4 sub-agents. The system achieved a 90.2% improvement over a single Opus 4 agent on research tasks, despite using the same underlying model family. The entire performance gain came from how context was managed, not from a more powerful model.
Tradeoffs
These strategies are powerful, but they involve trade-offs with no universal right answers:
- Compression versus information loss: Every time you summarize, you risk losing a detail that turns out to matter later. The more aggressively you compress, the more you save on tokens, but the higher the chance of permanently destroying something important.
- Single agent versus multi-agent: Anthropic’s multi-agent results are impressive, but others, notably Cognition, have argued that a single agent with good compression delivers more stability and lower cost. Both sides are debating the same core question of how to manage context effectively, and the answer depends on task complexity, cost tolerance, and reliability requirements.
- Retrieval precision versus noise: RAG adds knowledge, but imprecise retrieval adds distractors. If the documents you retrieve aren’t genuinely relevant, they consume tokens and push important content into low-attention positions, so the retrieval system itself has to be well-engineered, or RAG makes things worse.
- Cost versus richness: Every token costs money and processing time. The disproportionate scaling of attention means longer contexts get expensive fast, and context engineering is partly an economics problem of figuring out where the return on additional tokens stops being worth the cost.
Advanced Context Engineering Methods
- Async Context Synchronization
- Agentic Scratchpad Updates
- Multi-Agent Context