Kafka Schema Registry Overview
https://www.confluent.io/blog/schemas-contracts-compatibility
Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas. It stores a versioned history of all schemas, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility settings and expanded Avro support. It provides serializers that plug into Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format.
Schema Registry is a distributed storage layer for Avro Schemas which uses Kafka as its underlying storage mechanism. Some key design decisions:
- Assigns globally unique ID to each registered schema. Allocated IDs are guaranteed to be monotonically increasing but not necessarily consecutive.
- Kafka provides the durable backend, and functions as a write-ahead changelog for the state of Schema Registry and the schemas it contains.
- Schema Registry is designed to be distributed, with single-master architecture, and ZooKeeper/Kafka coordinates master election (based on the configuration).
# to change the compatibility of schema-registry
docker exec schema-registry curl -X PUT -H "Content-Type: application/vnd.schemaregistry.v1+json" \
--data '{"compatibility": "NONE"}' \
http://schema-registry:8081/config
In Apache Kafka®, data is produced and consumed as messages with structured formats called schemas. As more consumers start reading from topics—sometimes written by different teams or even entirely separate departments—it's crucial that they understand the schema of the data they're receiving. Over time, schemas evolve—fields may be added, data types may change, and new versions are introduced. To manage these changes seamlessly and prevent breaking consumers, Kafka relies on the Confluent Schema Registry.
What is the Confluent Schema Registry?
The Schema Registry is a standalone server that stores and manages schemas for Kafka topics. It’s not part of Apache Kafka itself but is widely adopted as a community-licensed component by Confluent. To Kafka, it just looks like another application producing and consuming messages, but its purpose is specific: it maintains a database of schemas for topics it monitors. This database is internally stored in a Kafka topic, ensuring high availability and durability.
Generally a Schema Registry cluster can include multiple tenants and each tenant can include multiple contexts. Schema IDs are unique within a (tenant, context) combination. For Confluent Platform Schema Registry you will only have one tenant, so IDs will be unique within a context. Considering the tenant/context combination as the realm in which schemas reside, schema IDs are unique within this “world”; that is, globally unique.
How Does It Work?
When a producer sends a message, it first contacts the Schema Registry through its REST API to register the schema if it’s new. The producer then includes the schema ID in the message before sending it to the Kafka topic. This ID allows consumers to look up the schema when they receive the message, ensuring they know how to deserialize and interpret it correctly.
On the consumer side, the consumer checks the schema ID from the message against the Schema Registry. If the schema matches what it expects, it proceeds to consume the data. If not, the consumer can throw an exception, signaling that it can't process that version of the schema. This mechanism prevents consumers from breaking when message formats change unexpectedly.
At its core, Schema Registry has two main parts:
- A REST service for validating, storing, and retrieving Avro, JSON Schema, and Protobuf schemas
- Serializers and deserializers that plug into Apache Kafka® clients to handle schema storage and retrieval for Kafka messages across the three formats
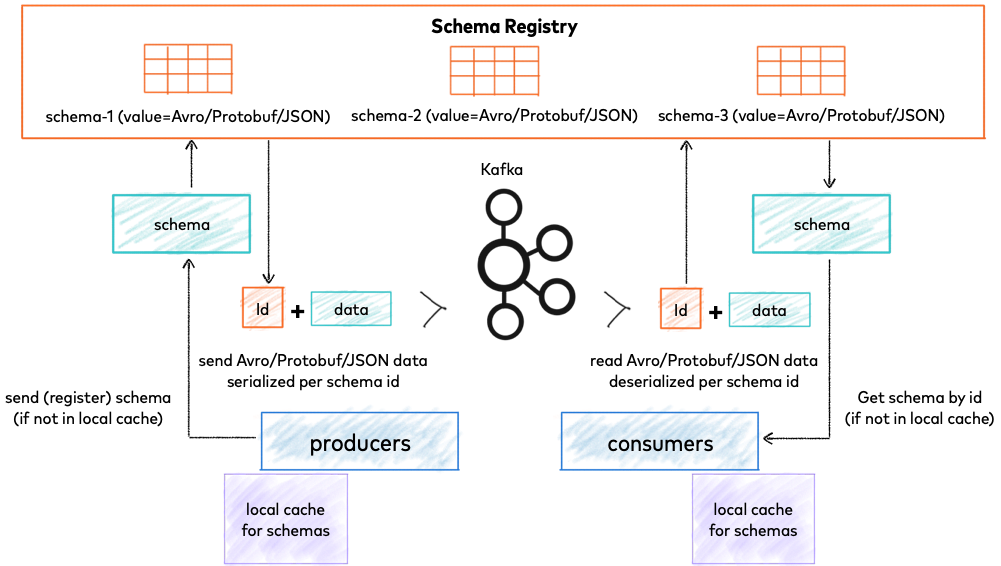
Schema Registry Calls
A Kafka producer calls the Schema Registry once per unique message type (schema), not for every single message, to register or fetch its ID, then caches it. It checks if the schema exists, registers it (if new), gets a unique ID, serializes the data with that ID, and sends it to Kafka, ensuring efficient communication and version control for all messages of that type.
When the Producer Calls the Registry:
- First Time: When the producer first tries to send a message with a specific schema (e.g., a new user registration), it calls the registry to check for and register that schema.
- Schema Version Change: If the application updates the schema (adds a field, changes a type), it calls the registry to register the new version of the schema, triggering compatibility checks.
What Happens Next:
- Caching: The Schema Registry returns a unique ID for that schema, and the producer caches it locally.
- Serialization: For subsequent messages using the same schema, the producer uses the cached ID to prepend to the message payload, skipping the registry call.
- Data Flow: The message sent to Kafka contains the schema ID (e.g., in the header) and the serialized data, allowing consumers to retrieve the correct schema from the registry to deserialize it.
In short, it's a "call once, use many times" pattern for each distinct data contract (schema), making it highly efficient.
Serialization Formats
Schema Registry supports three major serialization formats:
- Avro – Highly compact and widely used with Kafka.
- JSON Schema – Human-readable, great for web applications.
- Protobuf – Efficient and language-neutral, popular with gRPC services.
For Avro, the schema is typically defined in an AVSC file (Interface Description Language). The Schema Registry uses this to validate messages, ensuring producers only write data that fits the schema and consumers read it correctly.
Why Schema Registry is Essential
In any non-trivial system, the Schema Registry is indispensable. As applications grow, new consumers emerge, and schemas inevitably evolve. The Schema Registry provides:
- Centralized schema management – All producers and consumers share a common understanding of message formats.
- Compatibility enforcement – Prevents breaking changes by validating schemas during production and consumption.
- Governance and collaboration – Teams can negotiate schema changes safely, using IDL files as a shared contract.
- Compile-time checks – You can verify compatibility before deploying code, avoiding runtime surprises.
Common data problems solved by Schema Registry
Schema Registry solves the following common problems of working with large scale data systems:
- Data inconsistency: A registry ensures that all system data adheres to agreed upon schemas. This reduces risk of data inconsistency and increases data quality.
- Incompatible data formats: With multiple data producers and consumers, different applications may use different data formats. Schema Registry solves this problem by providing centralized schema management and validation, to ensure that all message data is compatible.
- Schema evolution: Schemas often change over time, which can cause compatibility issues between different versions of the schema. Schema Registry supports schema versioning, ensuring that different versions of the schema can be used simultaneously without causing compatibility issues.
- Schema ID validation: Schema Registry checks that data produced to a topic is using a valid schema ID in Schema Registry. This ensures that data conforms to a standard format, reducing risk of data loss or corruption.
- Data governance: Schema Registry a central location to manage and version data schemas. This simplifies governance by enabling easy tracking of schema changes, maintaining schema evolution history, and ensuring data compliance with regulatory requirements.
Confluent Schema Registry: Enforcing Data Contracts in Kafka
Schema Registry Concepts for Confluent Platform | Confluent Documentation
Advanced / Best Practices
Understand schema deletion
Schemas are intended to be immutable. This is because messages can be stored for an arbitrarily long time, so consumers in the future need to know exactly what schema was used by the producer at the time of serialization. This also explains why a new schema version is created instead of overwriting the previous version, whenever a schema is registered to a subject.
A schema can be soft-deleted, which has the effect of making it unavailable for producers when serializing messages. However, it is still available for consumers to deserialize messages.
A schema can also be hard-deleted, which removes it completely from Schema Registry, making it unavailable for both producers and consumers. Hard-deleting a schema is an irreversible operation that should only be done if you are absolutely certain that you no longer need the schema to deserialize messages.
Don't mutate schemas
Even though schemas are intended to be immutable, you can mutate a schema if absolutely necessary. For example, you may want to add a metadata property, such as "major_version", to an existing schema. Or you may want to restore a hard-deleted schema. However, it's not recommended to mutate schemas, as if not done correctly, you could easily corrupt your schemas, causing your clients to fail.
If you find that you have no other option, first you would need to hard delete the schema that you want to overwrite. If the schema exists in more than one subject, you'll need to hard delete each subject-version pair. Then you would force a subject into IMPORT mode using the following command:
PUT /mode/{subject}?force=true
{
"mode": "IMPORT"
}
Next, you would register your new schema to Schema Registry, while specifying the exact schema ID and version to use.
POST /subjects/{subject}/versions
{
"id": {id},
"version" {version},
"schema": "...",
"schemaType": "...",
"references": ["..."]
}
Finally, you may need to restart any clients to pick up the mutated schema, since clients don't expect schemas to change and therefore cache them for reuse.
Schema Registry Best Practices
Schema Registry Commands
# Register a new version of a schema under the subject "Kafka-key"
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
http://localhost:8081/subjects/Kafka-key/versions
{"id":1}
# Register a new version of a schema under the subject "Kafka-value"
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
http://localhost:8081/subjects/Kafka-value/versions
{"id":1}
# List all subjects
curl -X GET http://localhost:8081/subjects
["Kafka-value","Kafka-key"]
# List all schema versions registered under the subject "Kafka-value"
curl -X GET http://localhost:8081/subjects/Kafka-value/versions
[1]
# Fetch a schema by globally unique id 1
curl -X GET http://localhost:8081/schemas/ids/1
{"schema":""string""}
# Fetch version 1 of the schema registered under subject "Kafka-value"
curl -X GET http://localhost:8081/subjects/Kafka-value/versions/1
{"subject":"Kafka-value","version":1,"id":1,"schema":""string""}
# Fetch the most recently registered schema under subject "Kafka-value"
curl -X GET http://localhost:8081/subjects/Kafka-value/versions/latest
{"subject":"Kafka-value","version":1,"id":1,"schema":""string""}
# Delete version 3 of the schema registered under subject "Kafka-value"
curl -X DELETE http://localhost:8081/subjects/Kafka-value/versions/3
3
# Delete all versions of the schema registered under subject "Kafka-value"
curl -X DELETE http://localhost:8081/subjects/Kafka-value
[1, 2, 3, 4, 5]
# Check whether a schema has been registered under subject "Kafka-key"
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
http://localhost:8081/subjects/Kafka-key
{"subject":"Kafka-key","version":1,"id":1,"schema":""string""}
# Test compatibility of a schema with the latest schema under subject "Kafka-value"
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
http://localhost:8081/compatibility/subjects/Kafka-value/versions/latest
{"is_compatible":true}
# Get top level config
curl -X GET http://localhost:8081/config
{"compatibilityLevel":"BACKWARD"}
# Update compatibility requirements globally
curl -X PUT -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"compatibility": "NONE"}'
http://localhost:8081/config
{"compatibility":"NONE"}
# Update compatibility requirements under the subject "Kafka-value"
curl -X PUT -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"compatibility": "BACKWARD"}'
http://localhost:8081/config/Kafka-value
{"compatibility":"BACKWARD"}