Introduction to Apache Kafka
- Kafka Core is the distributed, durable equivalent of Unix pipes. Use it to connect and compose your large-scale data applications
- Kafka Streams are the commands of your Unix pipelines. Use it to transform data stored in Kafka
- Kafka Connect is the I/O redirection in your Unix pipelines. Use it to get your data into an out of Kafka.
Intro
- Open-source stream-processing software platform by Apache Software Foundation
- Written in Scala and Java
- Aims to provide - Unified, High-throughput, low-latency platform for handling real-time data feeds.
- Storage layer - massively scalable pub/sub message queue designed as a distributed transaction log (highly valuable for enterprise infrastructures to process streaming data)
- Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library
- Design is heavily influenced by transaction logs. (based on commit log)
- Fault tolerant highly available queue used in publisher-subscriber or streaming application
- It can deliver message exactly once and also it keeps all the messages ordered inside a partition of a topic
- Horizontally scalable, fault-tolerant, wicked fast
- Focuses on real-time analysis, not batch jobs
- Streams and streams only
- Except streams are also tables (sometimes)
- No cluster required
- Not just only a messaging framework but also a computation framework
Concepts
- Kafka is run as a cluster on one or more servers that can span multiple data-centers.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
APIs
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
Architecture
- Message: an immutable array of bytes
- Topic: a feed of messages
- Producer: a process that publishes messages to a topic
- Consumer: a single-threaded process that subscribes to a topic
- Broker: one of the servers that comprises a cluster
Characteristics
- It is a distributed and partitioned messaging system
- It is highly fault-tolerant
- It is highly scalable
- It can process and send millions of messages per second to several receivers
History
- Originally developed by LinkedIn and later, handed over to the open source community in early 2011
- It became a main Apache project in October, 2012
- A stable Apache Kafka version 0.8.2.0 was release in Feb, 2015.
Kafka Data Model
The Kafka data model consists of messages and topics
- Messages represent information such as, lines in a log file, a row of stock market data, or an error message from a system
- Messages are grouped into categories called topics. Example: LogMessage and Stock Message
- The processes that publish messages into a topic in Kafka are known as producers.
- The processes that receive the messages from a topic in Kafka are known as consumers.
- The processes or servers within Kafka that process the messages are known as brokers.
- A Kafka cluster consists of a set of brokers that process the messages
Types of messaging systems
- Kafka architecture supports the publish-subscribe and queue system
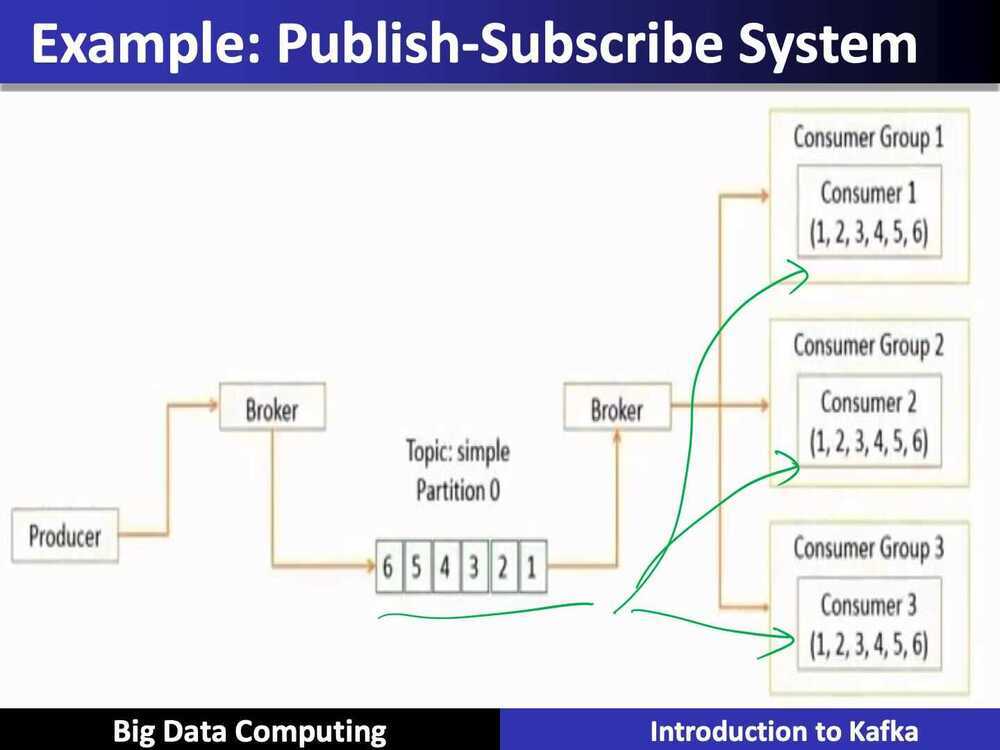
- Publish-subscribe system
- Each message is received by all the subscribers
- Each subscriber receives all the messages
- Messages are received in the same order that they are produced
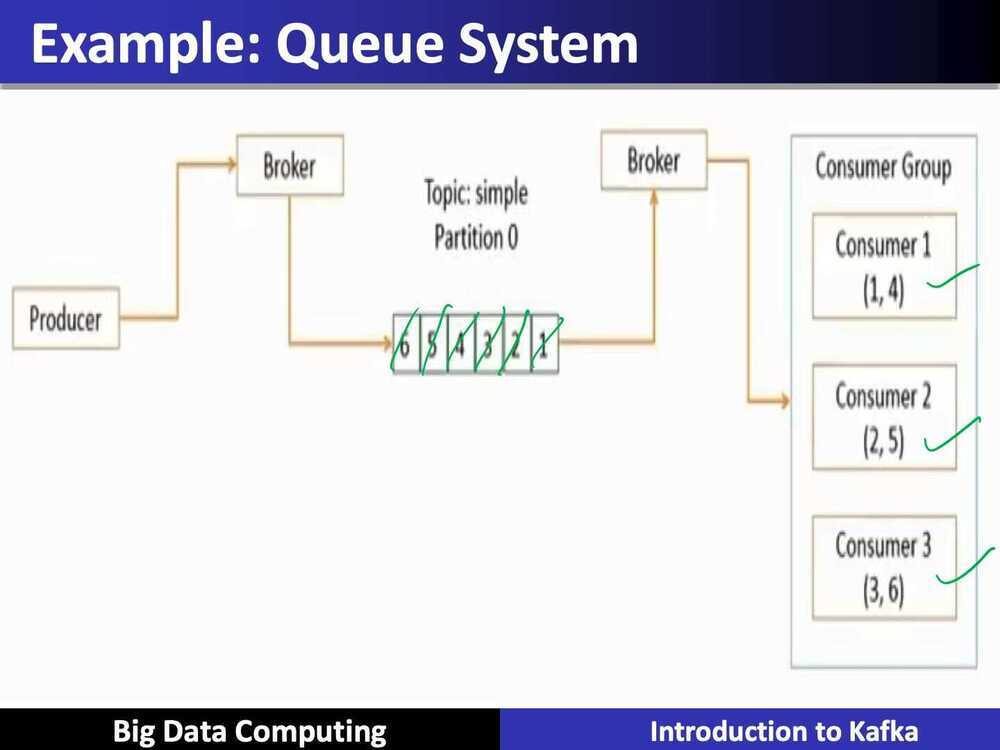
- Queue system
- Each message has to be consumed by only one consumer
- Each message is consumed by any one of the available consumers
- Messages are consumed in the same order that they are received
Brokers
Brokers are the Kafka processes that process the messages in Kafka
- Each machine in the cluster can run one broker
- They coordinate among each other using Zookeeper
- One broker acts as a leader for a partition and handles the delivery and persistence, where as, the others act as followers
Transactions in Kafka
- Atomic multi-partition writes
- Zombie fencing
Transactions in Apache Kafka | Confluent
Persistence in Kafka
Kafka uses the Linux file system for persistence of messages
- Persistence ensures no messages are lost
- Kafka relies on the file system page cache for fast reads and writes
- All the data is immediately written to a file in file system
- Messages are grouped as message sets for more efficient writes
- Message sets can be compressed to reduce network bandwidth
- A standarized binary message format is used among producers, brokers, and consumers to minimize data modification
3 major components
- Kafka Core: A central hub to transport and store event streams in real-time
- Kafka Connect: A framework to import event streams from other soure data systems into Kafka and export event streams from Kafka to destination data systems
- Kafka Streams: A Java library to process event streams live as they occur
Can Kafka lose messages?
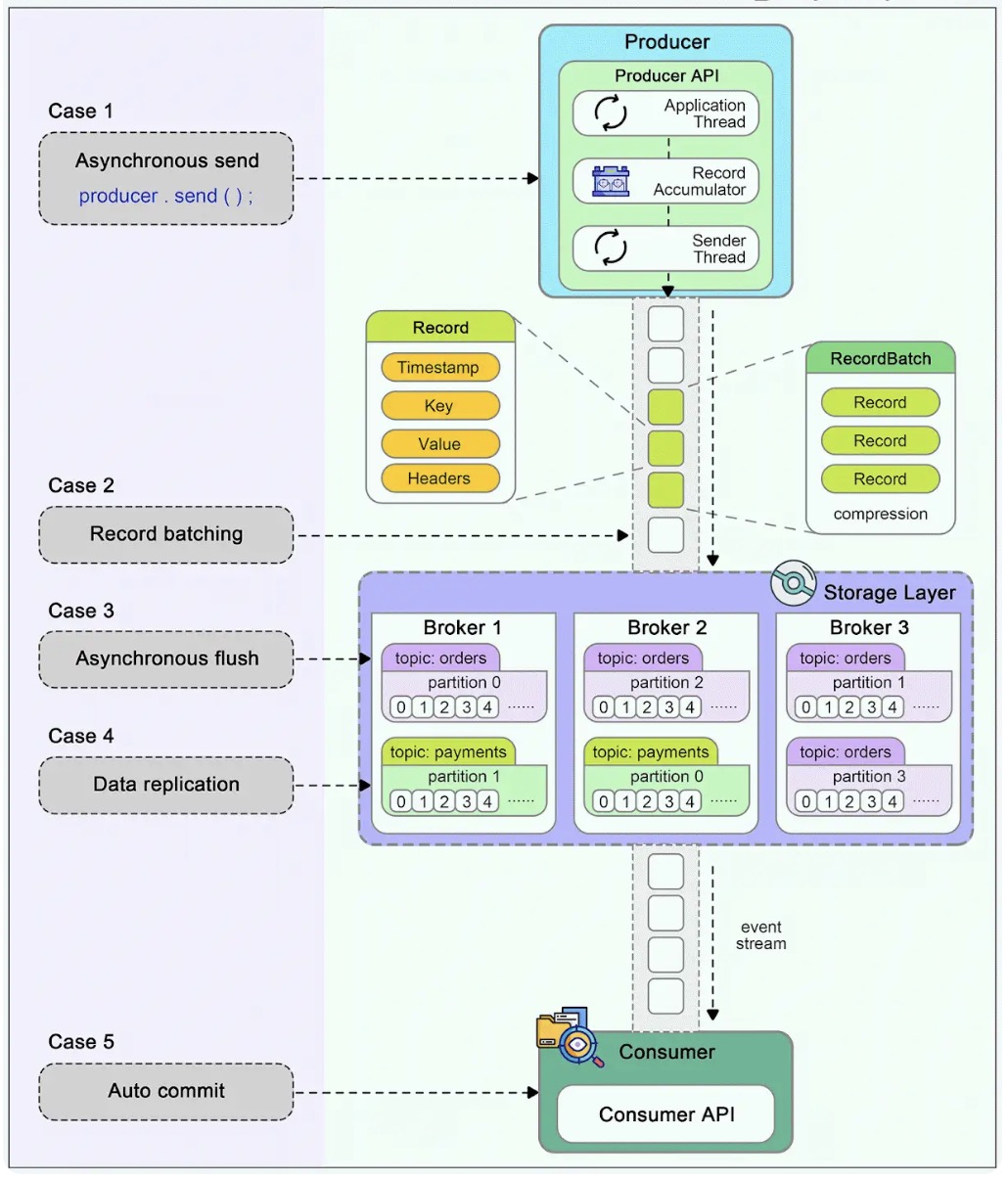
A common belief among many developers is that Kafka, by its very design, guarantees no message loss. However, understanding the nuances of Kafka's architecture and configuration is essential to truly grasp how and when it might lose messages, and more importantly, how to prevent such scenarios.
The diagram below shows how a message can be lost during its lifecycle in Kafka.
Producer
When we call producer.send() to send a message, it doesn't get sent to the broker directly. There are two threads and a queue involved in the message-sending process:
- Application thread
- Record accumulator
- Sender thread (I/O thread)
We need to configure proper ‘acks’ and ‘retries’ for the producer to make sure messages are sent to the broker.
Broker
A broker cluster should not lose messages when it is functioning normally. However, we need to understand which extreme situations might lead to message loss:
- The messages are usually flushed to the disk asynchronously for higher I/O throughput, so if the instance is down before the flush happens, the messages are lost.
- The replicas in the Kafka cluster need to be properly configured to hold a valid copy of the data. The determinism in data synchronization is important.
Consumer
Kafka offers different ways to commit messages. Auto-committing might acknowledge the processing of records before they are actually processed. When the consumer is down in the middle of processing, some records may never be processed.
A good practice is to combine both synchronous and asynchronous commits, where we use asynchronous commits in the processing loop for higher throughput and synchronous commits in exception handling to make sure the the last offset is always committed.
ISR
In-sync replicas is the subset of the replicas list that is currently alive and caught up-to the leader
Managed Services
- Confluent Cloud - Apache Kafka as a service - https://www.confluent.io/confluent-cloud
- AWS - Amazon Kinesis Streams - https://aws.amazon.com/kafka - https://aws.amazon.com/kinesis
- Google Cloud - Confluent Cloud on GCP - https://cloud.google.com/blog/products/gcp/google-cloud-platform-and-confluent-partner-to-deliver-a-managed-apache-kafka-service
Meet Kafka (Definitive Guide)
- Messages and Batches
- Message
- Key (byte array, used when messages are to be written to partitions in a more controlled manner)
- Batches (Compressed)
- Schemas (JSON, Avro)
- Topics and Partitions
- Producers and Consumers
- Kafka Connect API
- Kafka Streams
- offset (metadata - an integer value that continually increases)
- consumer group (group ensures that each partition is only consumed by one member)
- The mapping of a consumer to a partition is often called ownership of the partition by the consumer
- Brokers and Clusters
- leader of the partition - cluster controller (elected automatically from the live member of the cluster)
- retention
- log compacted, which means that Kafka will retain only the last message produced with a specific key.
- Log compaction
- Multiple clusters
- The replication mechanisms within the Kafka clusters are designed only to work within a single cluster, not between multiple clusters
- Named after writer Franz Kafka
Best Practices
- https://www.infoq.com/articles/apache-kafka-best-practices-to-optimize-your-deployment
- https://dzone.com/articles/20-best-practices-for-working-with-apache-kafka-at
- https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
- https://www.datadoghq.com/blog/kafka-at-datadog
Kafka Presentations
- Kafka Fundamentals
- Introduction to Apache Kafka | PPT
- Fundamentals for Apache Kafka
- Gently Down the Stream
Learning
- GitHub - deepaksood619/cp-sandbox: Docker-compose file for Confluent Kafka with configuration mounted as properties files. Brings up Kafka and components with JMX metrics exposed and visualized using Prometheus and Grafana ⭐ 0
- GitHub - Irtebat/cfk-reference-deployments ⭐ 0
References
- Apache Kafka 101: Confluent's Flagship Course on Apache Kafka® Fundamentals ft. Tim Berglund - YouTube
- Kafkademy | Conduktor
- https://en.wikipedia.org/wiki/Apache_Kafka
- https://kafka.apache.org/intro
- https://thehoard.blog/how-kafkas-storage-internals-work-3a29b02e026
- https://scotch.io/tutorials/build-a-distributed-streaming-system-with-apache-kafka-and-python
- ISR (In-Sync Replica set) - https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
- https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
- https://www.confluent.io/blog/okay-store-data-apache-kafka
- https://engineering.linkedin.com/blog/2019/apache-kafka-trillion-messages
- https://engineeringblog.yelp.com/2020/01/streams-and-monk-how-yelp-approaches-kafka-in-2020.html
- https://www.waitingforcode.com/apache-kafka/apache-kafka-idempotent-producer/read
- https://kafkasummit.io/session-library/
- Streamline Event-driven Microservices With Kafka and Python | Toptal
- Apache Kafka Explained (Comprehensive Overview) - YouTube
- How to Deploy Kafka using Kubernetes Kafka Operator
- Kafka Tiered Storage from Uber - by Bugra Akyildiz
- Kafka 101
- The Trillion Message Kafka Setup at Walmart
- Demo: ACL Authorization · The Internals of Apache Kafka
- Kafka Challenges and How to Overcome Them
- Interview Questions - ChatGPT - Kafka Interview Questions