Understanding Kafka Connect Architecture
Version Differences: Kafka Connect 2.7 vs 3.7
The evolution from Apache Kafka Connect 2.7 to 3.7 involves significant framework improvements, security enhancements, and operational maturity.
Key Architectural & Framework Differences
KRaft Integration (No ZooKeeper)
- Version 2.7: Relies heavily on Apache ZooKeeper for cluster coordination
- Version 3.7: Fully matures KRaft (Kafka Raft Metadata Mode), removing dependency on ZooKeeper for managing metadata
- JBOD in KRaft (Early Access) via KIP-858
- 11 new KRaft performance metrics (KIP-938)
- Can independently stop KRaft processes (KIP-979)
Java Runtime Support
- Version 2.7: Operates on older Java runtimes (Java 8, Java 11)
- Version 3.7: Deprecates Java 11 support for brokers/tools (removal in Kafka 4.0), pushes modern Java standards forward
Client and Admin APIs
- Version 3.7: Deprecates older client APIs released prior to version 2.1 (KIP-896) in preparation for major future cleanups, affecting how custom connectors interact with brokers (removal in Kafka 4.0)
- Enhanced AdminClient can talk directly with KRaft Controller Quorum (KIP-919)
Kafka Connect Specific Improvements (3.7)
New Features
- KIP-980: Create connectors in stopped state - new
initial_statefield allows deploying connectors without immediately starting them - KIP-976: Cluster-wide dynamic log adjustment for better operational control
- KIP-959: BooleanConverter added for improved type handling
- KIP-970: Deprecates redundant task configurations endpoint
Performance & Reliability
- KIP-951: Leader discovery optimizations reduce latency during leadership changes
- KIP-580: Exponential backoff for Kafka clients helps reduce metadata convergence issues
- Automatic task restart capabilities for failed tasks (especially relevant in managed services)
Operational and Ecosystem Changes
Managed Services Support
- Amazon MSK Connect: Supports both Kafka Connect 2.7.1 and 3.7.x runtimes
- Version 3.7.x leverages major bug fixes, better stability, and enhanced worker-to-broker communication metrics
- Automatic horizontal and vertical scaling (1-8 vCPUs)
- Automatic task recovery and restart
- Continuous health monitoring and patching
Config and Security Enhancements (3.7)
- Incremental security patches
- Improved TLS handling with dynamic certificate reloading (KIP-978) - supports different DN/SANs
- Finer control over connector client configuration overrides
- Transaction verification for consumer offset partitions (KIP-890)
Observability (3.7)
- KIP-714: Broker-side support for client-level metrics
- KIP-1000: Create/read/update/delete metrics configurations
- New
CurrentControllerIdmetric (KIP-1001) - Additional tiered storage metrics (KIP-963)
Migration Considerations
Upgrade Path
- Kafka 3.7 supports upgrade from versions 0.8.x through 3.6.x
- Custom connectors using deprecated client APIs (pre-2.1) need review before Kafka 4.0
Deprecation Timeline
- ZooKeeper deprecated since 3.5.0, removal planned for Kafka 4.0
- Java 11 broker support deprecated in 3.7, removal in Kafka 4.0
- Client APIs older than Kafka 2.1 deprecated, removal in Kafka 4.0
Core Architecture
- Connectors and tasks
- Connectors
- Determining how many tasks will run for the connector
- Deciding how to split the data-copying work between the tasks
- Getting configurations for the tasks from the workers and passing it along
- Tasks
- Tasks are responsible for actually getting the data in and out of Kafka
- Connectors
- Workers
Kafka Connect's worker processes are the "container' processes that execute the connectors and tasks
- Connectors and tasks are responsible for the "moving data" part of data integrations, while the workers are responsible for the REST API, configuration management, reliability, high availability, scaling, and load balancing
- Source Connectors bring external data into Kafka (like capturing changes in Salesforce)
- Sink Connectors send Kafka data to external systems (like pushing records into Elasticsearch)
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other systems. It makes it simple to quickly define connectors that move large collections of data into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. An export job can deliver data from Kafka topics into secondary storage and query systems or into batch systems for offline analysis.
Kafka Connect features
- A common framework for Kafka connectors - Kafka Connect standardizes integration of other data systems with Kafka, simplifying connector development, deployment, and management
- Distributed and standalone modes - scale up to a large, centrally managed service supporting an entire organization or scale down to development, testing, and small production deployments
- REST interface - submit and manage connectors to your Kafka Connect cluster via an easy to use REST API
- Automatic offset management - with just a little information from connectors, Kafka Connect can manage the offset commit process automatically so connector developers do not need to worry about this error prone part of connector development
- Distributed and scalable by default - Kafka Connect builds on the existing group management protocol. More workers can be added to scale up a Kafka Connect cluster.
- Streaming/batch integration - leveraging Kafka's existing capabilities, Kafka Connect is an ideal solution for bridging streaming and batch data systems
Kafka Connect currently supports two types of Workers
1. Standalone (single process)
Standalone mode is the simplest mode, where a single process is responsible for executing all connectors and tasks.
2. Distributed
Distributed mode provides scalability and automatic fault tolerance for Kafka Connect. In distributed mode, you start many worker processes using the samegroup.idand they automatically coordinate to schedule execution of connectors and tasks across all available workers. If you add a worker, shut down a worker, or a worker fails unexpectedly, the rest of the workers detect this and automatically coordinate to redistribute connectors and tasks across the updated set of available workers. Note the similarity to consumer group rebalance. Under the covers, connect workers are using consumer groups to coordinate and rebalance.

Main components
- Connectors-- the high level abstraction that coordinates data streaming by managing tasks
- Tasks-- the implementation of how data is copied to or from Kafka
- Workers-- the running processes that execute connectors and tasks
- Converters-- the code used to translate data between Connect and the system sending or receiving data
- Transforms-- simple logic to alter each message produced by or sent to a connector
Task
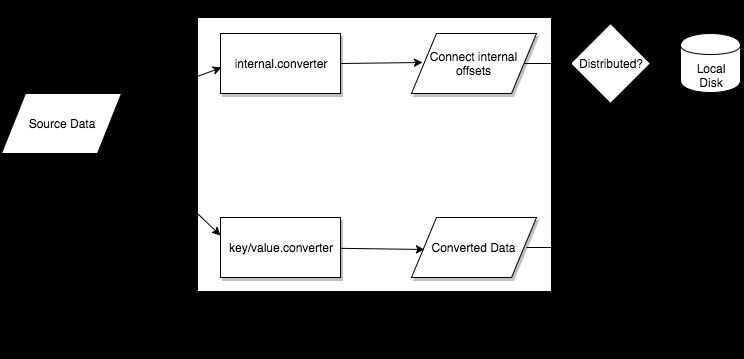
Connect REST API
https://docs.confluent.io/current/connect/references/restapi.html
Connect typically runs in distributed mode and can be managed through REST APIs. The following table shows the common APIs.
| CONNECT REST API | MEANING |
|---|---|
| GET /connectors | Return a list of active connectors |
| POST /connectors | Create a new connector |
GET /connectors/{name} | Get the information of a specific connector |
GET /connectors/{name}/config | Get configuration parameters for a specific connector |
PUT /connectors/{name}/config | Update configuration parameters for a specific connector |
GET /connectors/{name}/status | Get the current status of the connector |
- GET /connectors- return a list of active connectors
- POST /connectors- create a new connector; the request body should be a JSON object containing a stringnamefield and an objectconfigfield with the connector configuration parameters
- GET /connectors/{name}- get information about a specific connector
- GET /connectors/{name}/config- get the configuration parameters for a specific connector
- PUT /connectors/{name}/config- update the configuration parameters for a specific connector
- GET /connectors/{name}/status- get current status of the connector, including if it is running, failed, paused, etc., which worker it is assigned to, error information if it has failed, and the state of all its tasks
- GET /connectors/{name}/tasks- get a list of tasks currently running for a connector
- GET /connectors/{name}/tasks/{taskid}/status- get current status of the task, including if it is running, failed, paused, etc., which worker it is assigned to, and error information if it has failed
- PUT /connectors/{name}/pause- pause the connector and its tasks, which stops message processing until the connector is resumed
- PUT /connectors/{name}/resume- resume a paused connector (or do nothing if the connector is not paused)
- POST /connectors/{name}/restart- restart a connector (typically because it has failed)
- POST /connectors/{name}/tasks/{taskId}/restart- restart an individual task (typically because it has failed)
- DELETE /connectors/{name}- delete a connector, halting all tasks and deleting its configuration
Kafka Connect Query Language (KCQL)
https://github.com/Landoop/kafka-connect-query-language
Commands
# using confluent mqtt source connector
docker exec kafka-connect curl -s -X POST -H "Content-Type: application/json" --data '{"name": "smap-mqtt-source", "config": {"connector.class": "io.confluent.connect.mqtt.MqttSourceConnector", "tasks.max":"1", "mqtt.server.uri":"tcp://emqx:1883", "mqtt.topics":"telemetry/#", "kafka.topic": "smap_telemetry_data", "mqtt.username":"abc_mqtt_client", "mqtt.password":"xitanez123"}}' http://kafka-connect:8082/connectors
errors.log.enable = false
errors.log.include.messages = false
errors.retry.delay.max.ms = 60000
errors.retry.timeout = 0
errors.tolerance = none
header.converter = null
key.converter = null
name = smap-mqtt-source
tasks.max = 1
transforms = []
value.converter = null
# using lenses connector
docker exec kafka-connect curl -s -X POST -H "Content-Type: application/json" --data '{"name": "smap-mqtt-source-lenses", "config": {"connector.class": "com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector", "tasks.max":"1", "connect.mqtt.hosts":"tcp://emqx:1883", "connect.mqtt.username":"abc_mqtt_client", "connect.mqtt.password":"xitanez123", "connect.mqtt.service.quality":"1", "connect.mqtt.kcql":"INSERT INTO smap_telemetry_data SELECT * FROM telemetry/+/+ WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.BytesConverter`"}}' http://kafka-connect:8082/connectors
# validate configuration values
docker exec kafka-connect curl -s -X PUT -H "Content-Type: application/json" -d '{"name":"smap-mqtt-source","config": {"connector.class": "io.confluent.connect.mqtt.MqttSourceConnector", "tasks.max":"1", "mqtt.server.uri":"tcp://emqx:1883", "mqtt.username":"abc_mqtt_client", "mqtt.password":"xitanez123", "mqtt.topic":"smap_telemetry_data", "kafka.topic": "smap_telemetry_data"}}' http://kafka-connect:8082/connector-plugins/MqttSourceConnector/config/validate
# list all connector available
docker exec kafka-connect curl -s -X GET http://kafka-connect:8082/connectors/
docker exec kafka-connect curl -s -X GET http://kafka-connect:8082/connector-plugins/
# get status of a connector
docker exec kafka-connect curl -s -X GET http://kafka-connect:8082/connectors/smap-mqtt-source status
# delete connector
docker exec kafka-connect curl -X DELETE http://kafka-connect:8082/connectors/smap-mqtt-source
#Updating a connector config
curl -s -X PUT -H "Content-Type:application/json" --data '{"connector.class": "com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector", "tasks.max":"1", "connect.mqtt.hosts":"tcp://mqtt.vernemq:1883", "connect.mqtt.username":"abc_mqtt_client", "connect.mqtt.password":"xitanez123", "connect.mqtt.service.quality":"1", "connect.mqtt.clean":"false", "connect.mqtt.kcql":"INSERT INTO smap_telemetry_data SELECT * FROM telemetry/+/+ WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.BytesConverter`"}' http://ke-cp-kafka-connect.kafka:8083/connectors/smap-mqtt-source-lenses/config
Lenses Source Mqtt Connector
Configurations
-
Kafka Connect framework configurations
- name
- tasks.max (1)
-
connector.class (com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector)
-
Connector Configurations
- connect.mqtt.ksql
- connect.mqtt.hosts
-
Optional Configurations
- connect.mqtt.service.quality (default - 1)
- connect.mqtt.username
- connect.mqtt.password
- connect.mqtt.client.id
- connect.mqtt.timeout (default - 3000ms)
- connect.mqtt.clean (default - true)
- connect.mqtt.keep.alive (default - 5000)
- connect.mqtt.converter.throw.on.error (default - false)
- connect.converter.avro.schemas
- connect.progress.enabled
Commands
curl -s -X POST -H "Content-Type: application/json" --data '{"name": "bench-test", "config": {"connector.class": "com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector", "tasks.max":"1", "connect.mqtt.hosts":"tcp://mqtt.vernemq:1883", "connect.mqtt.username":"example_mqtt_client", "connect.mqtt.password":"xitanez123", "connect.mqtt.client.id":"bench-test-client-id", "connect.mqtt.service.quality":"1", "connect.mqtt.clean":"false", "connect.mqtt.kcql":"INSERT INTO bench_data SELECT * FROM bench/+ WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.BytesConverter`"}}'
http://ke-cp-kafka-connect.kafka:8083/connectors
https://docs.lenses.io/connectors/source/mqtt.html
Simple Message Transformations (SMT)
These single message transforms (SMTs) are available for use with Kafka Connect:
| Transform | Description |
|---|---|
| Cast | Cast fields or the entire key or value to a specific type, e.g. to force an integer field to a smaller width. |
| ExtractField | Extract the specified field from a Struct when schema present, or a Map in the case of schemaless data. Any null values are passed through unmodified. |
| ExtractTopic | Replace the record topic with a new topic derived from its key or value. |
| Flatten | Flatten a nested data structure. This generates names for each field by concatenating the field names at each level with a configurable delimiter character. |
| HoistField | Wrap data using the specified field name in a Struct when schema present, or a Map in the case of schemaless data. |
| InsertField | Insert field using attributes from the record metadata or a configured static value. |
| MaskField | Mask specified fields with a valid null value for the field type. |
| RegexRouter | Update the record topic using the configured regular expression and replacement string. |
| ReplaceField | Filter or rename fields. |
| SetSchemaMetadata | Set the schema name, version, or both on the record's key or value schema. |
| TimestampConverter | Convert timestamps between different formats such as Unix epoch, strings, and Connect Date and Timestamp types. |
| TimestampRouter | Update the record's topic field as a function of the original topic value and the record timestamp. |
| ValueToKey | Replace the record key with a new key formed from a subset of fields in the record value. |
Related Topics
- Confluent Cloud RBAC and Authentication Best Practices - Connector permissions, service accounts, API keys
- connectors
References
- Confluent Marketplace: Apache Kafka Connectors for Streaming Data | Confluent Hub: Apache Kafka Connectors for Streaming Data
- https://docs.confluent.io/current/connect/userguide.html
- https://kafka.apache.org/documentation.html#connect
- https://kafka.apache.org/documentation/#connectapi
- https://docs.confluent.io/current/installation/docker/docs/installation/single-node-client.html#step-7-start-kafka-connect
- https://docs.confluent.io/current/connect/transforms/index.html
- Snowflake Just Unlocked Real-Time Kafka Streaming at Unprecedented Scale | by Sahil Walia | Snowflake Builders Blog: Data Engineers, App Developers, AI, & Data Science | Jan, 2026 | Medium
- Introducing Apache Kafka 3.7
- Amazon MSK Connect Documentation