Understanding Kafka Consumers
The consumer is the receiver of the message in Kafka
- Each consumer belongs to a consumer group
- A consumer group may have one or more consumers
- The consumers specify what topics they want to listen to
- A message is sent to all the consumers in a consumer group
- The consumer groups are used to control the messaging system
Inner Working
Heartbeats
- The way consumers maintain membership in a consumer group and ownership of the partitions assigned to them is by sending heartbeats to a Kafka broker designated as the group coordinator (this broker can be different for different consumer groups).
- As long as the consumer is sending heartbeats at regular intervals, it is assumed to be alive, well, and processing messages from its partitions.
- Heartbeats are sent when the consumer polls (i.e., retrieves records) and when it commits records it has consumed.
- If the consumer stops sending heartbeats for long enough, its session will time out and the group coordinator will consider it dead and trigger a rebalance. If a consumer crashed and stopped processing messages, it will take the group coordinator a few seconds without heartbeats to decide it is dead and trigger the rebalance. During those seconds, no messages will be processed from the partitions owned by the dead consumer. When closing a consumer cleanly, the consumer will notify the group coordinator that it is leaving, and the group coordinator will trigger a rebalance immediately, reducing the gap in processing.
- Please ensure that your Kafka consumer configuration has adequate session timeout and heartbeat interval settings. The session timeout should be long enough to accommodate the longest time it might take to process a message, and the heartbeat interval should be frequent enough to let the coordinator know the consumer is still alive.
Rebalance
- Moving partition ownership from one consumer to another
- During a rebalance, consumers can't consume messages, so a rebalance is basically a short window of unavailability of the entire consumer group
- when partitions are moved from one consumer to another, the consumer loses its current state; if it was caching any data, it will need to refresh its caches - slowing down the application until the con‐ sumer sets up its state again.
The Assignment Workflow (The Rebalance Protocol)
- Find Coordinator: Consumers send a request to any broker to find out which broker is their Group Coordinator.
- JoinGroup Phase: All consumers send a
JoinGrouprequest to the Coordinator. They include metadata, such as which topics they subscribe to. - Leader Election: The Coordinator selects the first consumer to join as the Group Leader.
- Distributing Info: The Coordinator sends the list of all active members to the Group Leader. (Other members just get a "wait" response).
- Assignment (The Decision): The Group Leader runs a partition assignment algorithm (see section 3 below) to map partitions to members.
- SyncGroup Phase:
- The Leader sends the final assignments for everyone back to the Coordinator via a
SyncGrouprequest. - Other members also send a
SyncGrouprequest to the Coordinator (essentially asking, "What is my assignment?").
- The Leader sends the final assignments for everyone back to the Coordinator via a
How Does the Process of Assigning Partitions to Brokers Work?
- When a consumer wants to join a group, it sends a
JoinGrouprequest to the group coordinator. The first consumer to join the group becomes the group leader. The leader receives a list of all consumers in the group from the group coordinator (this will include all consumers that sent a heartbeat recently and which are therefore considered alive) and is responsible for assigning a subset of partitions to each consumer. It uses an implementation of PartitionAssignor to decide which partitions should be handled by which consumer. - Kafka has two built-in partition assignment policies. After deciding on the partition assignment, the consumer leader sends the list of assignments to the GroupCoordinator, which sends this information to all the consumers. Each consumer only sees his own assignment - the leader is the only client process that has the full list of consumers in the group and their assignments. This process repeats every time a rebalance happens.
- partition.assignment.strategy
[ Range, RoundRobin, StickyAssignor ]
- partition.assignment.strategy
The poll loop
At the heart of the consumer API is a simple loop for polling the server for more data. Once the consumer subscribes to topics, the poll loop handles all details of coordination, partition rebalances, heartbeats, and data fetching, leaving the developer with a clean API that simply returns available data from the assigned partitions.
Difference between Poll Loop and Fetch
- Poll Loop (
consumer.poll()): This is the high-level API method the application calls. It is the "heartbeat" of the consumer. It handles:- Coordination: Sending heartbeats to the Consumer Group Coordinator to say "I am alive."
- Rebalancing: Handling partition assignments if other consumers join/leave.
- Retrieving Records: It returns the records to your code.
- Fetch: This is the internal network request mechanism. While
poll()is running, the consumer client creates "Fetch Requests" to send to the brokers to pull raw bytes. Thepoll()loop wraps these fetch requests and manages the complexity of parsing the batches into individual records.
Configuration of Consumers
- fetch.min.bytes
- fetch.max.wait.ms
- max.partition.fetch.bytes
- session.timeout.ms
- auto.offset.reset
- enable.auto.commit
- partition.assignment.strategy
[ Range, RoundRobin ] - client.id
- max.poll.records
- receive.buffer.bytes and send.buffer.bytes
Commits and Offsets
_consumer_offsetstopic- Automatic Commit
- Commit Current Offset
auto.commit.offset = [true, false]
- Asynchronous Commit
- Commit Specified Offset
commitSync()orCommitAsync()
- Rebalance Listeners
- Consuming Records with Specific Offsets
- Exiting the consumer
- consumer.wakeup()
- consumer.close()
- Standalone Consumer, Consumer without a group
Kafka Consumer Groups
A consumer group is a group of related consumers that perform a task, like putting data into Hadoop or sending messages to a service. Consumer groups each have unique offsets per partition. Different consumer groups can read from different locations in a partition.
The consumer groups have their own offset for every partition in the topic which is unique to what other consumer groups have.
A consumer group has a unique id. Each consumer group is a subscriber to one or more Kafka topics. Each consumer group maintains its offset per topic partition. If you need multiple subscribers, then you have multiple consumer groups. A record gets delivered to only one consumer in a consumer group.
Each consumer in a consumer group processes records and only one consumer in that group will get the same record. Consumers in a consumer group load balance record processing.
The partitions of any topics subscribed to by consumers in a consumer group are guaranteed to be assigned to at most one individual consumer in that group at any time. The messages from each topic partition are delivered to the assigned consumer strictly in the order they are stored in the log.
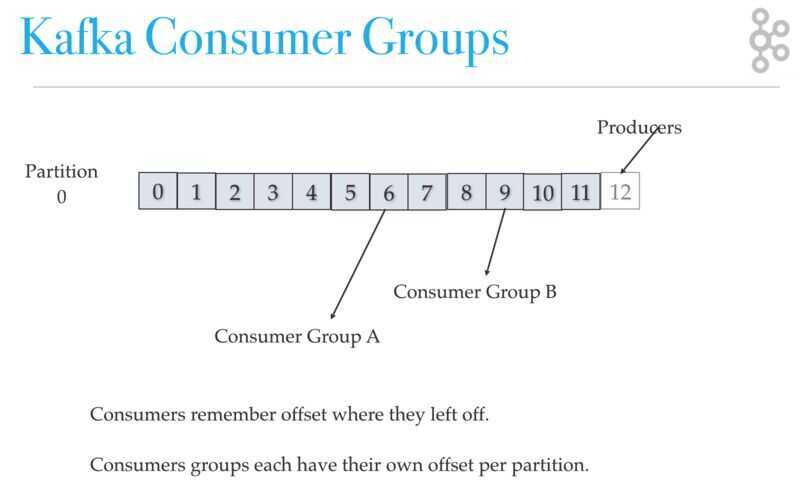
Consumers remember offset where they left off reading. Consumers groups each have their own offset per partition.
Suppose you have an application that needs to read messages from a Kafka topic, run some validations against them, and write the results to another data store. In this case your application will create a consumer object, subscribe to the appropriate topic, and start receiving messages, validating them and writing the results. This may work well for a while, but what if the rate at which producers write messages to the topic exceeds the rate at which your application can validate them? If you are limited to a single consumer reading and processing the data, your application may fall farther and farther behind, unable to keep up with the rate of incoming messages. Obviously there is a need to scale consumption from topics. Just like multiple producers can write to the same topic, we need to allow multiple consumers to read from the same topic, splitting the data between them.
Kafka consumers are typically part of aconsumer group. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive messages from a different subset of the partitions in the topic.
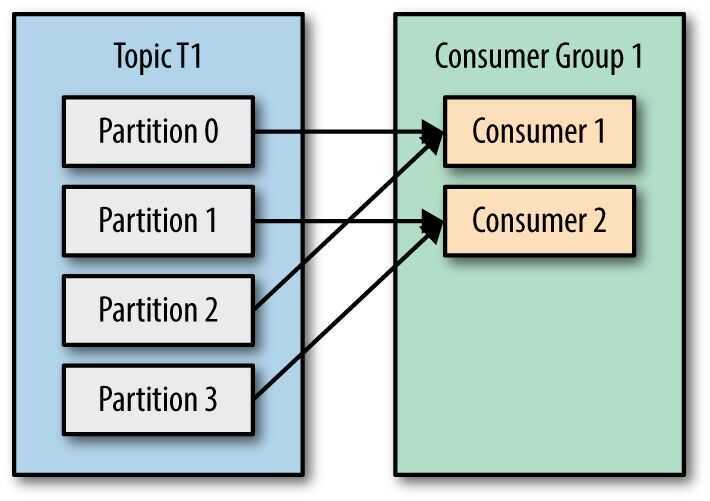
Kafka Consumer Load Share
Kafka consumer consumption divides partitions over consumer instances within a consumer group. Each consumer in the consumer group is an exclusive consumer of a "fair share" of partitions. This is how Kafka does load balancing of consumers in a consumer group. Consumer membership within a consumer group is handled by the Kafka protocol dynamically. If new consumers join a consumer group, it gets a share of partitions. If a consumer dies, its partitions are split among the remaining live consumers in the consumer group. This is how Kafka does fail over of consumers in a consumer group.
Kafka Consumer Failover
Consumers notify the Kafka broker when they have successfully processed a record, which advances the offset.
If a consumer fails before sending commit offset to Kafka broker, then a different consumer can continue from the last committed offset.
If a consumer fails after processing the record but before sending the commit to the broker, then some Kafka records could be reprocessed. In this scenario, Kafka implements the at least once behavior, and you should make sure the messages (record deliveries ) are idempotent.
Offset Management
Kafka stores offset data in a topic called __consumer_offset. These topics use log compaction, which means they only save the most recent value per key.
When a consumer has processed data, it should commit offsets. If consumer process dies, it will be able to start up and start reading where it left off based on offset stored in __consumer_offset or as discussed another consumer in the consumer group can take over.
Reset Offsets
You can reset offsets for consumer groups. Offsets track the position of a consumer in a partition. Each consumer instance in a consumer group periodically commits its progress through the partition with an offset. If a consumer instance fails, another instance in the group takes over and resumes from the last committed offset.
# 1. Reset to Earliest (Reprocess all data)
kafka-consumer-groups --bootstrap-server <broker_host:9092> \
--group <group_name> --reset-offsets --to-earliest --execute --topic <topic_name>
# 2. Reset to Latest (Skip all existing data)
kafka-consumer-groups --bootstrap-server <broker_host:9092> \
--group <group_name> --reset-offsets --to-latest --execute --topic <topic_name>
# 3. Reset to a Specific Offset
kafka-consumer-groups --bootstrap-server <broker_host:9092> \
--group <group_name> --reset-offsets --to-offset <offset_number> --execute --topic <topic_name>
# 4. Shift Offset by Relative Amount (e.g., back 100 messages)
kafka-consumer-groups --bootstrap-server <broker_host:9092> \
--group <group_name> --reset-offsets --shift-by -100 --execute --topic <topic_name>
# 5. Reset to a Specific Datetime
kafka-consumer-groups --bootstrap-server <broker_host:9092> \
--group <group_name> --reset-offsets \
--to-datetime 2026-03-01T00:00:00.000 --execute --topic <topic_name>
Reset consumer offsets in Confluent Cloud | Confluent Documentation
What Can Kafka Consumers See?
What records can be consumed by a Kafka consumer? Consumers can't read un-replicated data. Kafka consumers can only consume messages beyond the "High Watermark" offset of the partition. "Log end offset" is offset of the last record written to log partition and where producers writes to next.
"High Watermark" is the offset of the last record that was successfully replicated to all partition's followers. Consumer only reads up to the "High Watermark".
When can a consumer see a record?
A consumer can see a record after the record gets fully replicated to all followers.
Consumer to Partition Cardinality - Load Sharing Redux
Only a single consumer from the same consumer group can access a single partition. If consumer group count exceeds the partition count, then the extra consumers remain idle. Kafka can use the idle consumers for failover. If there are more partitions than consumer group, then some consumers will read from more than one partition.
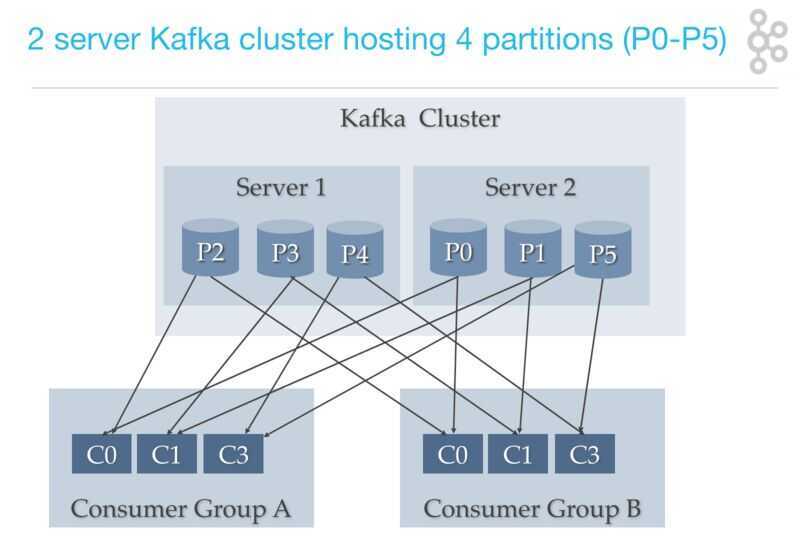
Notice that server 1 has topic partition P2, P3, and P4, while server 2 has partition P0, P1, and P5. Notice that Consumer C0 from Consumer Group A is processing records from P0 and P2. Notice that no single partition is shared by any consumer from any consumer group. Notice that each partition gets its fair share of partitions for the topics.
Multi-Threaded Kafka Consumers
You can run more than one Consumer in a JVM process by using threads.
Consumer With Many Threads
If processing a record takes a while, a single Consumer can run multiple threads to process records, but it is harder to manage offset for each Thread/Task. If one consumer runs multiple threads, then two messages on the same partitions could be processed by two different threads which make it hard to guarantee record delivery order without complex thread coordination. This setup might be appropriate if processing a single task takes a long time, but try to avoid it.
Thread per Consumer
If you need to run multiple consumers, then run each consumer in their own thread. This way Kafka can deliver record batches to the consumer and the consumer does not have to worry about the offset ordering. A thread per consumer makes it easier to manage offsets. It is also simpler to manage failover (each process runs X num of consumer threads) as you can allow Kafka to do the brunt of the work.
What happens if you run multiple consumers in many threads in the same JVM?
Each thread manages a share of partitions for that consumer group.

When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer's position of 6.
The diagram also shows two other significant positions in the log. The log end offset is the offset of the last message written to the log. The high watermark is the offset of the last message that was successfully copied to all of the log's replicas. From the perspective of the consumer, the main thing to know is that you can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost.
https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client
Kafka Partition Assignment Strategies
When creating a new Kafka consumer, we can configure the strategy that will be used to assign the partitions amongst the consumer instances.
The assignment strategy is configurable through the property partition.assignment.strategy
Kafka Clients provides three built-in strategies
1. Range (default)
Assigns to each consumer a consecutive subset of partitions from each topic it subscribes to. So if consumers C1 and C2 are subscribed to two topics, T1 and T2, and each of the topics has three partitions, then C1 will be assigned partitions 0 and 1 from topics T1 and T2, while C2 will be assigned partition 2 from those topics. Because each topic has an uneven number of partitions and the assignment is done for each topic independently, the first consumer ends up with more partitions than the second. This happens whenever Range assignment is used and the number of consumers does not divide the number of partitions in each topic neatly.
2. RoundRobin
Takes all the partitions from all subscribed topics and assigns them to consumers sequentially, one by one. If C1 and C2 described previously used RoundRobin assignment, C1 would have partitions 0 and 2 from topic T1 and partition 1 from topic T2. C2 would have partition 1 from topic T1 and partitions 0 and 2 from topic T2. In general, if all consumers are subscribed to the same topics (a very common scenario), RoundRobin assignment will end up with all consumers having the same number of partitions (or at most 1 partition difference).
3. StickyAssignor
The goal here is two-fold: create a balanced assignment, but also minimize the number of partitions that move from one consumer to another during a rebalance.
- Why use it: Moving a partition is expensive (the consumer has to drop local cache/state and the new owner has to rebuild it). Sticky assignment tries to keep partitions with their previous owners as much as possible.
4. Cooperative Sticky Assignor (Incremental)
This is the modern standard (available since Kafka 2.4).
- The Old Way (Eager Rebalance): Historically, when a rebalance started, everyone had to stop processing, give up all partitions, and wait for new assignments. This is a "stop-the-world" event.
- The New Way (Cooperative): Consumers only give up partitions that need to be moved to a different consumer. They keep processing their current partitions while the rebalance happens in the background.
When to use Cooperative Sticky:
- High partition count workloads
- Frequent consumer pod churn or autoscaling
- Scenarios where rebalances are already expensive
- Better than Round Robin for reducing partition movement during membership changes
Rebalance Protocols: Classic vs KIP-848
Classic Consumer Rebalance Protocol
The traditional rebalance protocol has several characteristics:
Client-Driven Coordination:
- Rebalance logic is primarily handled on the consumer side
- Each consumer maintains its own view of cluster metadata
- Group-wide synchronization barrier required
- Thick client implementation with complex state management
Limitations at Scale:
- Rebalance cost grows with group size
- Different clients can have inconsistent metadata views
- Even cooperative variants retain synchronization barriers
- Operational complexity increases with heterogeneous client versions
Regex Subscription Under Classic Protocol:
When consumers subscribe using regex patterns:
- Regex resolution is performed client-side
- Consumer first requests full metadata from broker
- Client locally resolves pattern against topic list
- During rebalances, each consumer may send multiple metadata requests (potentially dozens to hundreds)
- In stable state, metadata requests occur roughly every 5 minutes per consumer
Why this is expensive:
- Metadata responses can be very large (multi-MB for clusters with many topics)
- Metadata request handling is CPU-intensive on brokers
- Authorization checks add overhead
- Large topic counts amplify the problem significantly
KIP-848: Next-Generation Consumer Rebalance Protocol
KIP-848 (also called group.protocol=consumer) is the modern rebalance protocol introduced for Kafka 4.0+.
Architecture Changes:
- Server-Driven Coordination: Rebalance logic moves from clients to the broker-side group coordinator
- Incremental Rebalancing: Only affected partitions are reassigned, not the entire assignment
- Centralized State: Single source of truth on the broker reduces inconsistency
- Broker-Side Regex: Pattern subscription is resolved on the broker, not the client
Key Benefits:
- Faster Rebalances: Reduced coordination overhead and network round-trips
- More Stable Large Groups: Better handling of high consumer counts
- Reduced Metadata Load: Broker-side regex eliminates client-side topic enumeration
- Simpler Operations: Centralized troubleshooting instead of collecting logs from every consumer
- Better Roll Behavior: Can achieve zero-rebalance cluster rolls in optimal conditions
Configuration:
group.protocol=consumer # Enable KIP-848 (Kafka 3.7+)
When to Use KIP-848:
- Large consumer groups (hundreds to thousands of consumers)
- High topic counts combined with regex subscriptions
- Frequent deployment rolls or pod churn
- Heterogeneous client versions across the fleet
- Workloads experiencing metadata storms during rebalances
Important Considerations:
- Not all client language bindings support KIP-848 yet (check your client library version)
- Requires Kafka broker version 3.7+ for full support
- Migration requires client upgrades across the consumer group
- Test thoroughly before production rollout
Metadata Storms and Consumer Scaling
What is a Metadata Storm?
A metadata storm occurs when many consumers simultaneously request topic metadata from brokers, causing:
- CPU overload on brokers
- Increased latency for all requests
- Potential cluster instability or downtime
- Skewed load distribution during broker rolls
Common Triggers
- Consumer Rebalances: Especially with classic protocol + regex subscriptions
- Rolling Updates: Reconnect events concentrate metadata requests on available brokers
- Pod Autoscaling: Rapid consumer group membership changes
- Network Partitions: Consumers reconnect simultaneously after recovery
Why Metadata Requests are Expensive
- Authorization Overhead: Each request requires ACL checks
- Response Size: Can reach multiple megabytes for large topic counts
- CPU-Intensive Assembly: Building topic/partition information is computationally expensive
- Amplification Effect: Each consumer in a large group generates multiple requests during rebalance
Metadata Load Distribution Problems
Under normal operation, metadata load distributes evenly across brokers. However:
- During Broker Rolls: Requests accumulate on remaining online brokers
- Skew Effect: A subset of brokers can become overloaded
- Cascading Impact: Overload can block the roll process itself
Best Practices for Avoiding Metadata Storms
1. Assignment Strategy Selection:
- Avoid: Round Robin (moves many partitions on each membership change)
- Use: Cooperative Sticky (minimizes partition movement)
- Best: KIP-848 with server-side coordination
2. Regex Subscription Management:
- Minimize use of regex patterns where possible
- Use explicit topic lists when topics are known
- If using regex, combine with Cooperative Sticky or KIP-848
- Monitor metadata request rates and response sizes
3. Metadata Refresh Configuration:
# Classic protocol settings
metadata.max.age.ms=300000 # Default 5 minutes, increase if stable
4. Consumer Churn Reduction:
- Avoid aggressive autoscaling policies during peak hours
- Implement gradual scale-up/scale-down
- Use pod disruption budgets to limit simultaneous restarts
- Schedule maintenance windows for non-peak times
5. Client Version Management:
- Standardize client library versions across the fleet
- Upgrade to clients supporting KIP-848 where possible
- Avoid mixing very old and very new client versions
Monitoring Metadata Health
Key Metrics:
- Metadata request rate per broker
- Metadata response size distribution
- Metadata request latency (p99, p999)
- Consumer rebalance frequency and duration
- Broker CPU utilization during rebalances
Warning Signs:
- Metadata response sizes exceeding 1MB
- Rebalances taking longer than expected
- CPU spikes correlating with consumer membership changes
- Uneven metadata load across brokers during rolls
Links
- Integrating Apache Kafka with Python Asyncio Web Applications
- https://www.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch04.html
- https://medium.com/@andy.bryant/processing-guarantees-in-kafka-12dd2e30be0e
- https://streaml.io/blog/exactly-once
- Introducing uFowarder: The Consumer Proxy for Kafka Async Queuing | Uber Blog