Kafka with KRaft: No ZooKeeper
Apache Kafka Raft (KRaft, pronounced as craft) is the consensus protocol that was introduced in KIP-500 to remove Apache Kafka’s dependency on ZooKeeper for metadata management. This greatly simplifies Kafka’s architecture by consolidating responsibility for metadata into Kafka itself, rather than splitting it between two different systems: ZooKeeper and Kafka. KRaft mode makes use of a new quorum controller service in Kafka which replaces the previous controller and makes use of an event-based variant of the Raft consensus protocol.
- What’s New in Apache Kafka 3.3 - New Features, Updates, and More
- Kafka Without ZooKeeper: A Sneak Peek At the Simplest Kafka Yet
- KRaft - Apache Kafka Without ZooKeeper
- Running Kafka without zookeeper. Kafka uses the Raft consensus algorithm… | by Kamini Kamal | Javarevisited | Medium
- Installing Apache Kafka without Zookeeper: Guide 101 | Hevo
- Kafka without Zookeeper: Tutorial & Examples
- KRaft Quorum: How to run Kafka without Zookeper
Benefits of Kafka’s new quorum controller
- KRaft enables right-sized clusters, meaning clusters that are sized with the appropriate number of brokers and compute to satisfy a use case’s throughput and latency requirements, with the potential to scale up to millions of partitions
- Improves stability, simplifies the software, and makes it easier to monitor, administer, and support Kafka
- Allows Kafka to have a single security model for the whole system
- Unified management model for configuration, networking setup, and communication protocols
- Provides a lightweight, single-process way to get started with Kafka
- Makes controller failover near-instantaneous
How it works
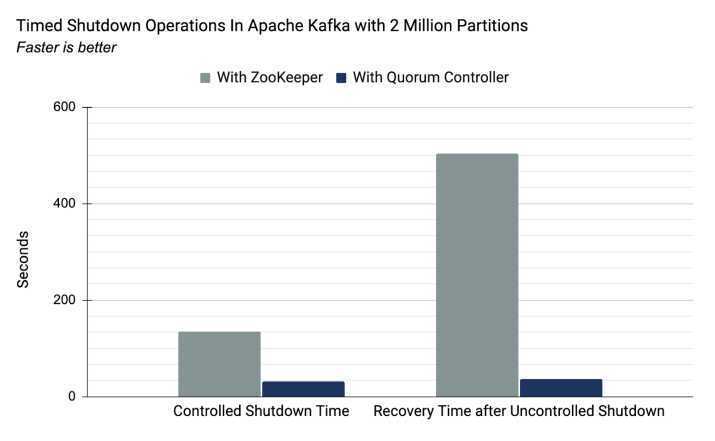
The quorum controllers use the new KRaft protocol to ensure that metadata is accurately replicated across the quorum. The quorum controller stores its state using an event-sourced storage model, which ensures that the internal state machines can always be accurately recreated. The event log used to store this state (also known as the metadata topic) is periodically abridged by snapshots to guarantee that the log cannot grow indefinitely. The other controllers within the quorum follow the active controller by responding to the events that it creates and stores in its log. Thus, should one node pause due to a partitioning event, for example, it can quickly catch up on any events it missed by accessing the log when it rejoins. This significantly decreases the unavailability window, improving the worst-case recovery time of the system.
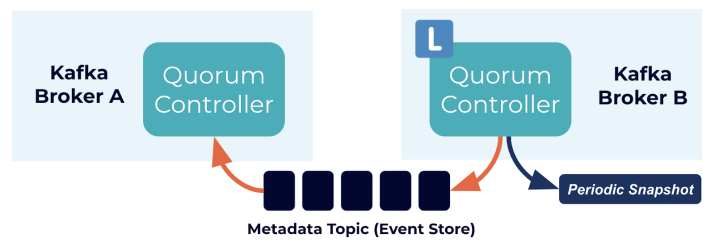
The event-driven nature of the KRaft protocol means that, unlike the ZooKeeper-based controller, the quorum controller does not need to load state from ZooKeeper before it becomes active. When leadership changes, the new active controller already has all of the committed metadata records in memory. What’s more, the same event-driven mechanism used in the KRaft protocol is used to track metadata across the cluster. A task that was previously handled with RPCs now benefits from being event-driven as well as using an actual log for communication.
The controller quorum
The KRaft controller nodes comprise a Raft quorum which manages the Kafka metadata log. This log contains information about each change to the cluster metadata. Metadata about topics, partitions, ISRs, configurations, and so on, is stored in this log.
Using the Raft consensus protocol, the controller nodes maintain consistency and leader election without relying on any external system. The leader of the metadata log is called the active controller. The active controller handles all RPCs made from the brokers. The follower controllers replicate the data which is written to the active controller, and serve as hot standbys if the active controller should fail. With the concept of a metadata log, brokers use offsets to keep track of the latest metadata stored in the KRaft controllers, which results in more efficient propagation of metadata and faster recovery from controller failovers.
KRaft requires a majority of nodes to be running. For example, a three-node controller cluster can survive one failure. A five-node controller cluster can survive two failures, and so on.
Periodically, the controllers will write out a snapshot of the metadata to disk. This is conceptually similar to compaction, but state is read from memory rather than re-reading the log from disk.
Scaling Kafka with KRaft
There are two properties that determine the number of partitions an Kafka cluster can support: the per-node partition count limit and cluster-wide partition limit.
KRaft mode is designed to handle a large number of partitions per cluster, however Kafka’s scalability still primarily depends on adding nodes to get more capacity, so the cluster-wide limit still defines the upper bounds of scalability within the system.
In KRaft, the quorum controller reduces the time taken to move critical metadata in a controller failover scenario. The result of this change is a near-instantaneous controller failover.
Limitations and known issues
- Combined mode, where a Kafka node acts as both a broker and a KRaft controller, is not currently supported by Confluent. You can start a new KRaft cluster in combined mode for testing purposes in development or testing environments. However, Confluent does not support migration to KRaft in combined mode or direct deployment in combined mode, even for development or test clusters. There are key security and feature gaps between combined mode and isolated mode in Confluent Platform.
- Confluent Platform versions older than 7.9 do not support dynamic controllers, so you cannot add or remove KRaft controllers while the cluster is running. Confluent Platform 7.9 adds this feature, but only for clusters that were bootstrapped to use dynamic controllers. For more information, see KIP-853. Confluent recommends three or five controllers for production. For hardware requirements, see Hardware.
- For information about upgrading from static controllers to dynamic controllers, and for the full KRaft server compatibility matrix showing static and dynamic controller support across Confluent Platform versions, see KRaft server compatibility.
- You cannot currently use Schema Registry Topic ACL Authorizer for Confluent Platform for Schema Registry with Confluent Platform in KRaft mode. As an alternative, you can use Schema Registry ACL Authorizer for Confluent Platform or Configure Role-Based Access Control for Schema Registry in Confluent Platform.
- Currently, Health+ reports KRaft controllers as brokers and as a result, alerts may not function as expected.
KRaft Overview | Confluent Documentation
Controller Process
In the KRaft architecture, the Controller is a Kafka server process that has been configured to perform the controller role.
Depending on how you configure your cluster, the Controller resides in one of two places:
1. Dedicated Mode (Production Recommended)
In a production environment, the Controller usually resides on its own separate nodes (separate servers or containers).
- Where it runs: It runs on a dedicated Java Virtual Machine (JVM). These nodes do not handle any client data (producing/consuming messages).
- Why here? This isolates the "brain" of the cluster from the heavy lifting. If the Brokers get overloaded with massive data traffic, it won't slow down the Controller.
- Configuration: inside
server.properties, these nodes have:process.roles=controller
2. Combined Mode (Development / Small Clusters)
In smaller setups or testing environments, the Controller resides on the same node as the Broker.
- Where it runs: The same JVM process performs both duties. It acts as a Broker (handling data) and a Controller (managing metadata) simultaneously.
- Why here? It saves money and resources because you need fewer servers.
- Configuration: inside
server.properties, these nodes have:process.roles=broker,controller
Troubleshooting
For troubleshooting CLUSTER_AUTHORIZATION_FAILED errors in KRaft clusters with RBAC, mTLS, and LDAP, see KRaft + RBAC + mTLS + LDAP Troubleshooting.