Vector Embeddings
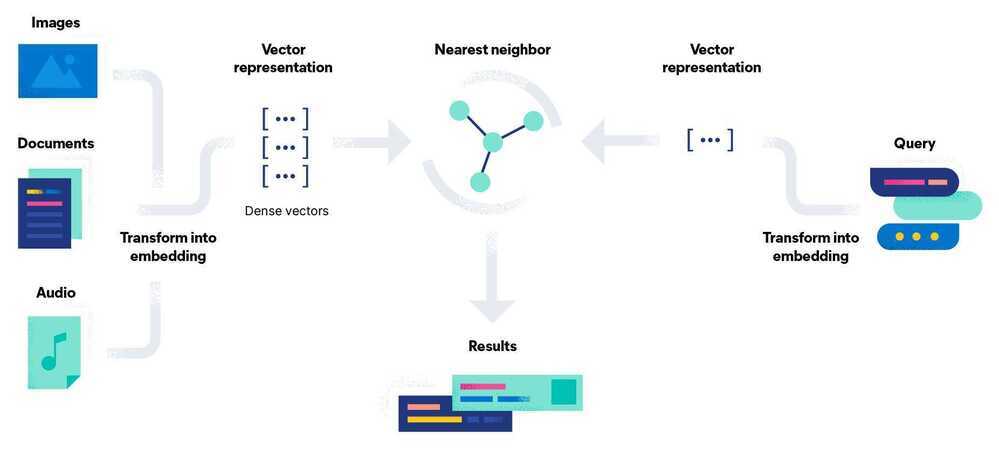
Vector embeddings are a way to convert words and sentences and other data into numbers that capture their meaning and relationships. They represent different data types as points in a multidimensional space, where similar data points are clustered closer together. These numerical representations help machines understand and process this data more effectively.
Word and sentence embeddings are two of the most common subtypes of vector embeddings, but there are others. Some vector embeddings can represent entire documents, as well as image vectors designed to match up visual content, user profile vectors to determine a user’s preferences, product vectors that help identify similar products and many others. Vector embeddings help machine learning algorithms find patterns in data and perform tasks such as sentiment analysis, language translation, recommendation systems, and many more.
Types of vector embeddings
Word embeddings
Represent individual words as vectors. Techniques like Word2Vec, GloVe, and FastText learn word embeddings by capturing semantic relationships and contextual information from large text corpora.
Sentence embeddings
Represent entire sentences as vectors. Models like Universal Sentence Encoder (USE) and SkipThought generate embeddings that capture the overall meaning and context of the sentences.
Document embeddings
Represent documents (anything from newspaper articles and academic papers to books) as vectors. They capture the semantic information and context of the entire document. Techniques like Doc2Vec and Paragraph Vectors are designed to learn document embeddings.
Image embeddings
Represent images as vectors by capturing different visual features. Techniques like convolutional neural networks (CNNs) and pre-trained models like ResNet and VGG generate image embeddings for tasks like image classification, object detection, and image similarity.
User embeddings
Represent users in a system or platform as vectors. They capture user preferences, behaviors, and characteristics. User embeddings can be used in everything from recommendation systems to personalized marketing as well as user segmentation.
Product embeddings
Represent products in ecommerce or recommendation systems as vectors. They capture a product’s attributes, features, and any other semantic information available. Algorithms can then use these embeddings to compare, recommend, and analyze products based on their vector representations.
Are embeddings and vectors the same thing?
In the context of vector embeddings, yes, embeddings and vectors are the same thing. Both refer to numerical representations of data, where each data point is represented by a vector in a high-dimensional space.
Use Cases
- Recommendation systems (i.e. Netflix-style if-you-like-these-movies-you’ll-like-this-one-too)
- All kinds of search
- Text search (like Google Search)
- Image search (like Google Reverse Image Search)
- Chatbots and question-answering systems
- Data preprocessing (preparing data to be fed into a machine learning model)
- One-shot/zero-shot learning (i.e. machine learning models that learn from almost no training data)
- Fraud detection/outlier detection
- Typo detection and all manners of "fuzzy matching"
- Detecting when ML models go stale (drift)
What are vector embeddings? | A Comprehensive Vector Embeddings Guide | Elastic
Meet AI’s multitool: Vector embeddings | Google Cloud Blog
What are Vector Embeddings | Pinecone
Text Embeddings / Transformers
- GitHub - SeanLee97/AnglE: Angle-optimized Text Embeddings | 🔥 SOTA on STS and MTEB Leaderboard ⭐ 571
- MTEB Leaderboard - a Hugging Face Space by mteb
- MTEB - Massive Text Embeddings Benchmark
- OpenAI Platform - Calculate Tokens for text
- sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
- Pretrained Models - Sentence-Transformers documentation
- sentence-transformers (Sentence Transformers)
gemini-embedding-001- Embeddings | Gemini API | Google AI for Developers- voyage-context-3
- It is a contextualized chunk embedding model that produces vectors for chunks that capture the full document context without any manual metadata and context augmentation.
- This is unlike common chunk embedding models that embed chunks independently.
- This makes your embeddings semantically rich and context-aware, without the overhead of dealing with metadata and hence the speed.
- This embedding model cuts vectorDB costs by 200x.
- FremyCompany/BioLORD-2023 · Hugging Face
- sentence-transformers/all-mpnet-base-v2 · Hugging Face
- MPNet in Practice: Building Better Sentence Embeddings for Real-World AI Systems | by Priya Singh | Medium
- The all-mpnet-base-v2 is a high-performance sentence embedding model that maps sentences/paragraphs into a 768-dimensional dense vector space. It is highly popular for semantic search, retrieval-augmented generation (RAG), and clustering due to its balance of high accuracy and reasonable speed, often outperforming older BERT/MiniLM models.
Links
- word-embedding-to-transformers
- Vector Embeddings Tutorial - Code Your Own AI Assistant with GPT-4 API + LangChain + NLP - YouTube
- $0 Embeddings (OpenAI vs. free & open source) - YouTube
- The ABCs of AI Transformers, Tokens, and Embeddings: A LEGO Story - Code with Dan Blog
- BAAI/bge-large-en · Hugging Face