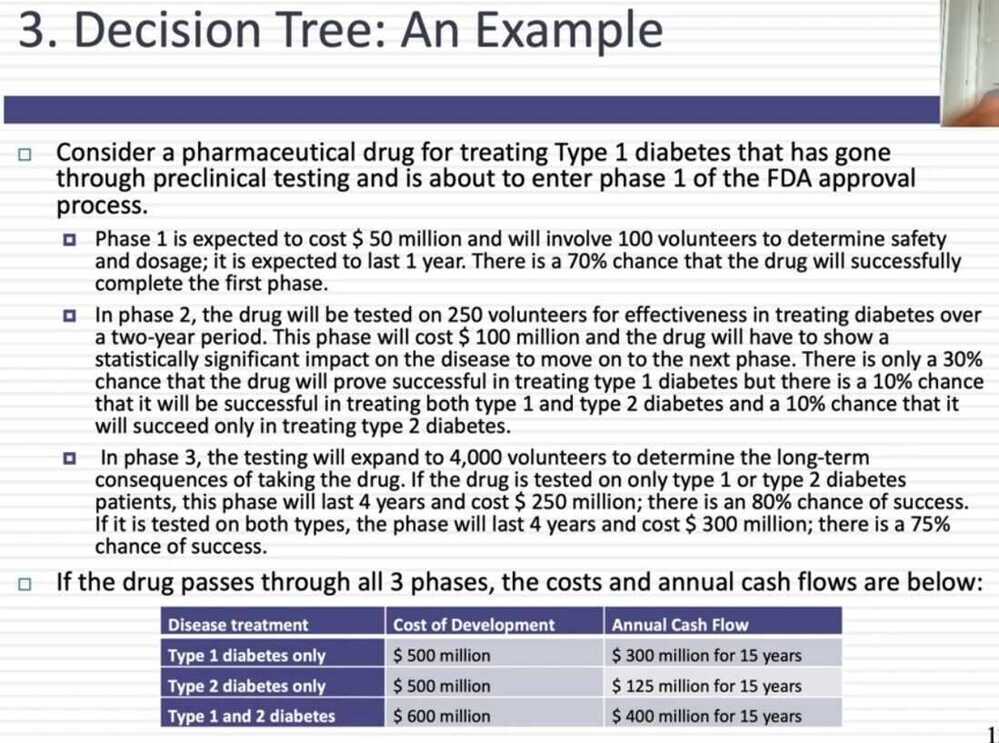
Decision Tree
Decision Tree for Big Data Analytics
Hi, decision Trees are an important type of algorithm for predictive modeling machine learning.
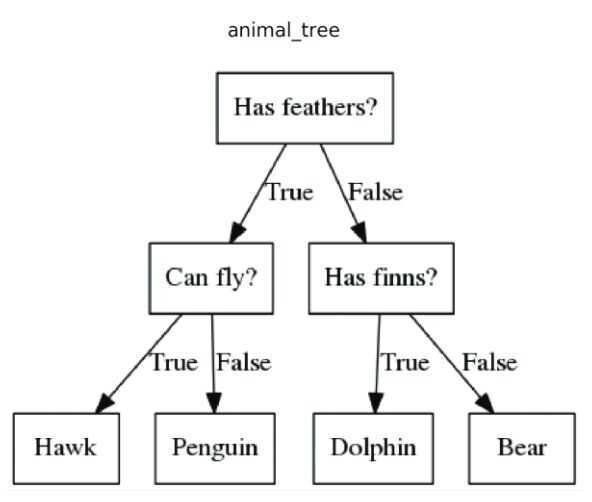
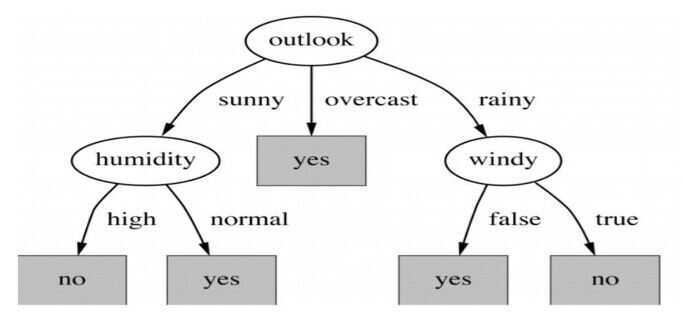
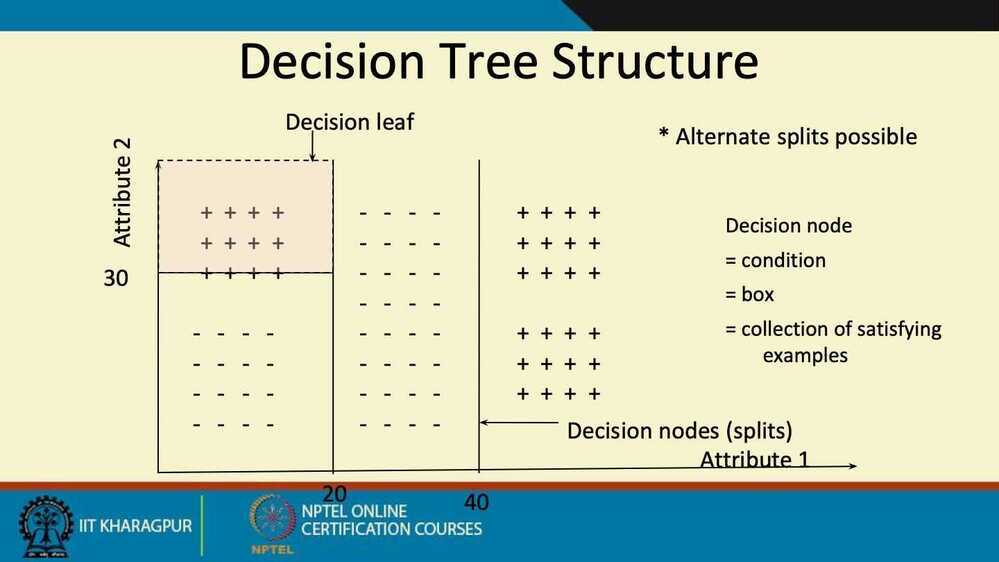
The representation of the decision treemodel is a binary tree. Each node represents a single input variable (x) and a split point on that variable (assuming the variable is numeric).
The leaf nodes of the tree contain an output variable (y) which is used to make a prediction.
Predictions are made by walking the splits of the tree until arriving at a leaf node and output the class value at that leaf node.
Trees are fast to learn and very fast for making predictions. They are also often accurate for a broad range of problems and do not require any special preparation for your data.
Decision trees have a high variance and canyield more accurate predictions when used in an ensemble.
Explain the Decision Tree algorithm
Machine learning makes use of decision trees to predict the direction of the input using a tree-like structure. They are generally binary trees with a single question node followed by two sub-nodes according to the question. Once it reaches the leaf nodes, we can make an accurate prediction of the input.
Preface
- In this lecture, we will discuss Decision Trees for Big Data Analytics and also discuss a case study of medical application using a Decision Tree in Spark ML
Decision Trees
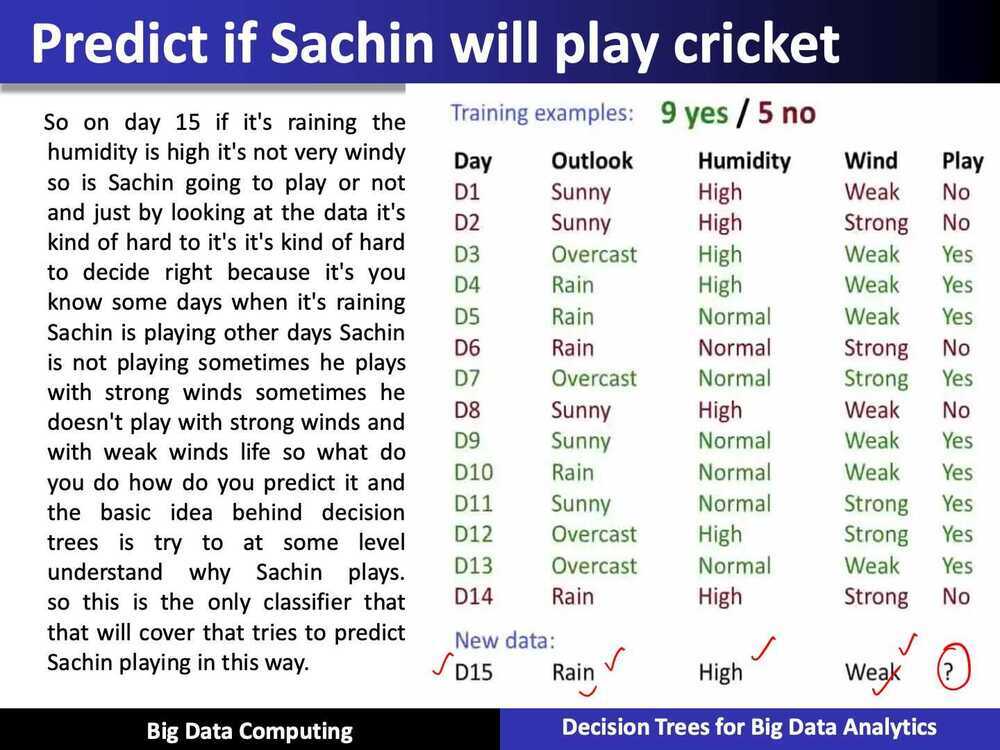
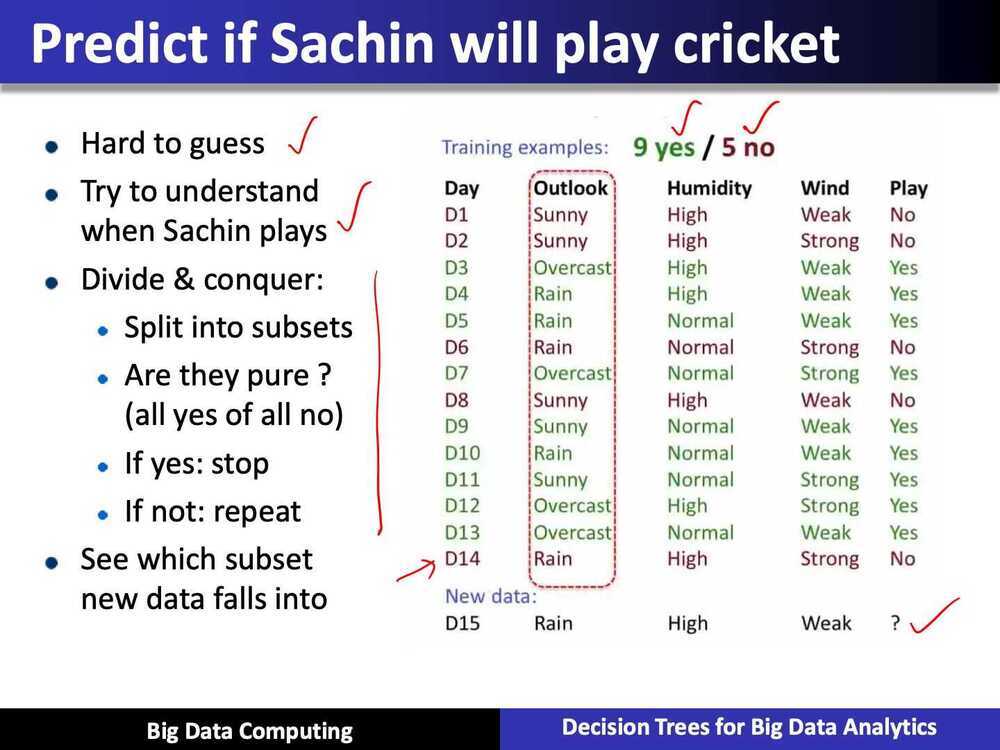
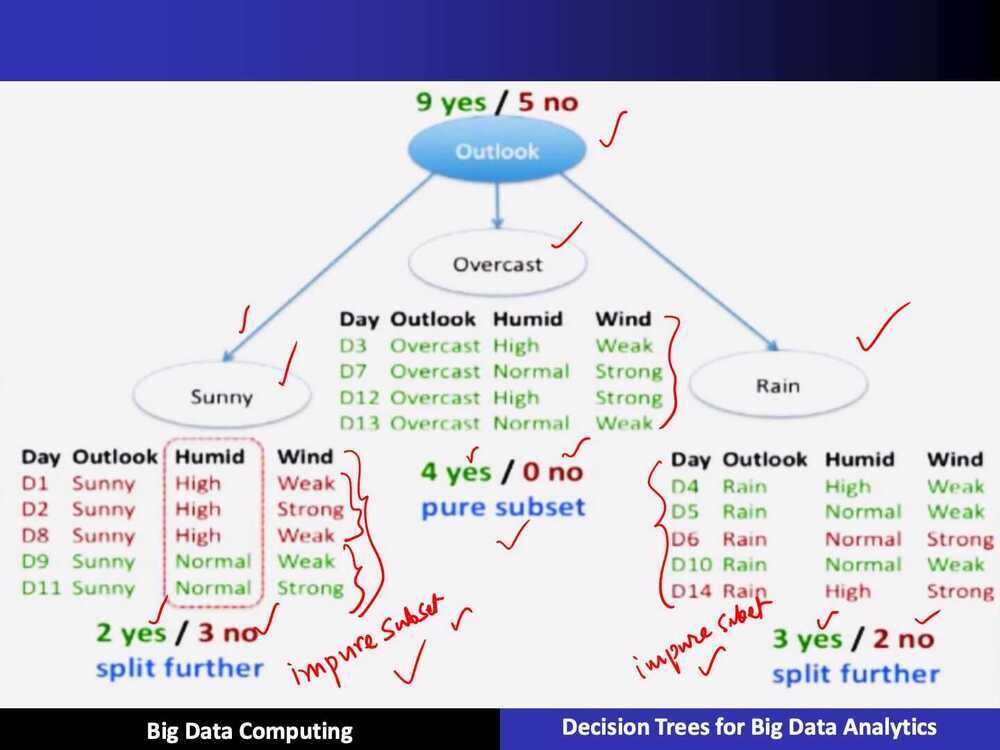
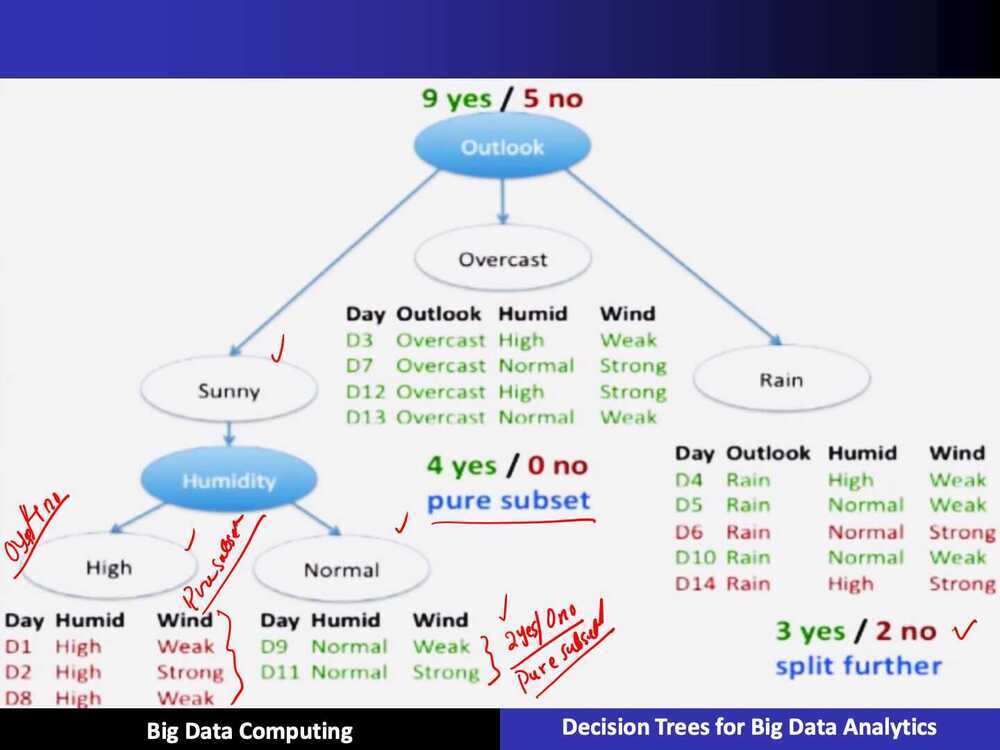
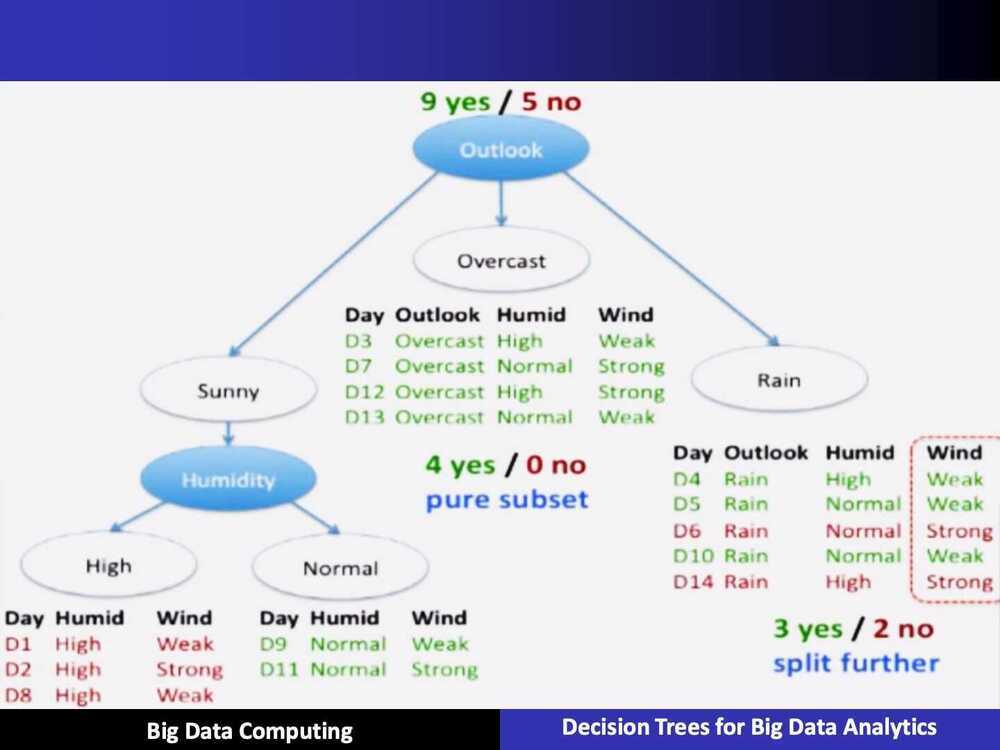
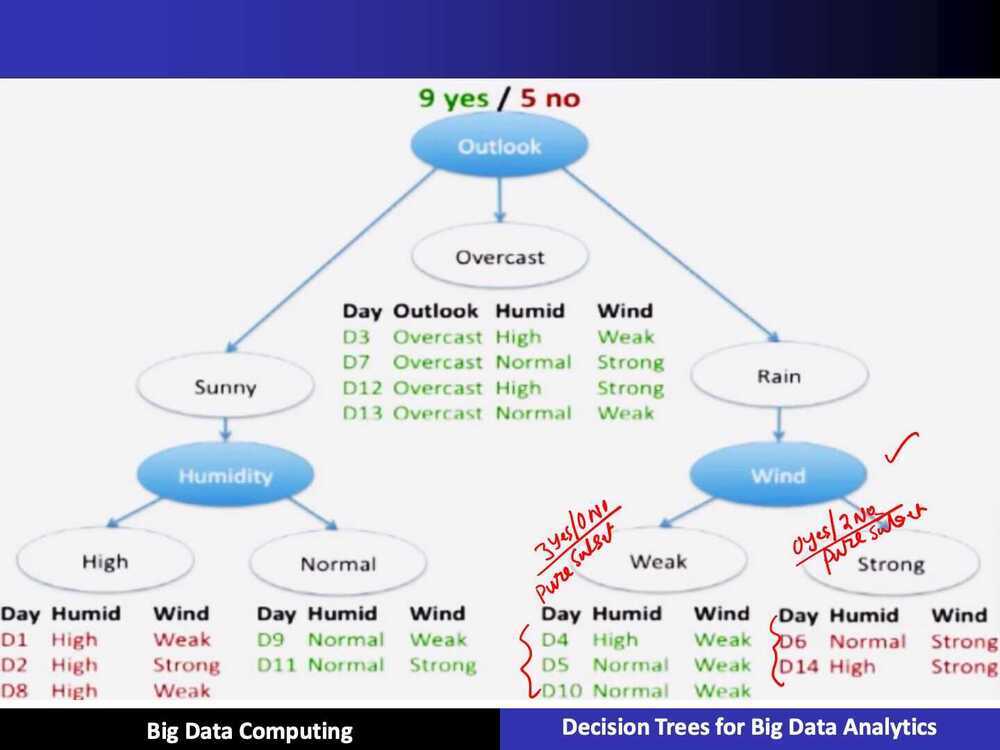
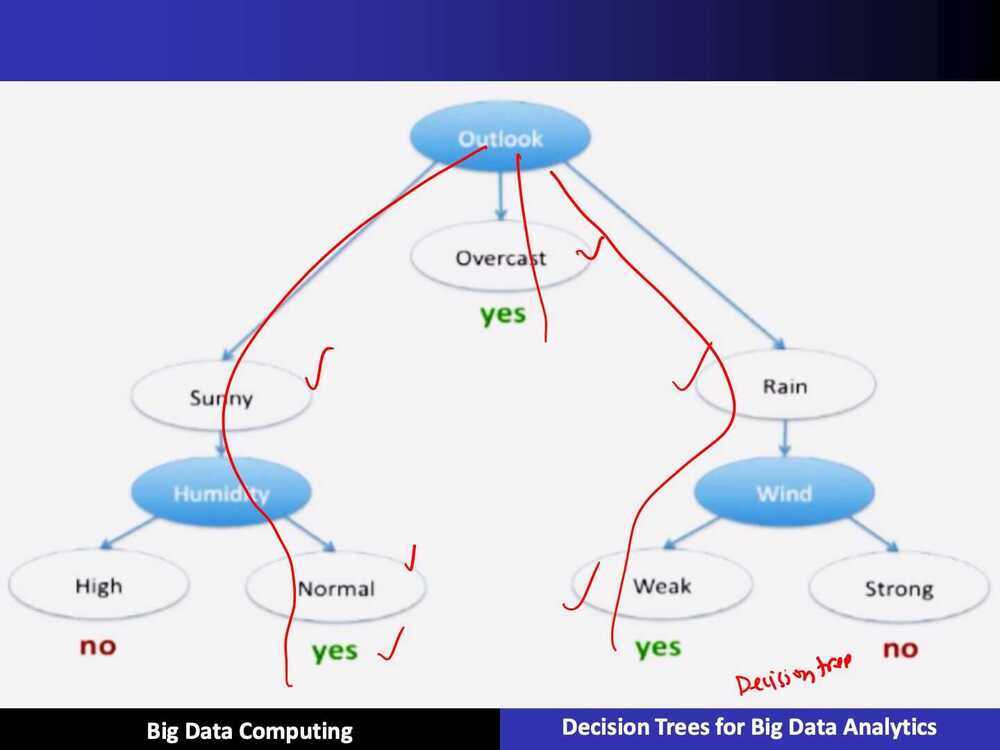
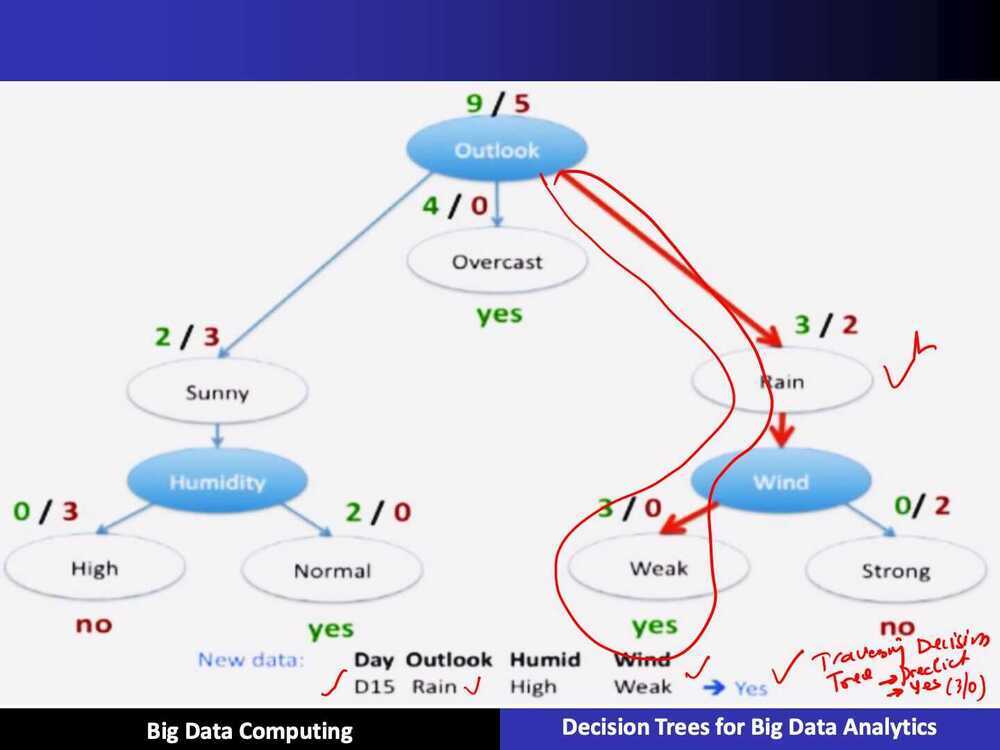
ID3 Algorithm
-
In decision tree learning, ID3 (Iterative Dichotomiser 3) is an algorithm invented by Ross Quinlan used to generate a decision tree from a dataset. ID3 is the precursor to the C4.5 algorithm, and is typically used in the machine learning and natural language processing domains
-
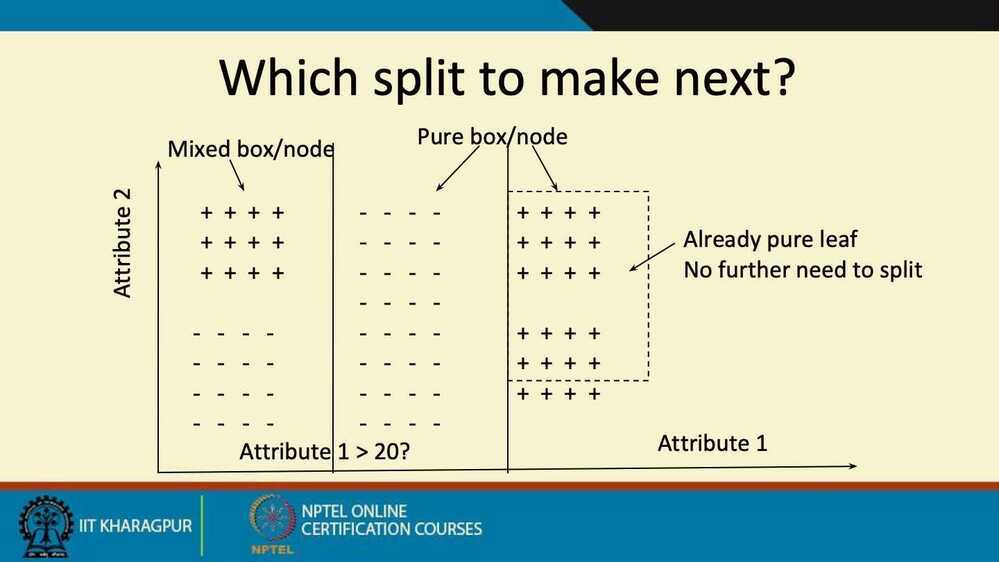
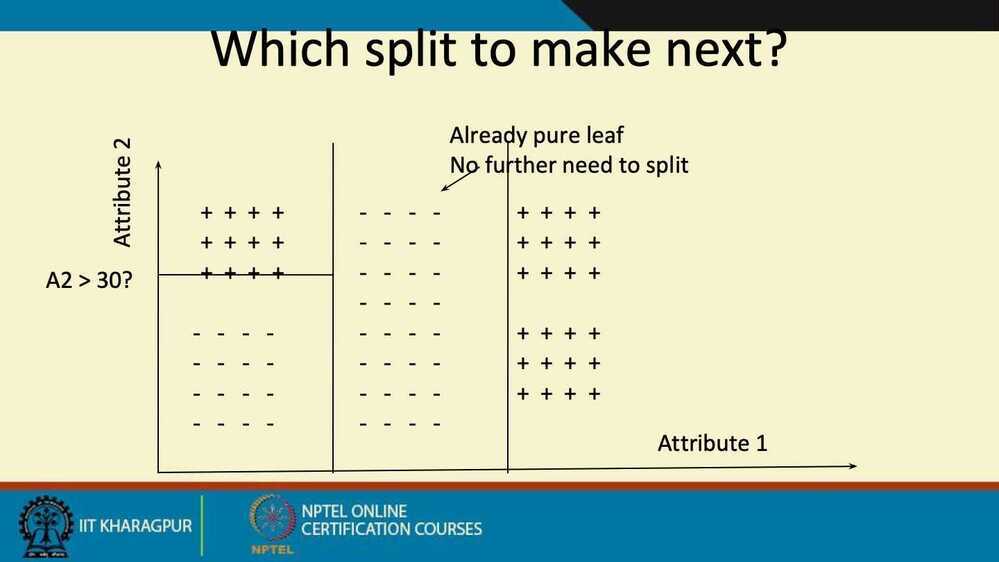
Split (node, examples):
- A - the best attribute for splitting the examples
- Decision attribute for this
node <- A - For each value of A, create new child node
- Split training examples to child nodes
- For each child node/subset:
- if subset is pure: STOP
- else: Split
(child_node, {subset})
-
Ross Quinlan (ID3: 1986), (C4.5: 1993)
-
Breimanetal (CaRT: 1984) from statistics


https://towardsdatascience.com/entropy-and-information-gain-in-decision-trees-c7db67a3a293
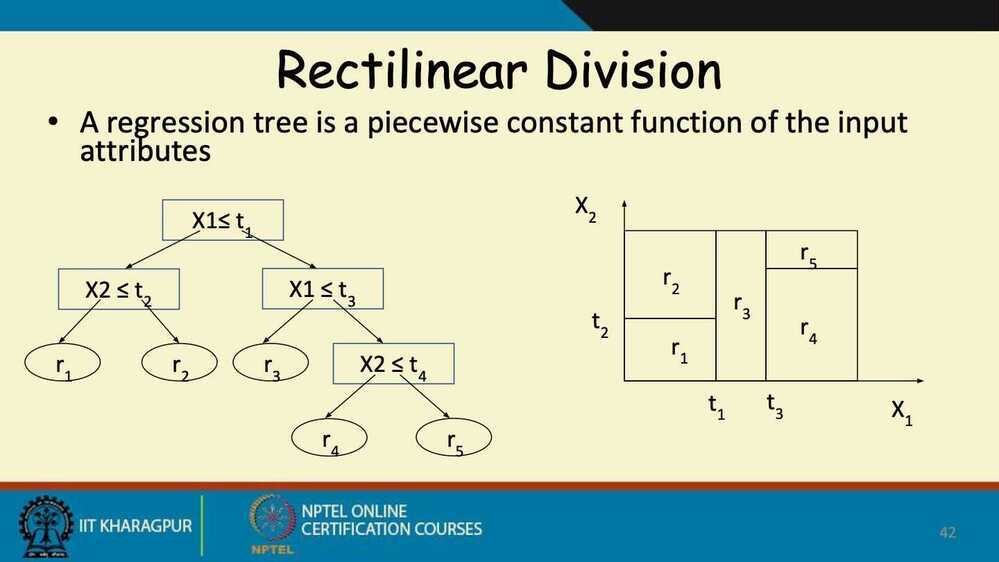
Decision Trees for Regression
How to grow a decision tree
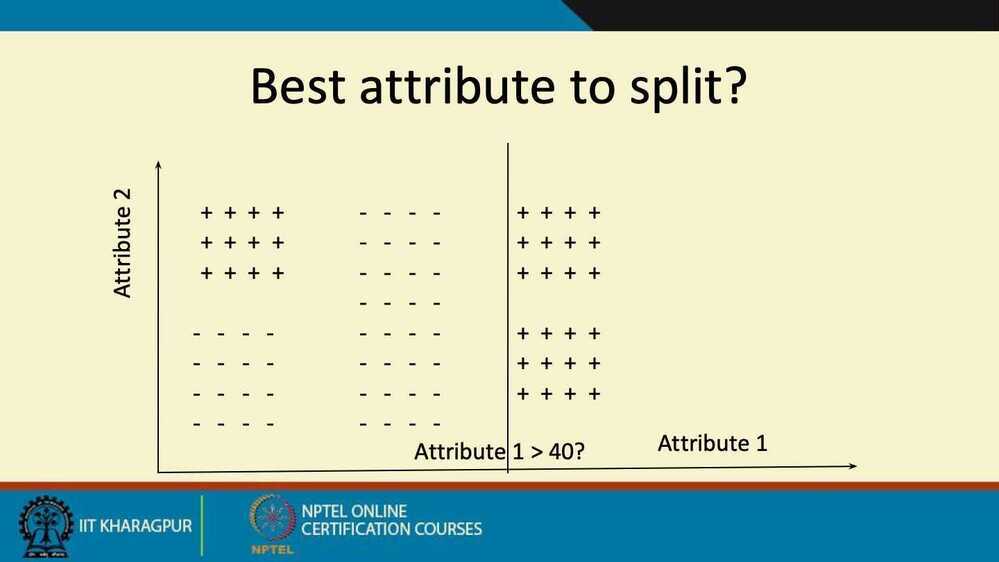
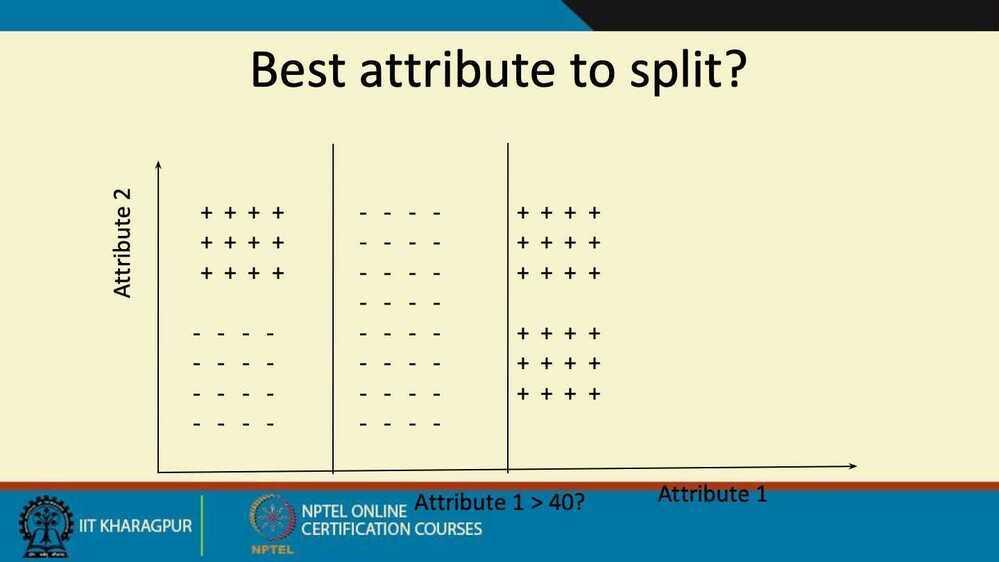
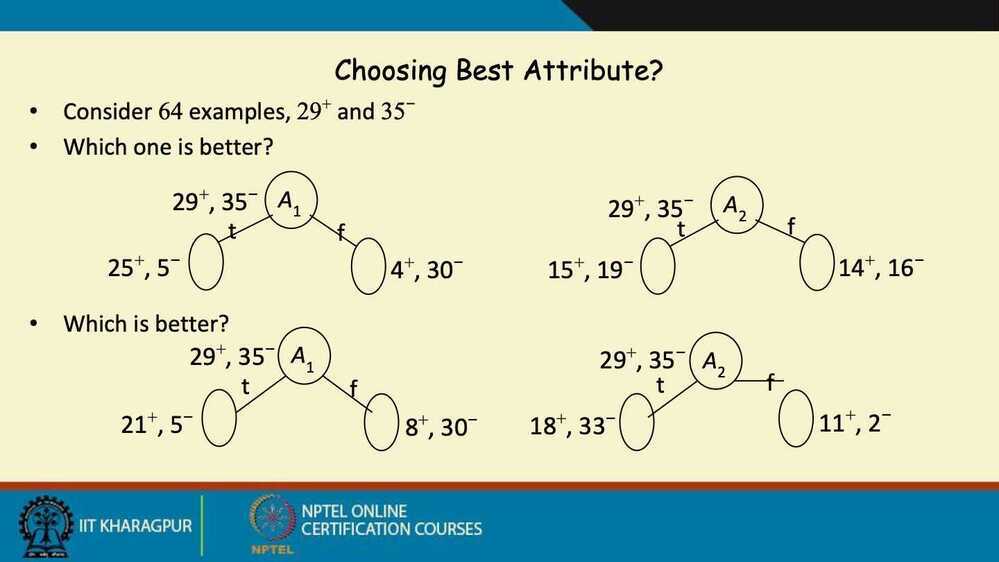
- The tree is built greedily from top to bottom
- Each split is selected to maximize information gain (IG)

- Given a training set:
Z = {(X1, Y1),...., (Xn, Yn)}
yi-real values
- Goal is to find f(x) (a tree) such that

- How to grow a decision tree for regression?
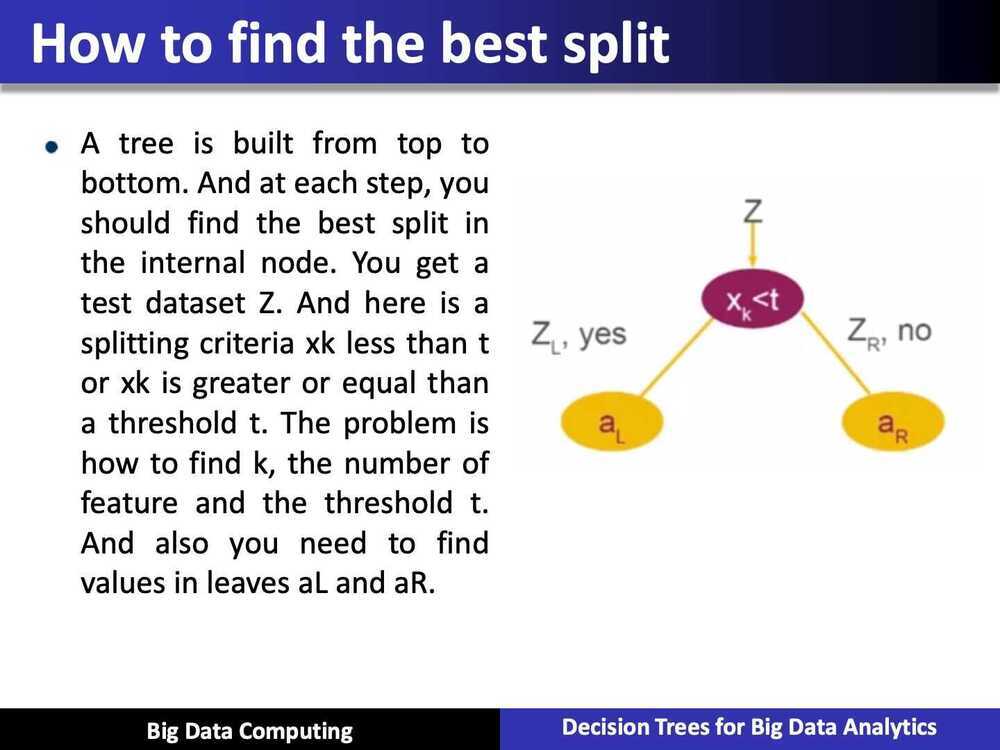



Stopping rule
- The node depth is equal to the maxDepth training parameter
- No split candidate leads to an information gain greater than mininfoGain
- No split candidate produces child nodes which have at least minInstancesPerNode training instances
(|ZL|, |ZR| < minInstancesPerNode)each
Summary: Decision Trees
- Automatically handling interactions of features
The benefits of decision tree is that this algorithm can automatically handle interactions or features because it can combine several different features in a single decision tree. It can build complex functions involving multiple splitting criteria
- Computational scalability
The second property is a computational scalability. There exists effect of algorithms for building decision trees for the verfy large data sets with many features
- Predictive power
Single decision tree actually is not a very good predictor. The prediction power of a single tree is typically not so good
- Interpretability
You can visualize the decision tree and analyze this splitting criteria in nodes, the values in leaves, and so one. Sometimes it might be helpful
Building a tree using MapReduce
PLANET (Parallel Learner for Assembling Numerous Ensemble Trees)
- A sequence of MapReduce jobs that build a decision tree
Attribute Instance Matrix
-
Binary Classification Problem
-
K-class problem
-
Classification problem is a part of Supervised learning algorithm










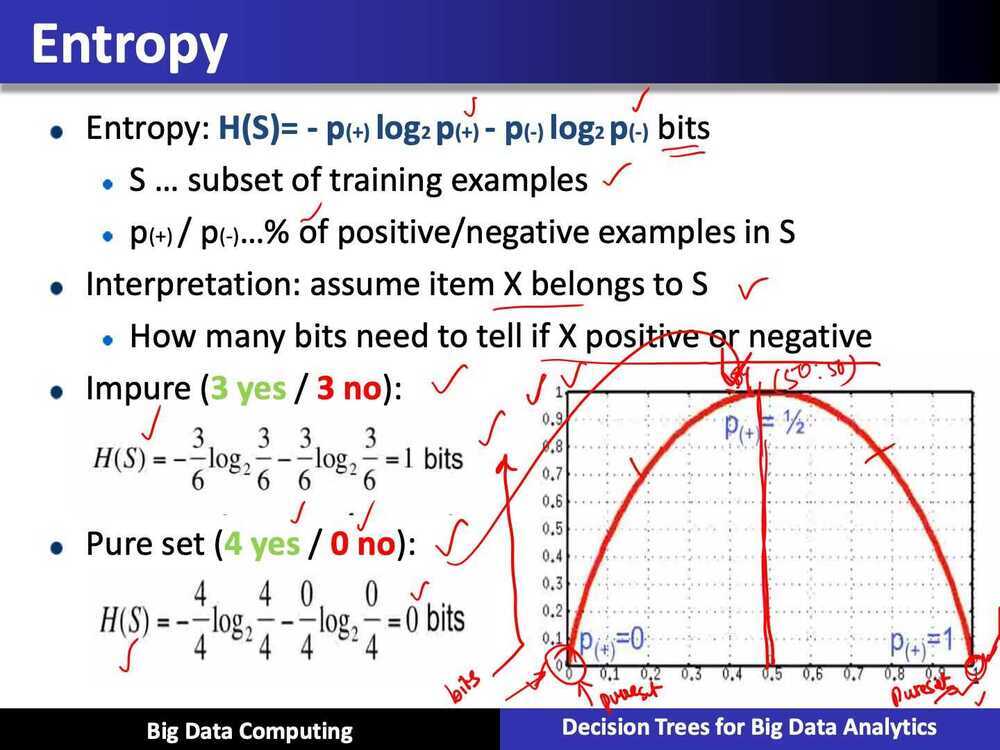
when p+ = 1 and p- = 0 or p+ = 0 and p- = 1, i.e. pure classes then the entropy is lowest i.e. 0
When p+ = 0.5 and p- = 0.5, i.e. even split between classes, then entropy is highest







CHAID Algorithm - Chi-Squared Automatic Interaction Detection





CART Algorithm - Classification and Regression Tree
When are Decision Trees useful?
- Advantages
- Very fast: can handle very large datasets with many attributes
- Flexible: serveral attribute types, classification and regression problems, missing values
- Interpretability: provide rules and attribute importance
- Disadvantages
- Instability of the trees (high variance)
- Not always competitive with other algorithms in terms of accuracy
Summary
- Decision trees are practical for concept learning
- Basic information measure and gain function for best first search of space of DTs
- ID3 procedure
- Search space is complete
- Preference for shorter trees
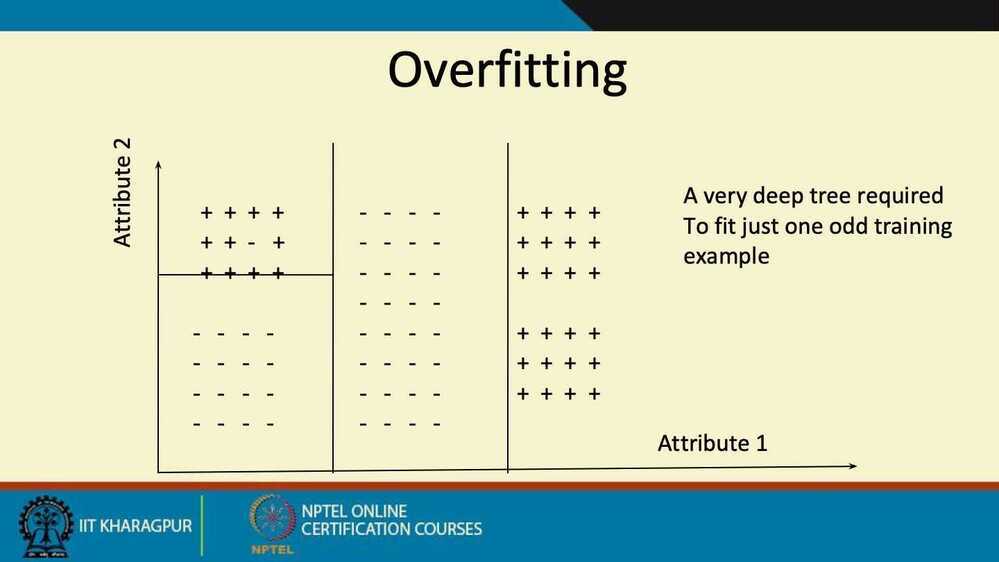
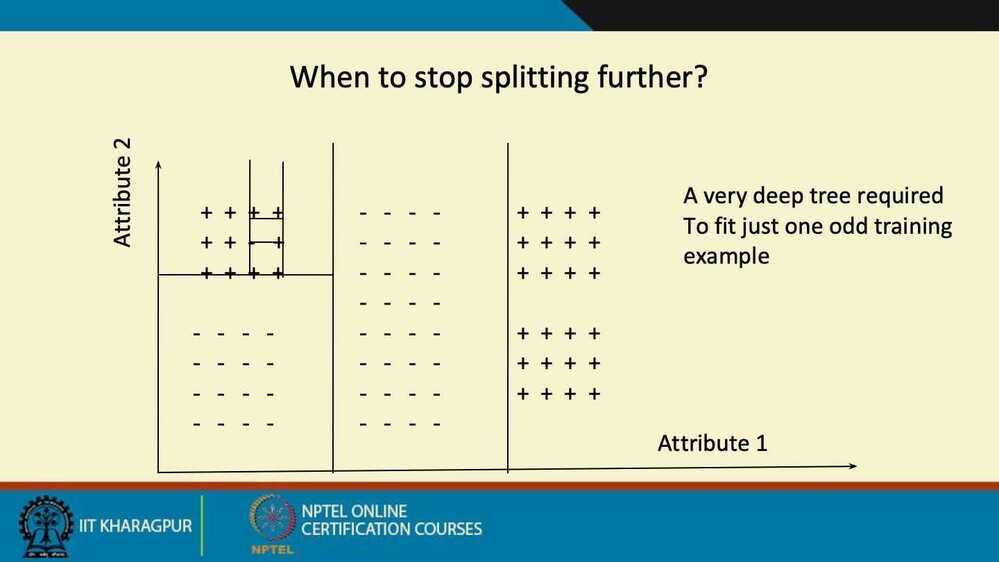
- Overfitting is an important issue with various solutions
- Many variations and extensions possible
Software
- In R: packages tree and rpart
- C4.5
- Weka
https://medium.com/@rishabhjain_22692/decision-trees-it-begins-here-93ff54ef134
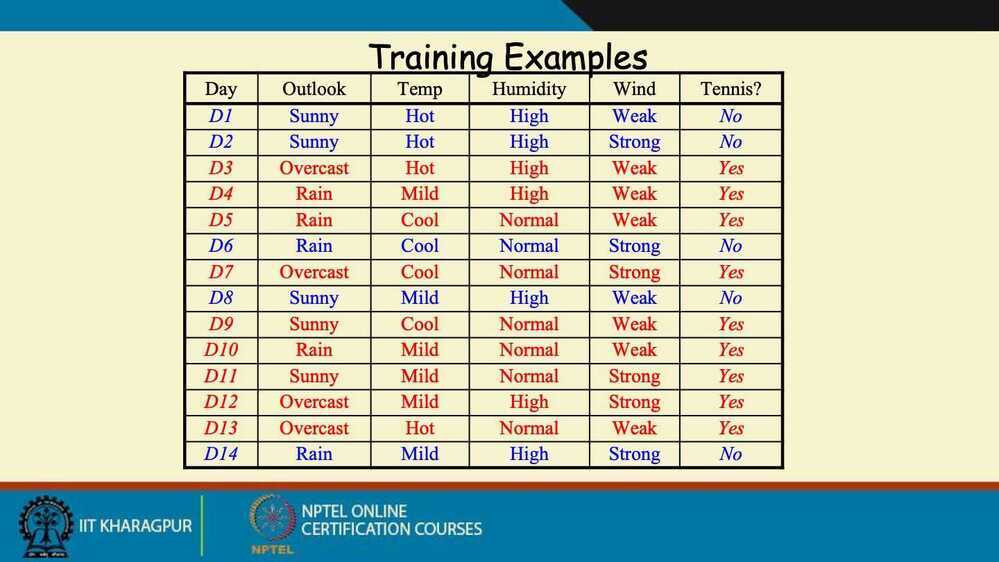
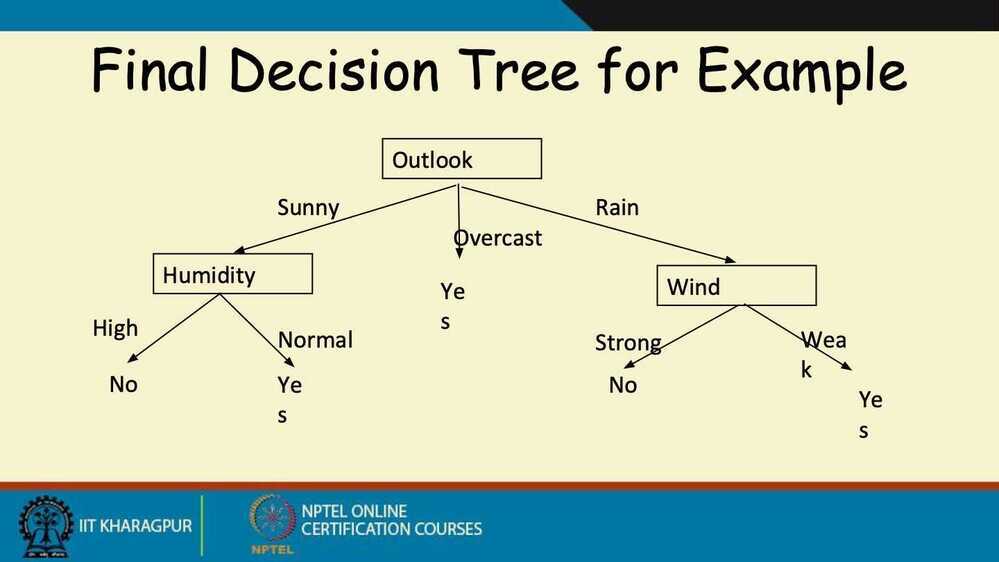
Decision Trees
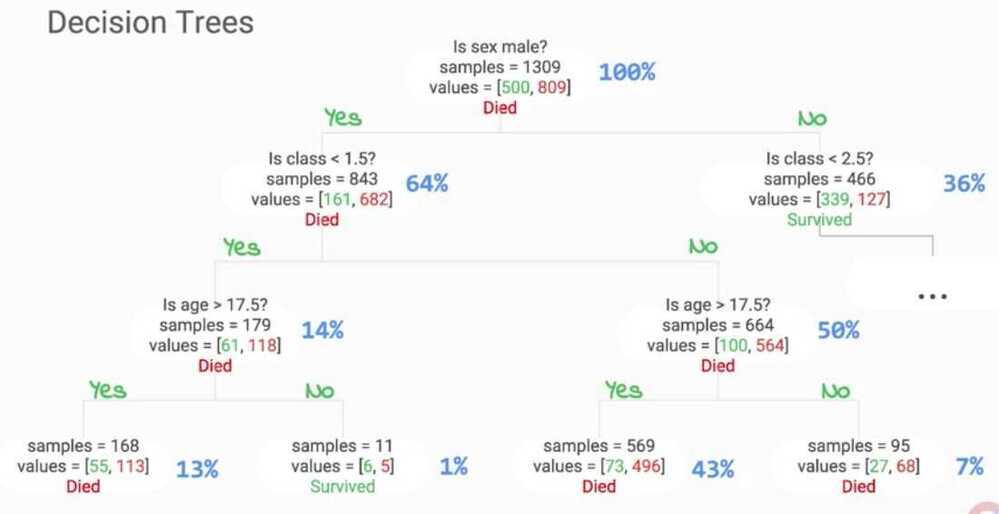
Decision tree for titanic dataset for who lived and who died

https://towardsdatascience.com/decision-tree-ba64f977f7c3
Intro to XGBoost Models (decision-tree-based ensemble ML algorithms)
XGBoost (eXtreme Gradient Boosted trees)
- Boosting is an ensemble method
- Each tree boosts attributes that led to misclassifications of previous tree
- It is amazing
- Routinely wins Kaggle competitions
- Easy to use
- Fast
- A good choice for an algorithm to start with
Decision Trees

Example


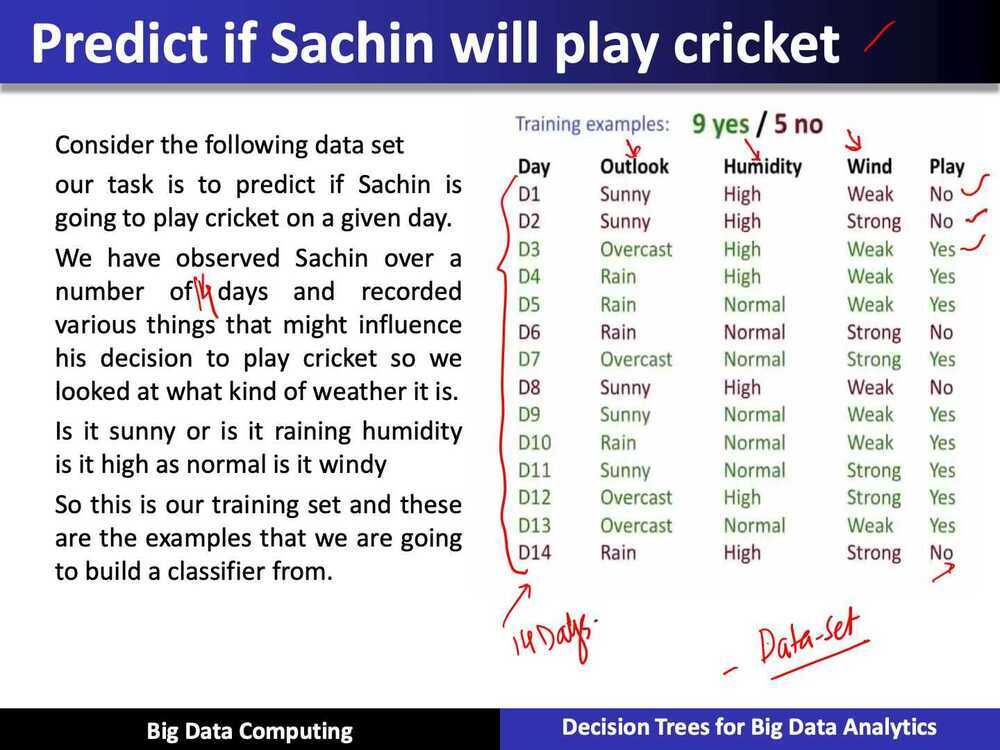
How Decision Tree works

Random Forests

Ensemble Learning


Features of XGBoost