WooCommerce AI Assistant Insights
Overview
A production-ready, multi-agent AI system that brings conversational intelligence to e-commerce store management. Built entirely through vibe coding using Claude Code's GSD workflows, this project demonstrates rapid iteration on complex AI architecture while maintaining production quality.
Development Approach
Built with: Claude Code + GSD Workflows (Get Stuff Done)
Methodology: Vibe coding - product-first thinking with AI-assisted architecture
Every feature was developed through conversational prompting, leveraging GSD's systematic workflow orchestration to maintain consistency across rapid iterations. The entire codebase emerged from natural language specifications, with Claude Code handling architecture decisions, implementation, and optimization.
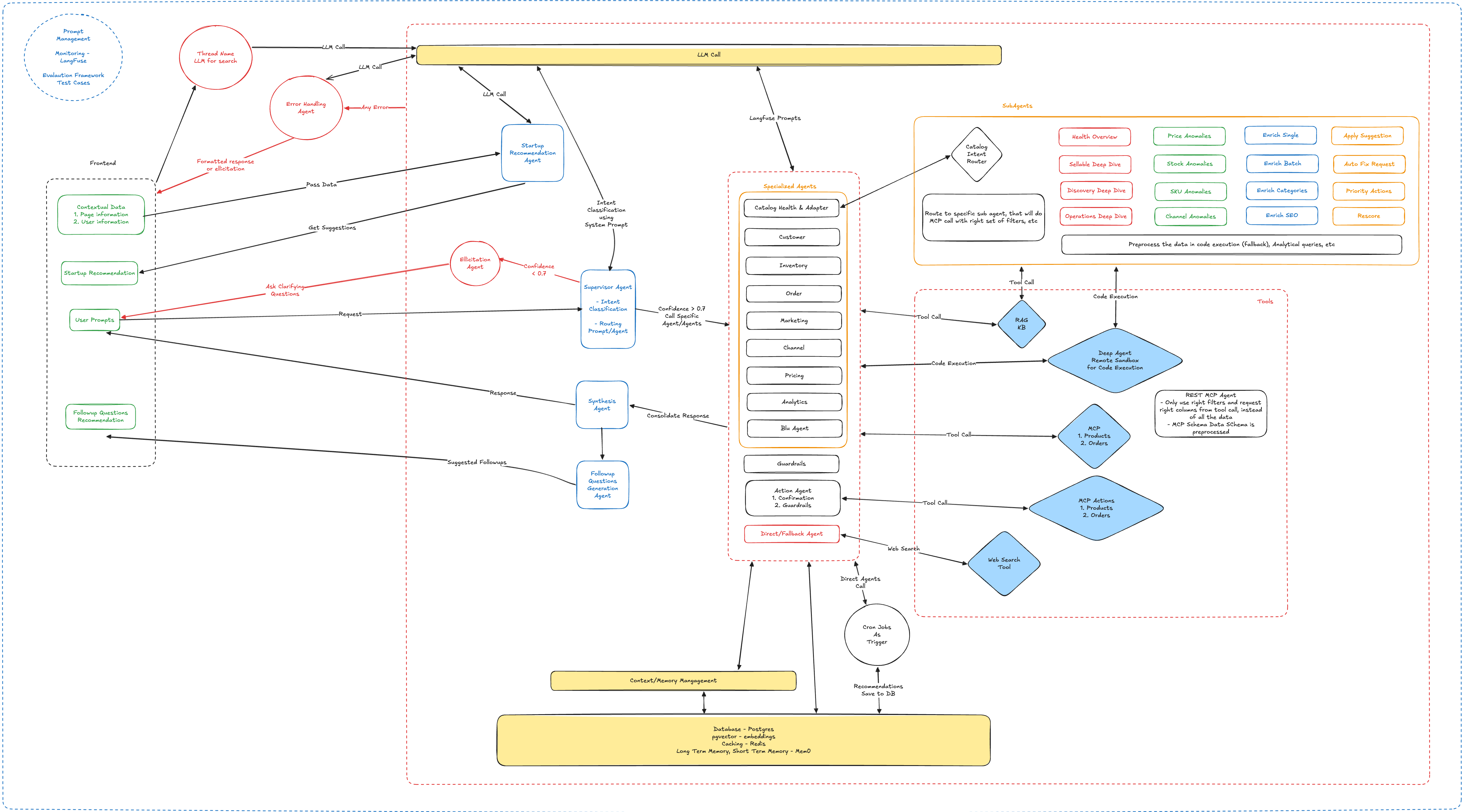
Technical Architecture
Multi-Agent System Design
Router/Supervisor Pattern
- Central orchestrator classifies user intent and delegates to specialist agents
- Dynamic routing based on query analysis and conversation context
- Automatic fallback chains for graceful degradation
Specialist Agents
- Action Execution Agent: Product/order CRUD operations via WooCommerce API
- Catalog Health Agent: LLM-driven product quality scoring across multiple dimensions
- Knowledge Base Agent: Agentic RAG system for platform documentation
- General Chat Agent: Conversational fallback with contextual awareness
State Management & Persistence
LangGraph Checkpointer + PostgreSQL
- Conversation state persisted per thread with automatic serialization
- Resume conversations across sessions without context loss
- Branching conversation support with message tree navigation
Long-Term Memory (mem0ai + pgvector)
- Semantic memory storage with vector embeddings
- Automatic context retrieval based on conversation relevance
- User preference learning over time
Real-Time Communication Stack
WebSocket + SSE Hybrid
- Token-by-token streaming for instant feedback
- Tool call visualization during execution
- Bidirectional events for clarification questions
- Automatic reconnection with exponential backoff
- Event replay prevents message loss
LLM Resilience & Optimization
Multi-Model Fallback Strategy
- Circular fallback across OpenAI models (GPT-4 → GPT-4-Turbo → GPT-3.5-Turbo)
- Automatic retry with exponential backoff via Tenacity
- Rate limit handling with queue-based throttling
Prompt Engineering
- Langfuse-hosted prompt versioning with A/B testing capability
- Structured output parsing with Pydantic validation
- Context window optimization through dynamic summarization
Observability
- Full LLM trace collection via Langfuse
- Token usage tracking per agent and tool call
- Latency metrics for optimization feedback loops
Tech Stack
Backend Core
- FastAPI - High-performance async API framework
- LangGraph - Agent workflow orchestration with state machines
- LangChain - LLM abstraction and tool integration
- PostgreSQL 16 + pgvector - Relational data + vector storage
- SQLModel - Type-safe ORM (SQLAlchemy + Pydantic)
- mem0ai - Long-term memory framework
- Langfuse - LLM observability platform
Frontend Core
- Next.js 16 - React framework with app router
- assistant-ui - Production-ready chat components
- TailwindCSS + Radix UI - Accessible, composable UI system
- WebSocket Client - Real-time bidirectional messaging
Infrastructure
- Docker + Docker Compose - Containerized deployment
- uv - Blazing fast Python package manager
- structlog - Structured JSON logging
- SlowAPI - Redis-backed rate limiting
Key Optimizations
1. Connection Pool Tuning
- PostgreSQL connection pool sized per environment (dev: 5, prod: 20)
- Connection recycling every 30 minutes prevents stale connections
- Graceful degradation when pool unavailable (logs warning, continues)
2. Async-First Architecture
- Fully async database operations with asyncpg
- Non-blocking LLM calls with streaming
- Background task processing with asyncio
3. Smart Memory Retrieval
- Semantic search limited to top-k relevant memories (default: 5)
- Hybrid retrieval: vector similarity + recency weighting
- Memory updates batched and async to avoid blocking chat
4. Streaming Optimizations
- Chunked token delivery (every 5-10 tokens for perceived speed)
- Tool call streaming with partial result visualization
- SSE keepalive prevents connection timeouts
5. Error Boundary Design
- Agent failures isolated per workflow node
- Supervisor catches agent errors and routes to fallback
- Frontend retry logic with user-visible status
Data Flow Architecture
User → WebSocket/HTTP → Auth Middleware → Rate Limiter
↓
Session Validation → Thread Retrieval → Memory Loading
↓
Router/Supervisor → Intent Classification → Agent Selection
↓
Agent Execution → Tool Calls → LLM Reasoning → Memory Update
↓
Response Streaming → State Checkpoint → Client Update
Security & Reliability
Authentication
- JWT-based auth with refresh token rotation
- Session-scoped access control
- Token expiry with automatic renewal
Input Validation
- Pydantic schema validation on all inputs
- SQL injection prevention via parameterized queries
- XSS protection through sanitization utilities
Rate Limiting
- Per-user request throttling via SlowAPI
- Redis-backed distributed rate limiting
- Configurable limits per endpoint
Error Handling
- Structured exception hierarchy with HTTPException
- Context-aware logging with request tracing
- User-friendly error messages (never expose internals)
Development Velocity Highlights
Built with GSD Workflows:
- Phase-based development with automatic plan generation
- Verification loops before merging (goal-backward validation)
- Atomic git commits per task for clean history
Iteration Speed:
- Entire multi-agent system scaffolded in 2 days
- WebSocket real-time chat added in 1 day
- Frontend chat UI with branching in 2 days
- Production optimizations iterated over 1 week
Quality Maintenance:
- Type safety enforced via Pydantic + TypeScript
- Structured logging from day 1
- Langfuse observability integrated early for debugging
What Makes This Different
AI-Built AI System: Every line of code emerged from conversational prompting. Architecture decisions, optimization strategies, and debugging were all collaborative efforts between developer and AI.
Production-Ready from Start: GSD workflows enforced best practices by default - structured logging, error handling, type safety, observability. No "rebuild for production" phase.
Iteration Without Friction: Changes that would take hours in traditional development (e.g., adding agent, refactoring state schema) completed in minutes through natural language specs.
Vibe Coding Philosophy: Focus stayed on "what should this do?" rather than "how do I implement this?". Claude Code handled implementation details, patterns, and optimizations.
- Tech Snapshot: Python 3.13, FastAPI, LangGraph, Next.js 16, PostgreSQL 16, OpenAI GPT-4, WebSockets, Docker
- Development Time: ~2 weeks from zero to production-ready
- Built By: Developer + Claude Code (Opus 4.6) using GSD workflows
- Deployment: Docker Compose → Cloud VM (single-command deploy)