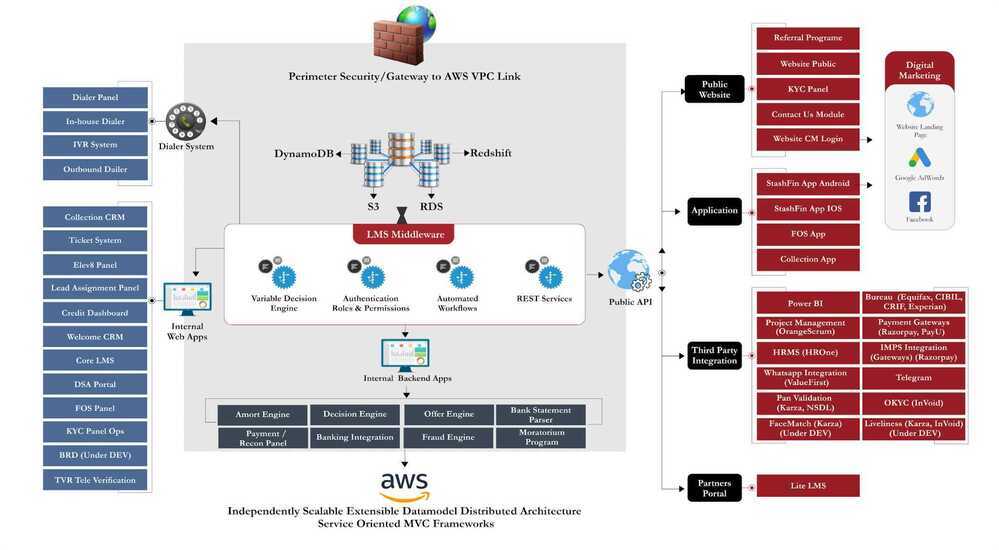
On this page
Stashfin Onboarding Process Overview NBFC / Banking Terms
Day 1 = Explain the product fully, along with installation and hands-on usage with feedbacks if possible
Day 1 = Clearly explain on what is our current architecture and processes we are following, introduce to team + manager + onboarding buddy
Day 2 = Let person review the architecture diagrams + docs of the team which you are joining + tell him the 1st task he will be working on, and exact 1st commit/feature deploy he has to do.
Day 3-7 = how is the task going, what problems person is facing, and show him the right path or right person to speak to.
Start incrementally given difficult tasks, and then assign few junior devs to start managing, if person prefers
Migrate all APIs - Type Hint
LMS main search and page migrate using Django Admin
Migrate everything to Python (Django + Flask)
Cron jobs + APIs (Every <10 mins cron must be removed)
UserDevice data
Authentication & authorization system
Logging / Monitoring / Scalability
Redis Queue for event based system
Every <10 mins cron must be removed
DB Break into multiple components (start moving schema to multiple schemas)
DB data consistency (column contraints)
Data Models ER Diagram with Foreign Key Contraints
Private database
Increase Isolation level
Single database for applications, no reader/writer config (till we really hit that scale), upgrade db, postgres
Remove DMS and Redshift (on-line aggregations)
Product overhaul - end to end with highly deterministic flow and real time monitoring at every single step
Fraud at each step without performance implications
Full customer logging and path traversal along with historical data
Product flow - Figma
Paytail modern app
Testing at each path (Testing apps, and flows easily)
Democratize analytics (use redash)
Quality of code increase, quantity of code decrease, UAT, Testing, No regressions
Documentation and knowledge base and onboarding wiki
AI Team
Payments (2 people)
Decision Engine (2 people)
External Mobile APIs + API Gateways (2 people)
LMS in Django
Collections in Django
LiteLMS in Django
Communications (done)
KYC (Django)
LMS - Lead search and status
Frontend team
All tests will be local
databases will be running locally for some of the stuff
There will be a test aurora database with fake PII data and other stuff, developers wil not get access to dailydb, or prod
Right database for the right job
Only ACID guarantees things will be saved in mysql, others will not be
Move all emails, msgs, notifications to pinpoint
Security implemented correctly
No unsecured credentials in local (only test db credentials, test s3 bucket access credentials)
Microservices architecture
Remove LMS
Moving from reactive to proactive actions
Event based architecture
Break the database
Only MySQL and Redis database
Redshift for Analytics
No T-1 database
No reader and writer access for users to databases
No database more than 8/16 GB
Android - MultiLingual
AI models at the edge
All branches must be master only (so that repositories must be small enough)
Remove each different frontend to a different backend repository
Create hierarchy of people, and every team will have 4 person team, with one team lead. (more juniors then seniors)
Create a flat hierarchy with very good people like Vishal, Ankur, that are self managed (very limited interns and all) - keep number of people to 10/12 i.e. whole engineering team - This will help us go fully remote, hire better developers
Save all logs and everything to aurora, either move data from aurora to redshift using DMS
Do analytics on T-1, dumped s3 data or redshift
Maintenance script dump data to s3 and delete from mysql
Do analytics on s3 or redshift
logging to files instead of database and then sent via a sidecar
Decouple data processing from storage
Multiple databases will be used across multiple modules, each selected for query performance and best way to save data
Each data can be processed multiple times according to requirements
data can land in multiple places
storage is cheap
compute is expensive
denormalize database
query must be performant
Compacted and stored in long term storage solutions
Analysis must be done to get analytics (like no. of finance apps, etc) from the data and saved into a OLAP/OLTP database
Can be parsed and an event can be triggered according to some condition
Can be stored in a transaction database
Two types of aggregations
On the fly aggregations (aggregations performed before/while storing data)
On demand aggregations (done by data science team for creating reports)
High CPU compute queries that are done often must be moved from on-demand to on-the-fly aggregations
We have to cater to both read-heavy workloads and write-heavy workloads
Tiered storage
In-memory storage (1 - 4 weeks data)
Relational/non-relational disk based storage based on SSD (1 year data)
Compressed and saved on tape/HDD for long term storage (greater than 1 year data)
Have a event driven workflows
Android/PHP pushes all apps raw data to Kafka/Kinesis
Consumer consumes and add to DynamoDB by updating the cust_id as csv of apps for LTS
Consumer consumes, parses and add apps analytics to mysql/wide column (like total number of apps, types of apps - finance, gaming, others)
Consumer consumes, and puts to types of apps in global pool
Android/PHP pushes all sms raw data to Kafka/Kinesis
Consumer consumes and saves raw data (cust_id, sms_time as primary key) to dynamoDB for LTS
Consumer consumes and parses data for bank sms and save to mysql/wide column for analytics
High fanout (like one sms will be sent to lakhs of customers)
SMS template/Email template/Notification template must be enriched before sending
adding the amount that the customer is eligible for
adding customer specific links
All communications/clicks/engagement should be tracked
OLTP for transactional loads (that needs join)
OLAP for analytical loads
In memory key value for very fast lookup
Key-value NoSQL for fast lookups (not transactional data)