Scalable Data Stack for E-Commerce
Scalable and Cost-Efficient Modern Data Stack on GCP for a High-Growth E-Commerce Platform
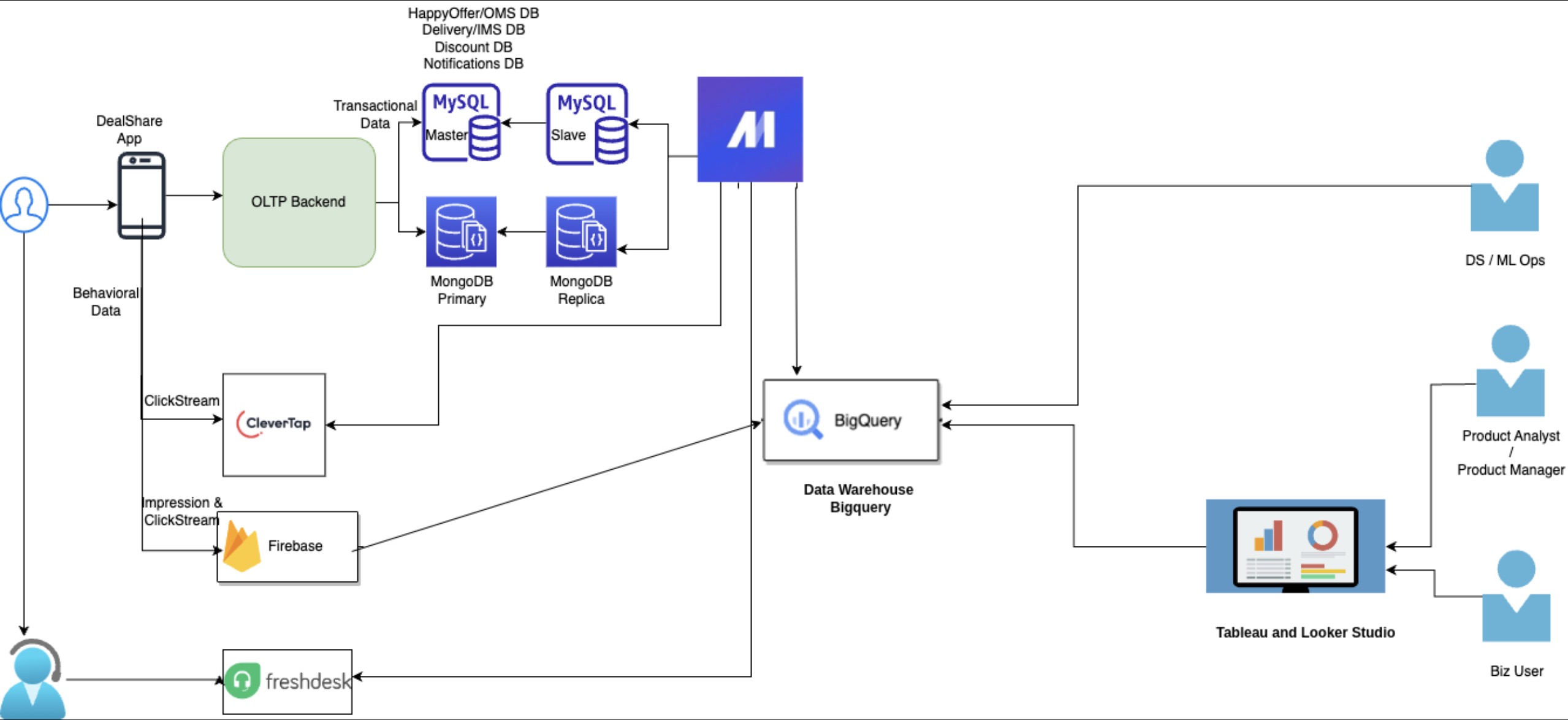
Overview
We partnered with a high-growth e-commerce player to modernize their data infrastructure by migrating from AWS Redshift to Google Cloud Platform (BigQuery), enhancing cost efficiency, query performance, and analytical capabilities. The project was designed to support large-scale data ingestion, reporting, and seamless analytics for business, product, and ops teams.
Key Highlights
1. Seamless Migration from Redshift to BigQuery
- Translated 100% of legacy Redshift SQL queries to BigQuery SQL, ensuring functional equivalence and improved efficiency.
- Successfully migrated data models and pipeline orchestration without business disruption.
- Migrated orchestration from manual and AWS-native jobs to Mage, enabling modular, maintainable workflows with robust failure handling.
2. Query & Cost Optimization
- Applied partition pruning and optimized schema design, reducing average query scan size from 98 GB to 2 GB — a 97.9% reduction.
- Introduced slot reservations and commitments, transitioning from on-demand pricing to a predictable cost model ~19.6% daily cost reduction
- Enabled batch query processing for analyst teams, reducing compute contention and improving throughput.
3. Proactive Monitoring & Alerting
- Implemented comprehensive monitoring for slot utilization and long-running queries.
- Integrated Mage with Slack alerting to notify stakeholders of pipeline failures and threshold breaches, ensuring all issues are actionable.
- Enabled external alerts for system health, pipeline status, and data delays, reducing response time and downtime impact.
4. Robust Data Engineering Foundation
- Built a centralized BigQuery warehouse ingesting from:
- Transactional databases (e.g., MySQL)
- External APIs (e.g., marketing attribution, customer support)
- Event streams and files via GCS scheduled transfers
- Designed scalable scheduled queries and transfer jobs, with audit logging enabled for governance.
- Set up Kafka publishing from BigQuery for event distribution to external systems.
- Established data delivery to third-party APIs for downstream applications.
5. Governance & Access Management
- Implemented IAM policies to ensure secure, role-based access across development, analytics, and business teams.
- Implemented data masking on sensitive fields to ensure compliance with internal access policies.
- Enabled audit logging for data access and query usage, supporting compliance and operational audits.
6. BI & Analytics Enablement
- Created robust and failure-proof dashboards using Tableau and Google Looker Studio, connected to BigQuery marts.
- Established a scalable semantic layer with clean joins, hierarchies, and measures—reducing dashboard load failures to zero.
- Delivered automated alerts for data freshness and SLA breaches in reporting layers.
7. Architecture Excellence
- Adopted Medallion architecture (Bronze, Silver, Gold layers) for clean data separation and better model traceability.
- Leveraged GCS buckets for ingesting raw and semi-structured files, with scheduled pipelines converting these to structured BigQuery datasets.
8. Product Intelligence Enablement
To drive user engagement, product discovery, and conversion, we built a scalable, data-driven personalization layer across two high-impact surfaces: the Product Display Page and the Buy Again widget.
Product Display Page – Smart Recommendations
We implemented a modular recommendation system to surface relevant collections based on real-time product context and user affinity:
- Similar Items: Recommended based on weighted similarity logic—product attributes (weight, price range), brand affinity, margin potential, and deal availability. Impression penalties deprioritize low-performing items seen but not added to cart.
- Top Selling Products in Category: Highlights popular SKUs from the same L3 category, filtered for performance and relevance.
- Brands in Category: Enables brand-driven navigation by surfacing available brands in the same category.
Each collection is conditionally rendered (only when sufficient relevant items are found) and A/B test ready, with tunable weights managed through experimentation platforms to continuously optimize performance.
Buy Again Widget – Behavioral Optimization
With over 60% of Add-to-Bag actions originating from this widget, we enhanced its effectiveness through a predictive scoring model that uses:
- Recency: Higher priority for items nearing replenishment based on last purchase timing.
- Frequency: Preference for frequently purchased items to promote habitual restocking.
- Replenishment Score: Predictive logic estimating when the item is due again, based on past purchase intervals.
- IsDeal Flag: Items with active promotions are ranked higher to encourage faster conversions.
- Dynamic Weighting: Applied differentiated scoring logic for monthly cycles—boosting replenishment in early-month buying phases and frequency in late-month budget phases.
Detailed position-level analysis of user engagement revealed a significant performance drop beyond position P2, influencing widget layout and logic refinement to maximize Add-to-Bag rate from top-ranked items.
9. Fraud Pattern Detection & Prevention
To strengthen platform integrity and reduce financial leakage, we developed a robust, data-driven framework targeting fraudulent activity, specifically multi-account abuse via shared delivery addresses.
- Same Address, Multiple Users: Leveraged a combination of address normalization, MD5 hashing of cleaned addresses, and latitude/longitude rounding to create composite grouping keys. This enabled identification of multiple distinct users ordering from effectively the same location, uncovering fraud rings and repeated exploitation of promotions or new-user benefits.
- Composite Grouping & Deduplication: Applied grouping logic to cluster suspicious user accounts sharing normalized addresses, filtering to focus on groups with more than one unique user. Further collapsing duplicate address groups helped simplify investigation efforts.
- Impact: This solution improved early fraud detection, minimized promo misuse, and reinforced user eligibility policies, contributing to significant financial savings and healthier platform operations.
Outcomes
| Area | Impact |
|---|---|
| Query Efficiency | Query scan size reduced by ~98% through partition pruning |
| Cost Savings | Slot commitment reduced cost by ~20% |
| System Reliability | Zero dashboard failures post-launch, with full alert coverage |
| Team Productivity | Enabled analyst-friendly batch workflows, improving access without incurring extra cost |
| Product Recommendations | Developed personalized recommendations for Similar Items, Top Selling Products, Brands, and Buy Again products, driving improved user engagement and repeat purchase rates |
| Fraud Prevention | Implemented address-based fraud detection flagging suspicious multi-account abuse, reducing financial leakage and promo misuse |
| Modern Stack Readiness | Data prepared for ML, reporting, real-time streaming, operational integration |
Client Fit & Technical Alignment
| Requirement | Delivery |
|---|---|
| GCP-native Data Stack | Full migration to BigQuery, GCS, Composer, Kafka, IAM |
| BI Tools | Tableau and Looker Studio with stable, clean reporting models |
| ETL & Orchestration | Mage pipelines with failure alerts, Slack integration, product recommendation pipelines, and fraud detection |
| Data Governance | IAM setup, audit logs, SLA-based alerting |
| Cost Optimization | Slot commitments, partitioning, query tuning |
| Real-Time & Batch | Kafka publishing, scheduled transfers, batch processing |
| Product Recommendation Engine | Rule-based models recommending Similar Items, Top Sellers, Brands, and Buy Again products based on user behavior |
| Fraud Detection & Alerts | Address normalization, composite grouping, automated alerts feeding fraud investigation workflows |
| ML Readiness | Structured warehouse in Medallion layers, ready for VertexAI |