Window Functions
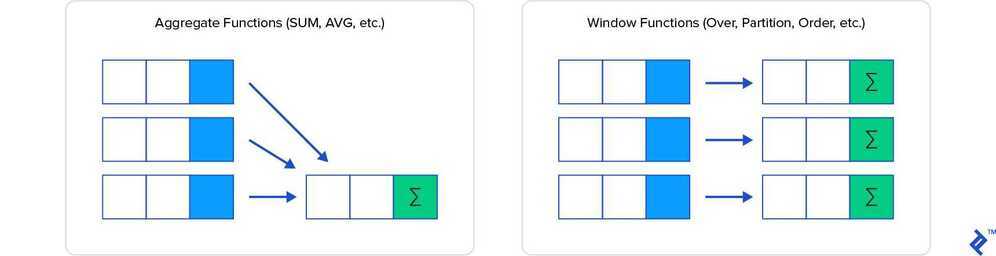
Window functions can be simply explained as calculation functions similar to aggregating, but where normal aggregating via the GROUP BY clause combines then hides the individual rows being aggregated, window functions have access to individual rows and can add some of the attributes from those rows into the result set.
https://www.toptal.com/sql/intro-to-sql-windows-functions
https://mjk.space/advances-sql-window-frames
Questions
What does a window function in SQL do?
A window function performs calculations over a set of rows, and uses information within the individual rows when required.
How is a window aggregate function different from a "group by" aggregate function?
With "group by," you can only aggregate columns not in the "group by" clause. Window functions allow you to gather both aggregate and non-aggregate values at once.
Can you use more than one window function in a single SELECT statement?
Yes, and this is a great advantage, since the window "frames" in each can be based on different filters.
Can I access previous data with window functions?
Yes, you can access both previous and future rows, using the LAG and LEAD functions.
Can I generate running totals with window functions?
Yes, you can add the ORDER BY clause to produce running totals on each row.
What are window functions?
They make building complex aggregations much simpler. They are so powerful that they serve as a dividing point in time: people talk about SQL before window functions and SQL after window functions. After window functions and Common Table Expressions were introduced to SQL, SQL has become Turing complete!
Window functions operate on a group of rows, referred to as a window, and calculate a return value for each row based on the group of rows. Window functions are useful for processing tasks such as calculating a moving average, computing a cumulative statistic, or accessing the value of rows given the relative position of the current row.
Syntax
function OVER { window_name | ( window_name ) | window_spec }
function
{ ranking_function | analytic_function | aggregate_function }
over_clause
OVER { window_name | ( window_name ) | window_spec }
window_spec
( [ PARTITION BY partition [ , ... ] ] [ order_by ] [ window_frame ] )
Parameters
function
The function operating on the window. Different classes of functions support different configurations of window specifications.
ranking_function
Any of the Ranking window functions.
If specified the window_spec must include an ORDER BY clause, but not a window_frame clause.
analytic_function
Any of the Analytic window functions.
aggregate_function
Any of the Aggregate functions.
If specified the function must not include a FILTER clause.
window_name
Identifies a named window specification defined by the query.
window_spec
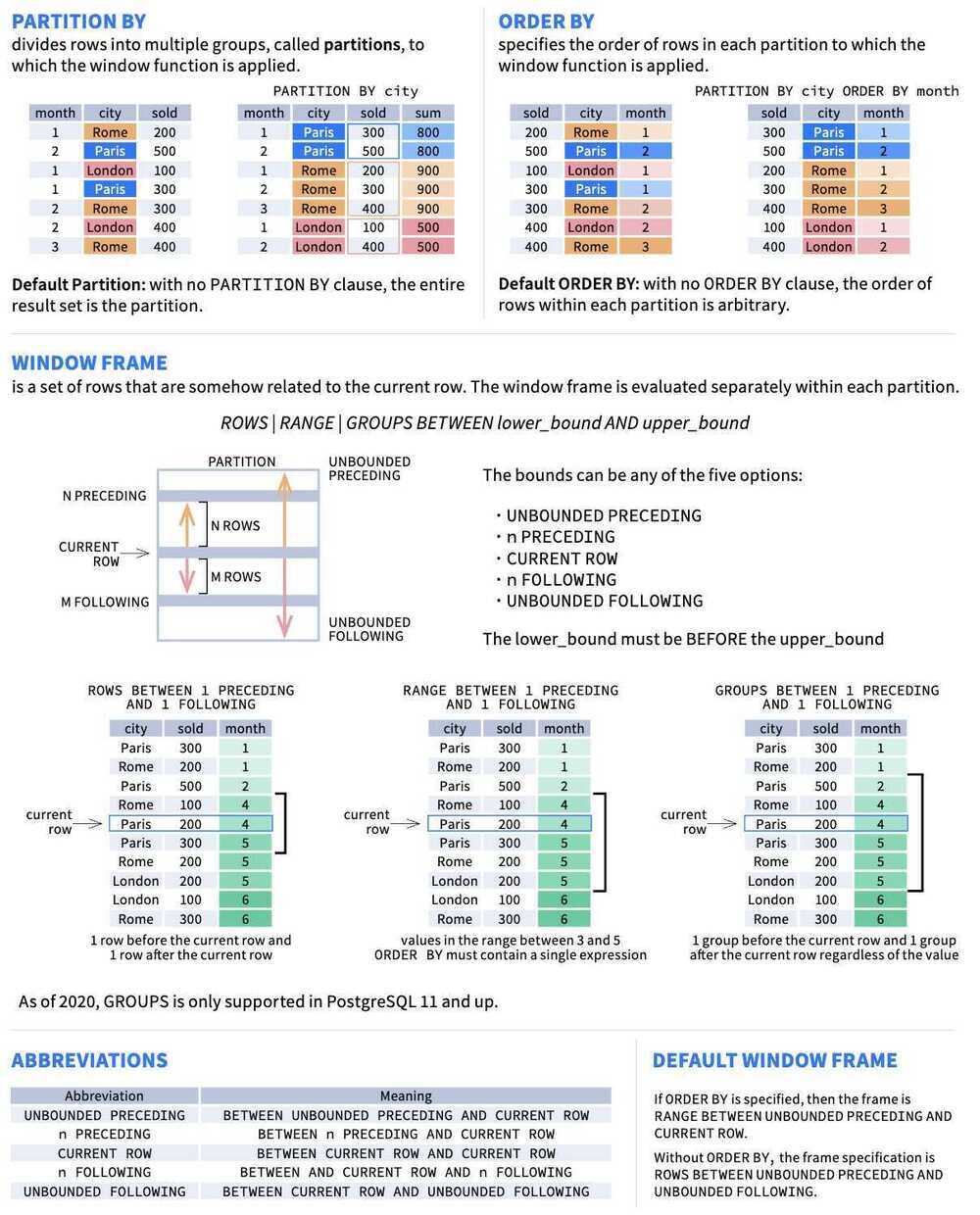
This clause defines how the rows will be grouped, sorted within the group, and which rows within a partition a function operates on.
partition
One or more expression used to specify a group of rows defining the scope on which the function operates. If no PARTITION clause is specified the partition is comprised of all rows.
order_by
The ORDER BY clause specifies the order of rows within a partition.
window_frame
The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates.
You can specify SORT BY as an alias for ORDER BY.
You can also specify DISTRIBUTE BY as an alias for PARTITION BY. You can use CLUSTER BY as an alias for PARTITION BY in the absence of ORDER BY.
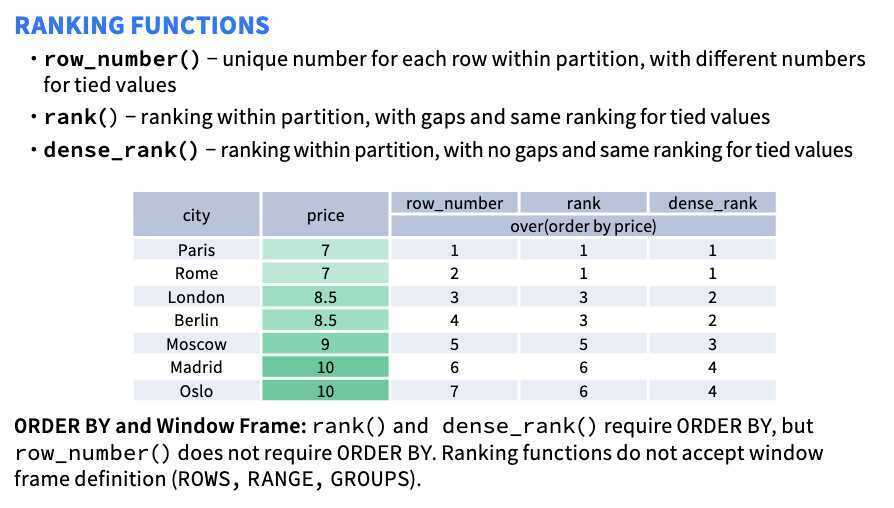
Ranking Window Functions
| Function | Description |
|---|---|
| dense_rank() | Returns the rank of a value compared to all values in the partition. |
| ntile(n) | Divides the rows for each window partition into n buckets ranging from 1 to at most n. |
| percent_rank() | Computes the percentage ranking of a value within the partition. |
| rank() | Returns the rank of a value compared to all values in the partition. |
| row_number() | Assigns a unique, sequential number to each row, starting with one, according to the ordering of rows within the window partition. |
rank() vs dense_rank() vs row_number()
You will only see the difference if you have ties within a partition for a particular ordering value.
RANK numbers are skipped so there may be a gap in rankings, and may not be unique. DENSE_RANK numbers are not skipped so there will not be a gap in rankings, and may not be unique.
Unlike DENSE_RANK, RANK skips positions after equal rankings. The number of positions skipped depends on how many rows had an identical ranking. For example, Mary and Lisa sold the same number of products and are both ranked as #2. With RANK, the next position is #4; with DENSE_RANK, the next position is #3.
Both RANK and RANK_DENSE work on partitions of data
RANK and DENSE_RANK are deterministic in this case, all rows with the same value for both the ordering and partitioning columns will end up with an equal result, whereas ROW_NUMBER will arbitrarily (non deterministically) assign an incrementing result to the tied rows.
What’s the Difference Between RANK and DENSE_RANK in SQL? | LearnSQL.com
Examples
-- 2nd highest salary in each department
SELECT department_id, emp_name, salary
FROM (
SELECT
department_id,
emp_name,
salary,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank
FROM employees
) ranked
WHERE salary_rank = 2;
-- RANK()
SELECT name,
dept,
RANK() OVER (PARTITION BY dept ORDER BY salary) AS rank
FROM employees;
Lisa Sales 10000 1
Alex Sales 30000 2
Evan Sales 32000 3
Fred Engineering 21000 1
Tom Engineering 23000 2
Chloe Engineering 23000 2
Paul Engineering 29000 4
-- Rank - 1,2,2,4
-- DENSE_RANK()
SELECT name,
dept,
DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS dense_rank
FROM employees;
Lisa Sales 10000 1
Alex Sales 30000 2
Evan Sales 32000 3
Fred Engineering 21000 1
Tom Engineering 23000 2
Chloe Engineering 23000 2
Paul Engineering 29000 3
-- Rank - 1,2,2,3
-- Example
WITH T(StyleID, ID)
AS (SELECT 1,1 UNION ALL
SELECT 1,1 UNION ALL
SELECT 1,1 UNION ALL
SELECT 1,2)
SELECT *,
RANK() OVER(PARTITION BY StyleID ORDER BY ID) AS [RANK],
ROW_NUMBER() OVER(PARTITION BY StyleID ORDER BY ID) AS [ROW_NUMBER],
DENSE_RANK() OVER(PARTITION BY StyleID ORDER BY ID) AS [DENSE_RANK]
FROM T
StyleID ID RANK ROW_NUMBER DENSE_RANK
----------- -------- --------- --------------- ----------
1 1 1 1 1
1 1 1 2 1
1 1 1 3 1
1 2 4 4 2
SELECT department_name, first_name, last_name, salary
FROM
(
SELECT
first_name, last_name, salary,
d. name as department_name,
DENSE_RANK() OVER (PARTITION BY d. name ORDER BY e. salary DESC)
FROM employees e
JOIN departments d
ON
e.department_id = d.id
) a
where dense_rank = 1;
In the context of the query, the window frame (ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) is used by the DENSE_RANK() function to calculate the dense rank of each row within its respective department. The dense rank is determined by the order of the "salary" values within the partition.
The clause "ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW" in the given query specifies the default window frame for the DENSE_RANK() function. If you omit this clause, the result will indeed remain the same because the default behaviour of the DENSE_RANK() function is to use the entire partition as the window frame.
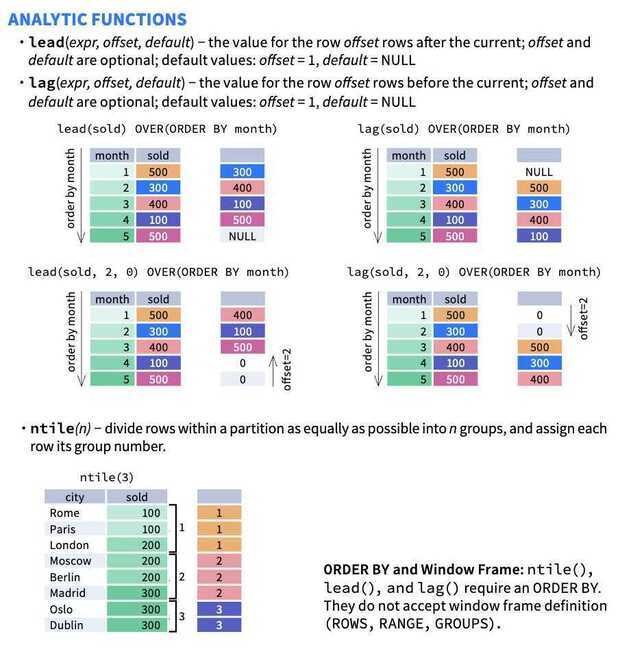
Analytic window functions
| Function | Description |
|---|---|
| cume_dist() | Returns the position of a value relative to all values in the partition. |
| lag(expr[,offset[,default]]) | Returns the value of expr from a preceding row within the partition. |
| lead(expr[,offset[,default]]) | Returns the value of expr from a subsequent row within the partition. |
| nth_value(expr, offset[, ignoreNulls]) | Returns the value of expr at a specific offset in the window. |
SQL Window Functions Cheat Sheet




SQL Window Functions Cheat Sheet | LearnSQL.com
Links
- Analytical Queries
- Aggregation Queries
- What Is the OVER() Clause in SQL? | LearnSQL.com
- Introducing Window Functions in Spark SQL - The Databricks Blog
- Window functions | Databricks on AWS
- Window Functions - Spark 3.4.0 Documentation
- Spark Window Functions with Examples - Spark By Examples
- 8 Best SQL Window Function Articles | LearnSQL.com
- 5 Practical Examples of Using ROWS BETWEEN in SQL | LearnSQL.com
- Introducing Window Functions in Spark SQL - The Databricks Blog
- Spark Window Functions with Examples - Spark By Examples
- Calculate SQL Percentile using the PERCENT_RANK function in SQL Server
- motifanalytics.com/blog/a-beginners-guide-to-sequence-analytics-in-sql