Lambda Architecture
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture xattempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.
Lambda architecture depends on a data model with an append-only, immutable data source that serves as a system of record.It is intended for ingesting and processing timestamped events that are appended to existing events rather than overwriting them. State is determined from the natural time-based ordering of the data.
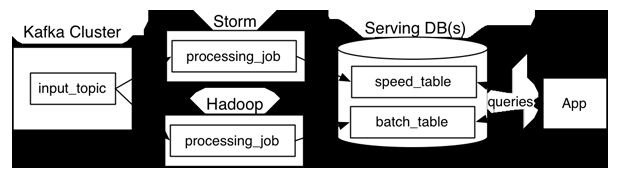
Overview
Lambda architecture describes a system consisting of three layers: batch processing, speed (or real-time) processing, and a serving layer for responding to queries. The processing layers ingest from an immutable master copy of the entire data set.
Batch layer
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views. This means it can fix any errors by recomputing based on the complete data set, then updating existing views. Output is typically stored in a read-only database, with updates completely replacing existing precomputed views.
Apache Hadoop is the de facto standard batch-processing system used in most high-throughput architectures.
Speed layer
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data. Essentially, the speed layer is responsible for filling the "gap" caused by the batch layer's lag in providing views based on the most recent data. This layer's views may not be as accurate or complete as the ones eventually produced by the batch layer, but they are available almost immediately after data is received, and can be replaced when the batch layer's views for the same data become available.
Stream-processing technologies typically used in this layer include Apache Storm, SQLstream and Apache Spark. Output is typically stored on fast NoSQL databases.
Serving layer
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data. Examples of technologies used in the serving layer include Druid, which provides a single cluster to handle output from both layers.Dedicated stores used in the serving layer include Apache Cassandra, Apache HBase, MongoDB, VoltDB or Elasticsearch for speed-layer output, and Elephant DB, Apache Impala, SAP HANA or Apache Hive for batch-layer output.
https://en.wikipedia.org/wiki/Lambda_architecture
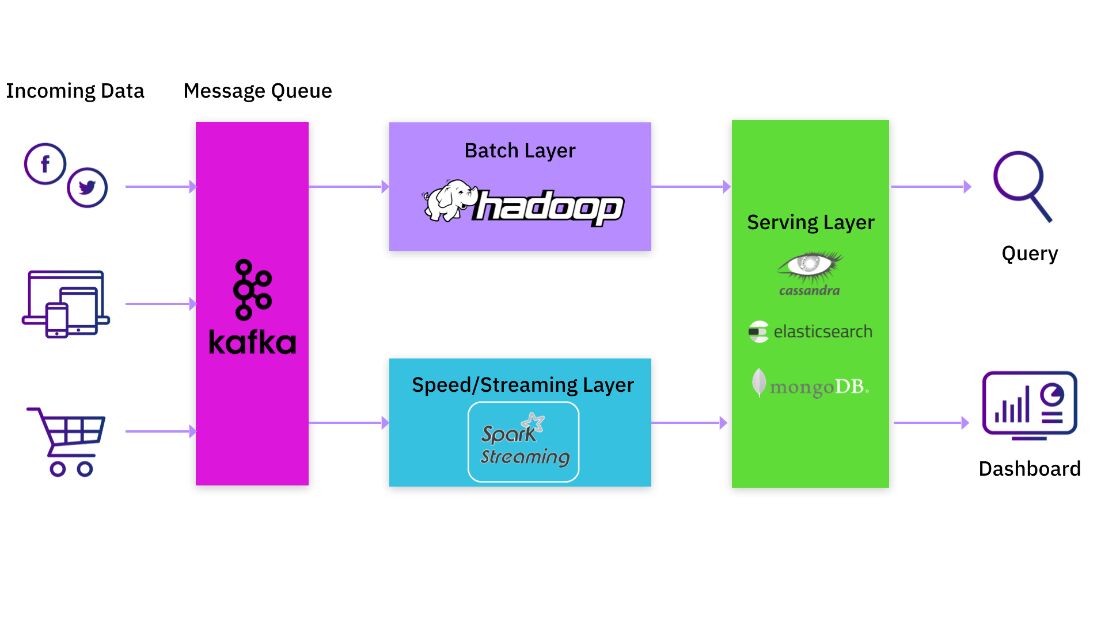
Common Lambda Architectures: Kafka, Spark, and MongoDB/Elasticsearch
If you are a data practitioner, you would probably have either implemented or used a data processing platform that incorporates the Lambda architecture. A common implementation would have large batch jobs in Hadoop complemented by an update stream stored in Apache Kafka. Apache Spark is often used to read this data stream from Kafka, perform transformations, and then write the result to another Kafka log. In most cases, this would not be a single Spark job but a pipeline of Spark jobs. Each Spark job in the pipeline would read data produced by the previous job, do its own transformations, and feed it to the next job in the pipeline. The final output would be written to a serving system like Apache Cassandra, Elasticsearch or MongoDB.
[What Is Lambda Architecture?](https://www.databricks.com/glossary/lambda-architecture
Shortcomings of Lambda Architecture
-
Maintaining two different processing paths, one via the batch system and another via the real-time streaming system, is inherently difficult. If you ship new code functionality to the streaming software but fail to make the necessary equivalent change to the batch software, you could get erroneous results.
-
If you are an application developer or data scientist who wants to make changes to your streaming or batch pipeline, you have to either learn how to operate and modify the pipeline, or you have to wait for someone else to make the changes on your behalf. The former option requires you to pick up data engineering tasks and detracts from your primary role, while the latter forces you into a holding pattern waiting on the pipeline team for resolution.
-
Most of the data transformation happens as new data enters the system at write time, whereas the serving layer is a simpler key-value lookup that does not handle complex transformations. This complicates the job of the application developer because she/he cannot easily apply new transformations retroactively on pre-existing data.
https://rockset.com/blog/aggregator-leaf-tailer-an-architecture-for-live-analytics-on-event-streams