Kimball / Inmon Architecture
For designing a data warehouse, there are two most common architectures named Kimball and Inmon.
Kimball
Kimball’s approach to designing a Datawarehouse was introduced by Ralph Kimball. This approach starts with recognizing the business process and questions that Dataware house has to answer. These sets of information are being analyzed and then documented well. The Extract Transform Load (ETL) software brings all data from multiple data sources called data marts and then is loaded into a common area called staging. Then this is transformed into an OLAP cube.
Applications
- Setup and Built are quick.
- Generating report against multiple star schema is very successful.
- Database operations are very effective.
- Occupies less space in the database and management is easy.
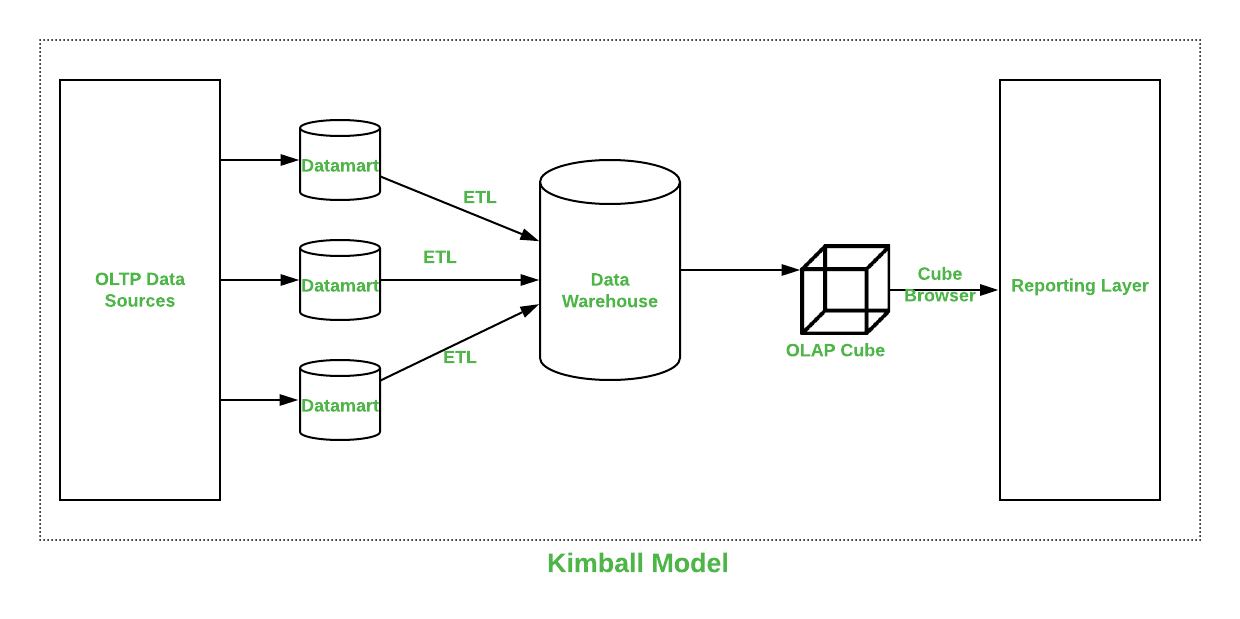
Kimball's four step process to dimensional data modeling
- Pick a business process to model. Kimball’s approach begins with a business process, since ultimately, business users would want to ask questions about processes. This stands in contrast to earlier modeling methodologies, like Bill Inmon’s, which started with the business entities in mind (e.g. the customer model, product model, etc).
- Decide on the grain. The grain here means the level of data to store as the primary fact table. It should be the most atomic level possible - that is, a level of data that cannot be split further. For instance, in our Point of Sales example earlier, the grain should actually be the line items inside each order, instead of the order itself. This is because in the future, business users may want to ask questions like "what are the products that sold the best during the day in our stores?" - and you would need to drop down to the line-item level in order to query for that question effectively. In Kimball’s day, if you had modeled your data at the order level, such a question would take a huge amount of work to get at the data, because you would run the query on slow database systems. You might even need to do ETL again, if the data is not currently in a queryable form in your warehouse! So it is best to model at the lowest level possible from the beginning.
- Chose the dimensions that apply to each fact table row. This is usually quite easy to answer if you have ‘picked the grain’ properly. Dimensions fall out of the question "how do businesspeople describe the data that results from the business process?" You will decorate fact tables with a robust set of dimensions representing all possible descriptions.
- Identify the numeric facts that will populate each fact table row. The numeric data in the fact table falls out of the question "what are we answering?" Business people will ask certain obvious business questions (e.g. what’s the average profit margin per product category?), and so you will need to decide on what are the most important numeric measures to store at the fact table layer, in order to be recombined later to answer their queries. Facts should be true to the grain defined in step 2; if a fact belongs to a different grain, it should live in a separate fact table.
Kimball's Dimensional Data Modeling | The Analytics Setup Guidebook
Inmon
Inmon’s approach to designing a Datawarehouse was introduced by Bill Inmon. This approach starts with a corporate data model. This model recognizes key areas and also takes care of customers, products, and vendors. This model serves for the creation of a detailed logical model which is used for major operations. Details and models are then used to develop a physical model. This model is normalized and makes data redundancy less. This is a complex model that is difficult to be used for business purposes for which data marts are created and each department is able to use it for their purposes.
Applications
- The data warehouse is very flexible to changes.
- Business processes can be understood very easily.
- Reports can be handled across enterprises.
- ETL process is very less prone to errors.
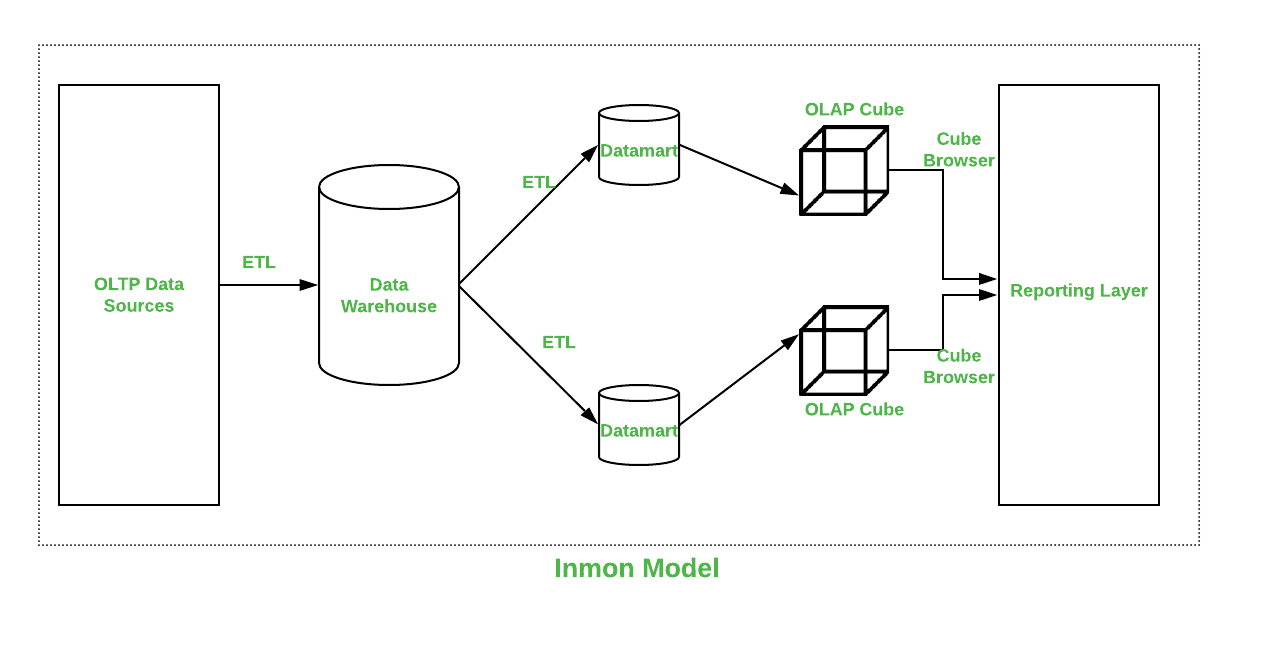
Difference between Kimball and Inmon
| Parameters | Kimball | Inmon |
|---|---|---|
| Introduced by | Introduced by Ralph Kimball. | Introduced by Bill Inmon. |
| Approach | It has a Bottom-Up Approach for implementation. | It has Top-Down Approach for implementation. |
| Data Integration | It focuses on Individual business areas. | It focuses on Enterprise-wide areas. |
| Building Time | It is efficient and takes less time. | It is complex and consumes a lot of time. |
| Cost | It has iterative steps and is cost-effective. | Initial cost is huge and the development cost is low. |
| Skills Required | It does not need such skills but a generic team will do the job. | It needs specialized skills to make work. |
| Maintenance | Here maintenance is difficult. | Here maintenance is easy. |
| Data Model | It prefers data to be in the De-normalized model. | It prefers data to be in a normalized model. |
| Data Store Systems | In this, source systems are highly stable. | In this, source systems have a high rate of change. |
Inmon or Kimball: Which approach is suitable for your data warehouse? | Computer Weekly
Difference between Kimball and Inmon - GeeksforGeeks
Data Vault
A Data Vault is a more recent data modeling design pattern used to build data warehouses for enterprise-scale analytics compared to Kimball and Inmon methods.
Data Vaults organize data into three different types: hubs, links, and satellites. Hubs represent core business entities, links represent relationships between hubs, and satellites store attributes about hubs or links.
Data Vault focuses on agile data warehouse development where scalability, data integration/ETL and development speed are important. Most customers have a landing zone, Vault zone and a data mart zone which correspond to the Databricks organizational paradigms of Bronze, Silver and Gold layers. The Data Vault modeling style of hub, link and satellite tables typically fits well in the Silver layer of the Databricks Lakehouse.
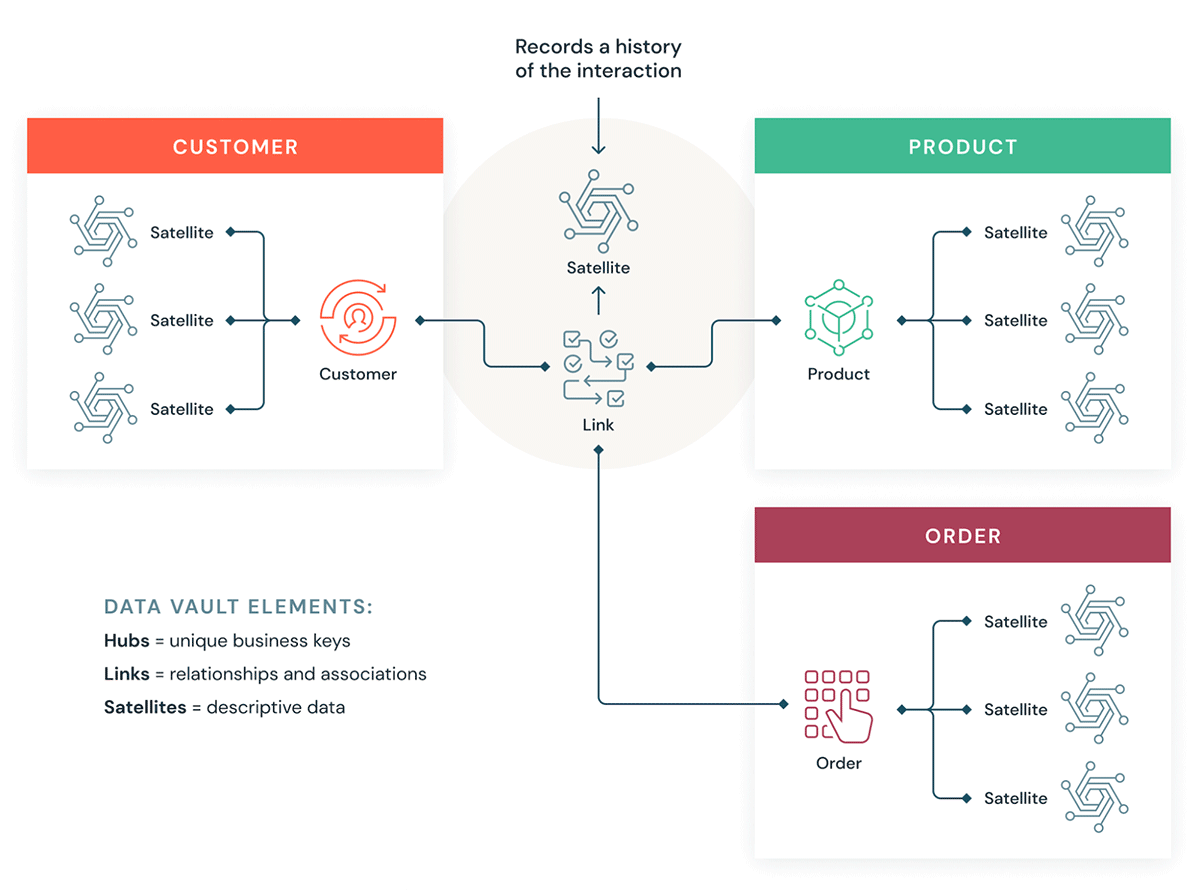
Data Vault 2.0 - DataVaultAlliance
Data Warehouse Concepts: Kimball vs. Inmon Approach | Astera