Spark Built-in Libraries
Intro
- Apache spark is a fast and general-purpose cluster computing system for large scale data processing
- High-level APIs in Java, Scala, Python and R
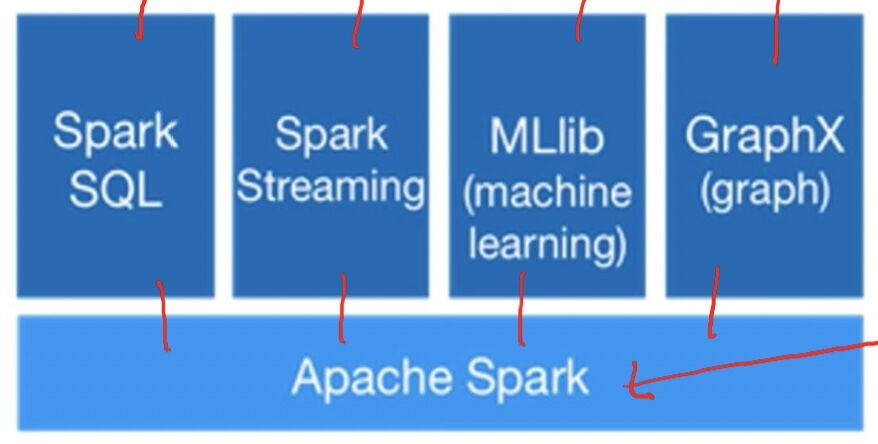
Standard library for Big Data
- Big data apps lack libraries of common algorithms
- Spark's generality + support for multiple languages make it suitable to offer this
- Much of future activity will be in these libraries
Machine Learning Library (MLlib)
- Classification: logistic regression, linear SVM, naive Bayes, classification tree
- Regression: generalized linear models (GLMs), regression tree
- Collaborative filtering: alternating least squares (ALS), non-negative matrix factorization (NMF)
- Clustering: K-means
- Decomposition: SVD, PCA
- Optimization: stochastic gradient descent, L-BFGS)
GraphX
- General graph processing library
- Build graph using RDDs of nodes and edges
- Large library of graph algorithms with composable steps
GraphX Algorithms
-
Collaborative Filtering
- Alternating Least Squares
- Stochastic Gradient Descent
- Tensor Factorization
-
Structured Prediction
- Loopy Belief Propagation
- Max-produce linear programs
- Gibbs sampling
-
Semi-supervised ML
- Graph SSL
- CoEM
-
Community Detection
- Triangle-Counting
- K-core decomposition
- K-Truss
-
Graph Analytics
- PageRank
- Personalized PageRank
- Shortest Path
- Graph Coloring
-
Classification
- Neural Networks
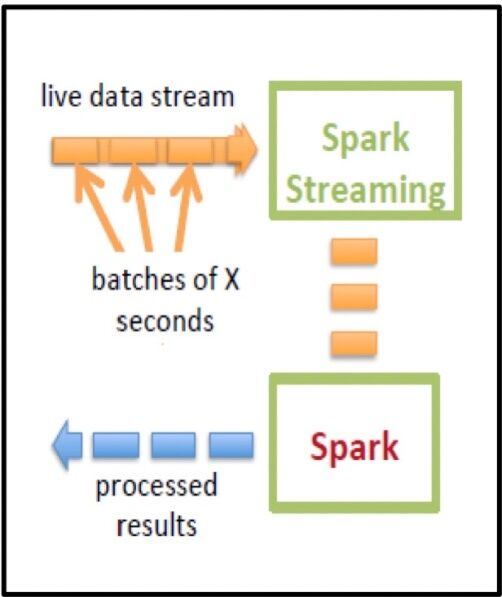
Spark Streaming
- Large scale streaming computation
- Ensure exactly one semantics
- Integrated with Spark -> unifies batch, interactive, and streaming computations
Spark SQL
Enables loading & querying structed data in Spark
From Hive:
c = HiveContext(sc)
rows = c.sql("select text, year from hivetable")
rows.filter(lambda r: r.year > 2013).collect()
From JSON:
c.jsonFile("tweets.json").registerAsTable("tweets")
c.sql("select text, user.name from tweets")