Comprehensive Guide to Apache Projects
A
- Accumulo
- ActiveMQ
- Airavata
- Airflow
- Allura
- Ambari - Hadoop cluster provisioning, management, and monitoring
- Ant
- Any23
- Apex - Stream and batch processing on YARN
- APR
- Archiva
- Aries
- AsterixDB
- Atlas
- Aurora
- Avro - Data serialization system (data structure, binary format, container, RPC)
- Axis
Arrow
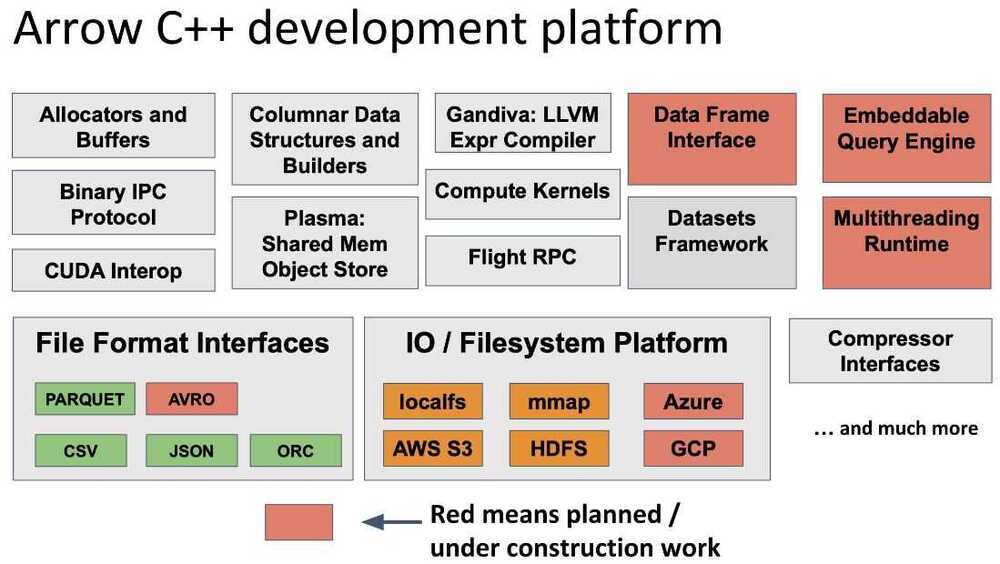
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. It also provides computational libraries and zero-copy streaming messaging and interprocess communication. Languages currently supported include C, C++, C#, Go, Java, JavaScript, MATLAB, Python, R, Ruby, and Rust.
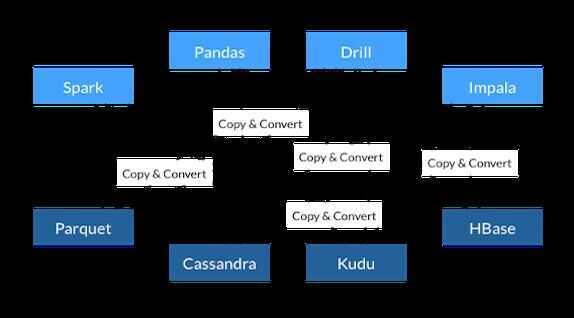

- All systems utilize the same memory format
- No overhead for cross-system communication
- Projects can share functionality (eg, Parquet-to-Arrow reader)
Apache Arrow Flight
Arrow Flight provides a high-performance wire protocol for large-volume data transfer for analytics, designed for the needs of the modern data world including cross-platform language support, infinite parallelism, high efficiency, robust security, multi-region distribution, and efficient network utilization
- A gRPC-based framework for defining custom data services that send and receive Arrow columnar data natively
- Uses Protocol Buffers v3 for client protocol
- Pluggable command execution layer, authentication
- Low-level gRPC optimizations to avoid unnecessay serialization
https://www.dremio.com/understanding-apache-arrow-flight
https://www.dremio.com/apache-arrow-explained
B
- Bahir
- Beam - Programming model for batch and streaming data processing
- Bigtop
- Bloodhound
- BookKeeper - A scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads - https://streaml.io/blog/why-apache-bookkeeper
- Brooklyn
- Buildr
- BVal
C
- Calcite
- Camel
- Carbondata
- Cassandra
- Cayenne
- Celix
- Chemistry
- Clerezza
- CloudStack
- Cocoon
- Commons
- Cordova
- Creadur
- Crunch - Java library for writing, testing, running MapReduce pipelines
- cTAKES
- Curator
- CXF
Chukwa
Apache Chukwa is an open source data collection system for monitoring large distributed systems. Apache Chukwa is built on top of the Hadoop Distributed File System (HDFS) and Map/Reduce framework and inherits Hadoop's scalability and robustness. Apache Chukwa also includes a flexible and powerful toolkit for displaying, monitoring and analyzing results to make the best use of the collected data.
CouchDB
Seamless multi-master sync, that scales from Big Data to Mobile, with an IntuitiveHTTP/JSON API and designed forReliability.
Apache CouchDB™ lets you access your data where you need it. The Couch Replication Protocol is implemented in a variety of projects and products that span every imaginable computing environment from globally distributed server-clusters, over mobile phones to web browsers.
Store your data safely, on your own servers, or with any leading cloud provider. Your web- and native applications love CouchDB, because it speaksJSON natively and supports binary data for all your data storage needs.
The Couch Replication Protocol lets your data flow seamlessly between server clusters to mobile phones and web browsers, enabling a compelling offline-first user-experience while maintaining high performance and strong reliability. CouchDB comes with a developer-friendly query language, and optionally MapReduce for simple, efficient, and comprehensive data retrieval.
https://docs.couchdb.org/en/stable/intro/index.html
D
- DataFu
- DB
- DeltaSpike
- Directory
- DRAT
- Druid
Drill
Distributed queries on multiple data stores and formats
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage
- Columnar execution engine (the first ever to support complex data!)
- Data-driven compilation and recompilation at execution time
- Specialized memory management that reduces memory footprint and eliminates garbage collections
- Locality-aware execution that reduces network traffic when Drill is co-located with the datastore
- Advanced cost-based optimizer that pushes processing into the datastore when possible
E
F
- Falcon - Data governance engine for Hadoop clusters
- Felix
- Fineract
- Flex
- Flink
- Flume - Streaming data ingestion for Hadoop
- Fluo
- Forrest
FreeMarker
FreeMarker is a freeJava-based template engine, originally focusing on dynamic web page generation with MVCsoftware architecture. However, it is a general purpose template engine, with no dependency on servlets or HTTP or HTML, and is thus often used for generating source code, configuration files or e-mails
G
- Geode
- Geronimo
- Giraph - Iterative distributed graph processing framework
- Gora - Open source framework provides an in-memory data model and persistence for big data
- Groovy
- Guacamole
- Gump
H
- Hadoop - MapReduce implementation
- Hama - Bulk synchronous parallel (BSP) implementation for big data analytics
- HAWQ - Massively parallel SQL on Hadoop
- HBase
- Hive - Data warehousing framework on YARN
- HttpComponents
Helix
Apache Helix is a generic cluster management framework used for the automatic management of partitioned, replicated and distributed resources hosted on a cluster of nodes.Helix automates reassignment of resources in the face of node failure and recovery, cluster expansion, and reconfiguration.
- Automatic assignment of resources and partitions to nodes
- Node failure detection and recovery
- Dynamic addition of resources
- Dynamic addition of nodes to the cluster
- Pluggable distributed state machine to manage the state of a resource via state transitions
- Automatic load balancing and throttling of transitions
- Optional pluggable rebalancing for user-defined assignment of resources and partitions
I
- Isis
- Ignite - In-memory data fabric
- Distributed Database For High‑Performance Applications With In‑Memory Speed
- Apache Ignite is an open-source, in-memory computing platform and distributed database that provides high-performance caching, data storage, and processing for large-scale datasets, supporting SQL, key-value, and compute APIs for real-time analytics and transactions (HTAP) with features like ACID compliance and multi-tier storage. It functions as an in-memory data grid, accelerator for existing databases, or a standalone distributed database, offering horizontal scalability across on-premises, cloud, or hybrid environments.
- GitHub - apache/ignite: Apache Ignite ⭐ 5.1k
- Impala - Distributed SQL on YARN
- Iceberg
J
K
Kudu
Apache Kudu is a columnar data store that aims to replace HDFS + Parquet pair in many cases. It combines space-efficient columnar storage with ability to make fast single-row reads and writes.
A Kudu cluster stores tables that look just like tables you're used to from relational (SQL) databases. A table can be as simple as a binarykey andvalue, or as complex as a few hundred different strongly-typed attributes.
L
Lucene
Is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Scalable, High-Performance Indexing
- over 150GB/hour on modern hardware
- small RAM requirements -- only 1MB heap
- incremental indexing as fast as batch indexing
- index size roughly 20-30% the size of text indexed
Powerful, Accurate and Efficient Search Algorithms
- ranked searching -- best results returned first
- many powerful query types: phrase queries, wildcard queries, proximity queries, range queries and more
- fielded searching (e.g. title, author, contents)
- sorting by any field
- multiple-index searching with merged results
- allows simultaneous update and searching
- flexible faceting, highlighting, joins and result grouping
- fast, memory-efficient and typo-tolerant suggesters
- pluggable ranking models, including the Vector Space Model and Okapi BM25
- configurable storage engine (codecs)
M
- MADlib - Big data machine learning in SQL
- ManifoldCF
- Marmotta
- Maven -
apt install mavenbrew install maven - Mesos - Distributed systems kernel (all compute resources abstracted)
- MetaModel
- Metron
- MINA
- Mnemonic
- MyFaces
- Mynewt
Mahout
Machine learning and data mining on Hadoop
Apache Mahout is adistributed linear algebra frameworkandmathematically expressive Scala DSLdesigned to let mathematicians, statisticians, and data scientists quicklyimplement their own algorithms. Apache Spark is the recommended out-of-the-box distributed back-end, or can be extended to other distributed backends.
- Mathematically Expressive Scala DSL
- Support for Multiple Distributed Backends (including Apache Spark)
- Modular Native Solvers for CPU/GPU/CUDA Acceleration
N
Nifi
An easy to use, powerful, and reliable system to process and distribute data.
Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
Apache NiFi is an open-source data integration and automation tool that enables the automation of data flow between different systems. NiFi provides a user-friendly interface to design, control, and manage the flow of data between various sources and destinations. The tool is particularly useful in handling data from different sources, applying transformations, and routing it to different systems in real-time.
Documentation for Version 2 - Apache NiFi
O
- ODE
- OFBiz
- Olingo
- OODT
- Oozie - Workflow scheduler (DAGs) for Hadoop
- Open Climate Workbench
- OpenJPA
- OpenMeetings
- OpenNLP
- OpenOffice
- OpenWebBeans
ORC (Optimized Row Columnar)
Columnar storage format
The smallest, fastest columnar storage for Hadoop workloads.
- Schema segregated into footer
- Column major with stripes
- Integrated compression, indexes, and stats
- Support for predicate pushdown
P
- Parquet - Columnar storage format
- PDFBox
- Perl
- Pig - Turns high-level data analysis language into MapReduce programs
- Pivot
- POI
- Polygene
- Portals
- Predictionio
- Pulsar
Phoenix
OLTP and operational analytics for Apache Hadoop
Apache Phoenixis an open source, massively parallel, relational database engine supporting OLTP for Hadoop using Apache HBase as its backing store. Phoenix provides a JDBC driver that hides the intricacies of the noSQL store enabling users to create, delete, and alter SQL tables, views, indexes, and sequences; insert and delete rows singly and in bulk; and query data through SQL.Phoenix compiles queries and other statements into native noSQL store APIs rather than using MapReduce enabling the building of low latency applications on top of noSQL stores.
https://en.wikipedia.org/wiki/Apache_Phoenix
Pinot
Pinot is a realtime distributed OLAP datastore, which is used at LinkedIn to deliver scalable real time analytics with low latency. It can ingest data from offline data sources (such as Apache Hadoop and flat files) as well as online sources (such as Apache Kafka). Pinot is designed to scale horizontally.
Features
- A column-oriented database with various compression schemes such as Run Length, Fixed Bit Length
- Pluggable indexing technologies - Sorted Index, Bitmap Index, Inverted Index
- Ability to optimize query/execution plan based on query and segment metadata
- Near real time ingestion from Kafka and batch ingestion from Hadoop
- SQL like language that supportsselection, aggregation, filtering, group by, order by, distinctqueries on fact data
- Support for multivalued fields
- Horizontally scalable and fault tolerant
- User Facing Analytics / Site Facing Analytics
https://github.com/apache/incubator-pinot
https://engineering.linkedin.com/blog/2019/03/pinot-joins-apache-incubator
Building Latency Sensitive User Facing Analytics via Apache Pinot - YouTube
Polaris
- Apache Polaris Graduates to Top-Level Project
- GitHub - apache/polaris: Apache Polaris, the interoperable, open source catalog for Apache Iceberg ⭐ 2.0k
- Apache Polaris
- What does Polaris mean for Apache Iceberg? : r/dataengineering
Q
- Qpid
- Apache Qpid™ makes messaging tools that speak AMQP and support many languages and platforms.
R
- Ranger - Apache Ranger is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform.
- REEF
- River
- RocketMQ
- Roller
- Royale
S
- Samza - Distributed stream processing framework - https://engineering.linkedin.com/blog/2018/11/samza-1-0--stream-processing-at-massive-scale
- Santuario
- Sentry
- Serf
- ServiceMix
- Shiro
- SIS
- Sling
- SpamAssassin
- Spark - General-purpose cluster computing framework
- Stanbol
- STeVe
- Storm - Distributed realtime (streaming) computing framework
- Streams
- Struts
- Subversion
- Synapse
- Syncope
- SystemML
Sqoop
Bulk data transfer between Hadoop and structured datastores such as relational databases.
Sqoop is a command-line interface application for transferring data between relational databases and Hadoop
Solr
Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene.
Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more.
Cross Data Center Replication (CDCR) | Apache Solr Reference Guide 6.6
T
- Tajo
- Tapestry
- Tez - Dataflow (DAG) framework on YARN
- Thrift - Data serialization framework (full-stack)
- Tika
- Tiles
- Tomcat
- TomEE
- Traffic Control
- Traffic Server
- Trafodion
- Turbine
- Twill
TinkerPop
Apache TinkerPop™ is a graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP).
Apache TinkerPop™ is an open source, vendor-agnostic, graph computing framework distributed under the commercial friendly Apache2 license. When a data system is TinkerPop-enabled, its users are able to model their domain as a graph and analyze that graph using the Gremlin graph traversal language. Furthermore, all TinkerPop-enabled systems integrate with one another allowing them to easily expand their offerings as well as allowing users to choose the appropriate graph technology for their application. Sometimes an application is best served by an in-memory, transactional graph database. Sometimes a multi-machine distributed graph database will do the job. Or perhaps the application requires both a distributed graph database for real-time queries and, in parallel, a Big(Graph) Data processor for batch analytics. Whatever the application's requirements, there exists a TinkerPop-enabled graph system out there to meet its needs.
Tcl
TCL is a high-level, general-purpose, interpreted, dynamic programming language. It was designed with the goal of being very simple but powerful. Tcl casts everything into the mold of a command, even programming constructs like variable assignment and procedure definition. Tcl supports multiple programming paradigms, including object-oriented, imperative and functional programming or procedural styles
It is commonly used embedded into C applications, for rapid prototyping, scripted applications, GUIs, and testing. Tcl interpreters are available for many operating systems, allowing Tcl code to run on a wide variety of systems. Because Tcl is a very compact language, it is used on embedded systems platforms, both in its full form and in several other small-footprint versions.
The popular combination of Tcl with the Tk extension is referred to as Tcl/Tk, and enables building a graphical user interface(GUI) natively in Tcl. Tcl/Tk is included in the standard Python installation in the form of Tkinter.
U
Unomi
Apache Unomi is a Java Open Source customer data platform, a Java server designed to manage customers, leads and visitors data and help personalize customers experiences while also offering features to respect visitor privacy rules (such as GDPR)
V
W
Apache Wayang | Cross-Platform Data Processing
Unifying Data Processing Engines for Cross-Platform Analytics
Apache Wayang (formerly known as Rheem) is a cross-platform data processing system designed to give developers and organizations a unified way to execute pipelines over multiple data processing engines—such as Apache Spark, Apache Flink, PostgreSQL, and more.
Instead of forcing users to choose a single execution backend, Wayang:
- Abstracts data processing engines through a unified API
- Can automatically choose the best execution platform based on workload characteristics
- Optimizes performance by distributing tasks across engines if necessary
- Provides a flexible plugin architecture for integrating new platforms and optimizers
In other words, Wayang enables interoperability across the diverse data landscape and empowers teams to focus on application logic and not infrastructure decisions.
X
Y
Z
Zeppelin
Interactive data visualization
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
- ZooKeeper - Coordination and state management
Incubator - Heron
A realtime, distributed, fault-tolerant stream processing engine from Twitter