Apache Flink
Apache Flink is a stream processing framework that can also handle batch tasks. It considers batches to simply be data streams with finite boundaries, and thus treats batch processing as a subset of stream processing. This stream-first approach to all processing has a number of interesting side effects.
This stream-first approach has been called the Kappa architecture, in contrast to the more widely known Lambda architecture (where batching is used as the primary processing method with streams used to supplement and provide early but unrefined results). Kappa architecture, where streams are used for everything, simplifies the model and has only recently become possible as stream processing engines have grown more sophisticated.
Stream Processing Model
Flink's stream processing model handles incoming data on an item-by-item basis as a true stream. Flink provides its DataStream API to work with unbounded streams of data. The basic components that Flink works with are:
- Streams are immutable, unbounded datasets that flow through the system
- Operators are functions that operate on data streams to produce other streams
- Sources are the entry point for streams entering the system
- Sinks are the place where streams flow out of the Flink system. They might represent a database or a connector to another system
Stream processing tasks take snapshots at set points during their computation to use for recovery in case of problems. For storing state, Flink can work with a number of state backends depending with varying levels of complexity and persistence.
Additionally, Flink's stream processing is able to understand the concept of "event time", meaning the time that the event actually occurred, and can handle sessions as well. This means that it can guarantee ordering and grouping in some interesting ways.
Batch Processing Model
Flink's batch processing model in many ways is just an extension of the stream processing model. Instead of reading from a continuous stream, it reads a bounded dataset off of persistent storage as a stream. Flink uses the exact same runtime for both of these processing models.
Flink offers some optimizations for batch workloads. For instance, since batch operations are backed by persistent storage, Flink removes snapshotting from batch loads. Data is still recoverable, but normal processing completes faster.
Another optimization involves breaking up batch tasks so that stages and components are only involved when needed. This helps Flink play well with other users of the cluster. Preemptive analysis of the tasks gives Flink the ability to also optimize by seeing the entire set of operations, the size of the data set, and the requirements of steps coming down the line.
Advantages and Limitations
Flink is currently a unique option in the processing framework world. While Spark performs batch and stream processing, its streaming is not appropriate for many use cases because of its micro-batch architecture. Flink's stream-first approach offers low latency, high throughput, and real entry-by-entry processing.
Flink manages many things by itself. Somewhat unconventionally, it manages its own memory instead of relying on the native Java garbage collection mechanisms for performance reasons. Unlike Spark, Flink does not require manual optimization and adjustment when the characteristics of the data it processes change. It handles data partitioning and caching automatically as well.
Flink analyzes its work and optimizes tasks in a number of ways. Part of this analysis is similar to what SQL query planners do within relationship databases, mapping out the most effective way to implement a given task. It is able to parallelize stages that can be completed in parallel, while bringing data together for blocking tasks. For iterative tasks, Flink attempts to do computation on the nodes where the data is stored for performance reasons. It can also do "delta iteration", or iteration on only the portions of data that have changes.
In terms of user tooling, Flink offers a web-based scheduling view to easily manage tasks and view the system. Users can also display the optimization plan for submitted tasks to see how it will actually be implemented on the cluster. For analysis tasks, Flink offers SQL-style querying, graph processing and machine learning libraries, and in-memory computation.
Flink operates well with other components. It is written to be a good neighbor if used within a Hadoop stack, taking up only the necessary resources at any given time. It integrates with YARN, HDFS, and Kafka easily. Flink can run tasks written for other processing frameworks like Hadoop and Storm with compatibility packages.
One of the largest drawbacks of Flink at the moment is that it is still a very young project. Large scale deployments in the wild are still not as common as other processing frameworks and there hasn't been much research into Flink's scaling limitations. With the rapid development cycle and features like the compatibility packages, there may begin to be more Flink deployments as organizations get the chance to experiment with it.
Summary
Flink offers both low latency stream processing with support for traditional batch tasks. Flink is probably best suited for organizations that have heavy stream processing requirements and some batch-oriented tasks. Its compatibility with native Storm and Hadoop programs, and its ability to run on a YARN-managed cluster can make it easy to evaluate. Its rapid development makes it worth keeping an eye on.
Getting Started
Getting Started | Apache Flink
Source Tables
As with all SQL engines, Flink queries operate on top of tables. It differs from a traditional database because Flink does not manage data at rest locally; instead, its queries operate continuously over external tables.
Flink data processing pipelines begin with source tables. Source tables produce rows operated over during the query’s execution; they are the tables referenced in the FROM clause of a query. These could be Kafka topics, databases, filesystems, or any other system that Flink knows how to consume.
Tables can be defined through the SQL client or using environment config file. The SQL client support SQL DDL commands similar to traditional SQL. Standard SQL DDL is used to create, alter, drop tables.
Flink has a support for different connectors and formats that can be used with tables. Following is an example to define a source table backed by a CSV file with emp_id, name, dept_id as columns in a CREATE table statement.
SHOW FUNCTIONS;
CREATE TABLE employee_information (
emp_id INT,
name VARCHAR,
dept_id INT
) WITH (
'connector' = 'filesystem',
'path' = '/path/to/something.csv',
'format' = 'csv'
);
SELECT * from employee_information WHERE dept_id = 1;
WaterMarks
- Understanding Watermarks in Apache Flink | by Giannis Polyzos | Medium
- Watermark | Apache Flink
- Event Time and Watermarks | Apache Flink 101 - YouTube
- Windowing and Watermarks in Flink | Flink with Java - YouTube
Apache Flink- Stateful Computations over Data Streams
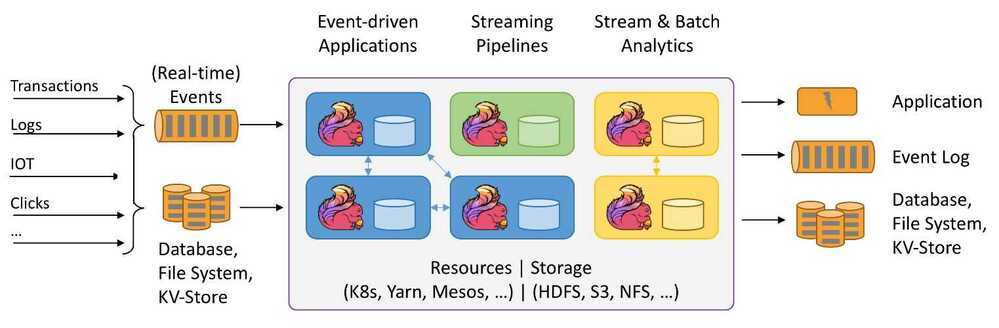
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Streaming dataflow engine for Java
TaskManager Memory
Set up TaskManager Memory | Apache Flink
The TaskManager runs user code in Flink. Configuring memory usage for your needs can greatly reduce Flink’s resource footprint and improve Job stability.
Detailed Memory Model

PyFlink
PyFlink is a Python API for Apache Flink that allows you to build scalable batch and streaming workloads, such as real-time data processing pipelines, large-scale exploratory data analysis, Machine Learning (ML) pipelines and ETL processes. If you’re already familiar with Python and libraries such as Pandas, then PyFlink makes it simpler to leverage the full capabilities of the Flink ecosystem. Depending on the level of abstraction you need, there are two different APIs that can be used in PyFlink:
- The PyFlink Table API allows you to write powerful relational queries in a way that is similar to using SQL or working with tabular data in Python.
- At the same time, the PyFlink DataStream API gives you lower-level control over the core building blocks of Flink, state and time, to build more complex stream processing use cases.
Links
- PyFlink Docs — pyflink-docs version master
- List: Pyflink Kafka Getting Started - Table API, UDFs and more | Curated by Diptiman Raichaudhuri | Medium
- GitHub - diptimanr/kafka_flink_getting_started: pyflink Table API and FLink SQL on Kafka
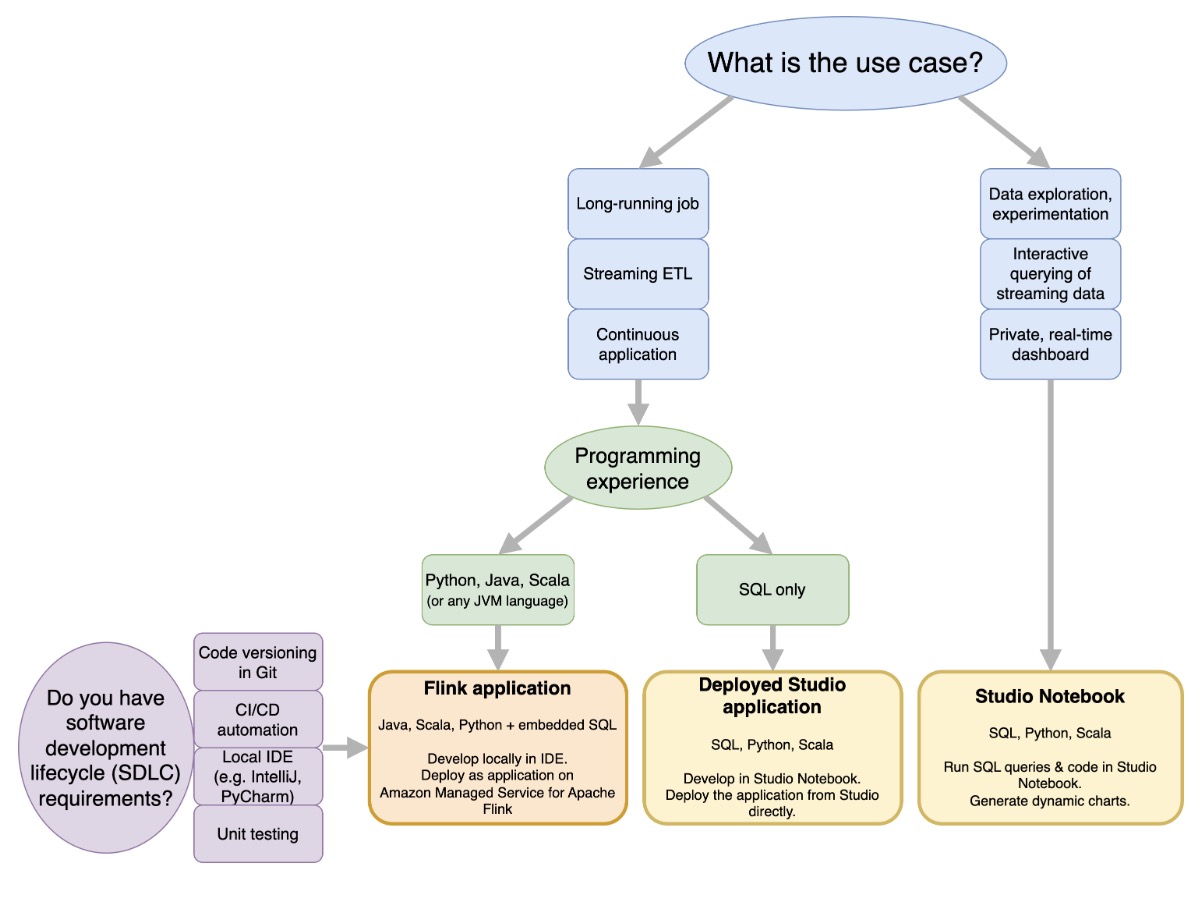
Amazon Managed Service for Apache Flink
With Amazon Managed Service for Apache Flink, you can use Java, Scala, Python, or SQL to process and analyze streaming data. The service enables you to author and run code against streaming sources and static sources to perform time-series analytics, feed real-time dashboards, and metrics.
Managed Service for Apache Flink provides the underlying infrastructure for your Apache Flink applications. It handles core capabilities like provisioning compute resources, AZ failover resilience, parallel computation, automatic scaling, and application backups (implemented as checkpoints and snapshots). You can use the high-level Flink programming features (such as operators, functions, sources, and sinks) in the same way that you use them when hosting the Flink infrastructure yourself.
Stream Processing - Amazon Managed Service for Apache Flink - AWS
What is Amazon Managed Service for Apache Flink? - Managed Service for Apache Flink
Uber - IngestionNext
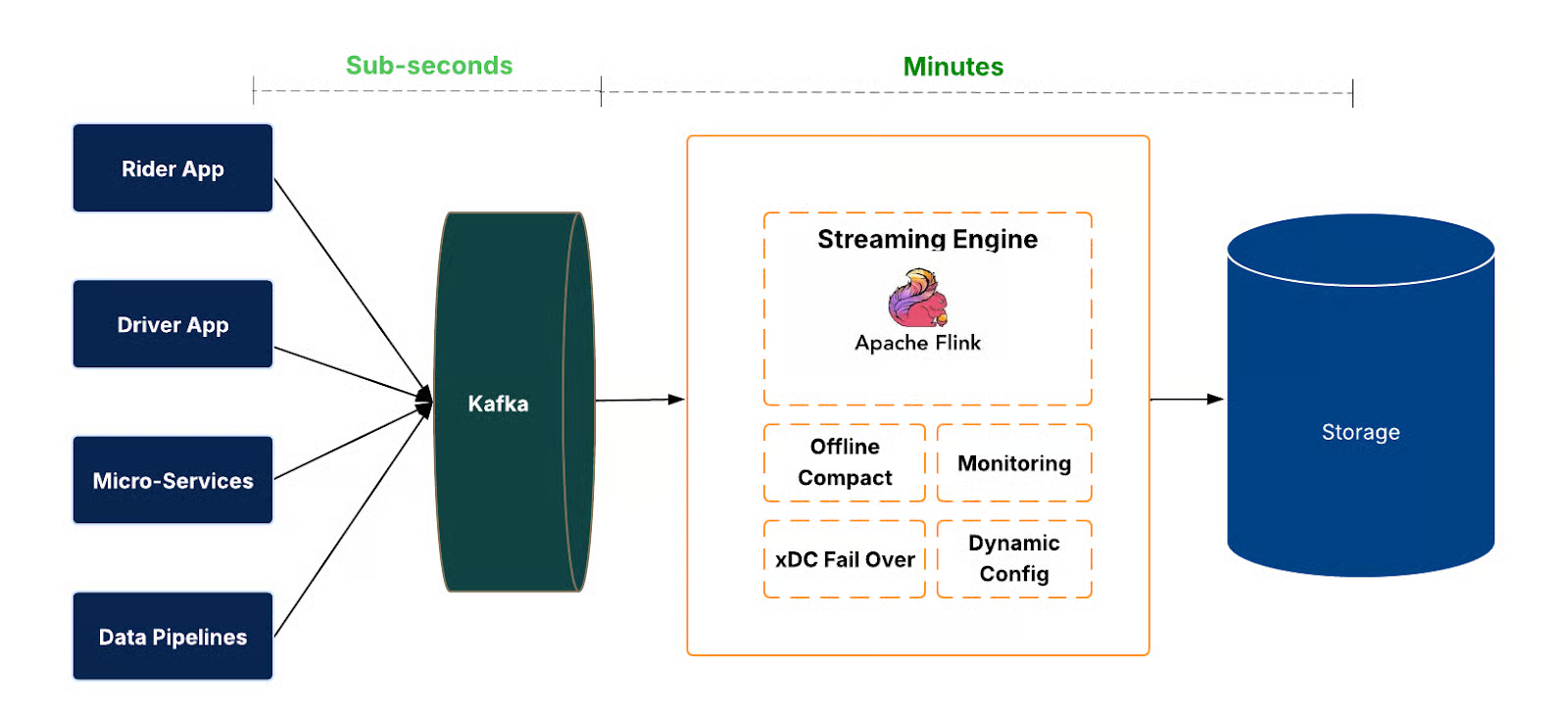
At the data plane, events arrive in Apache Kafka® and are consumed by Flink jobs. These jobs write to the data lake in Apache Hudi™ format, providing transactional commits, rollbacks, and time travel. Freshness and completeness are measured end-to-end, from source to sink.
Managing ingestion at scale requires automation. We designed a control plane that handles the job life cycle (create, deploy, restart, stop, delete), configuration changes, and health verification. This enables operating ingestion across thousands of datasets consistently and safely.
The system is also designed with regional failover and fallback strategies to maintain availability. In the event of outages, ingestion jobs can shift across regions or temporarily run in batch mode, ensuring continuity and no data loss.
Challenges
- Small file generation
- Streaming ingestion often generates many small Apache Parquet™ files, which significantly degrade query performance and increase metadata and storage overhead. This is a common challenge when data arrives continuously and must be written in near real time.
- The traditional and most common merging method operates record by record, requiring each Parquet file to be decompressed, decoded from columnar to row format, merged, and then re-encoded and compressed again. While functional, this approach is computationally heavy and slow due to repetitive encode/decode transformations.
- Partition skew
- Another problem we faced was that short-lived downstream slowdowns (like garbage collection pauses) can unbalance Kafka consumption across Flink subtasks. Skewed data leads to less efficient compression and slower queries.
- We addressed this through operational tuning (aligning parallelism with partitions, adjusting fetch parameters), connector-level fairness (round-robin polling, pause/resume for heavy partitions, per-partition quotas), and improved observability (per-partition lag metrics, skew-aware autoscaling, and targeted alerts).
- Checkpoint and Commit Synchronization
- We also found that Flink checkpoints track consumed offsets, while Hudi commits track writes. If they become misaligned during a failure, data can be skipped or duplicated.
- To solve this problem, we extended Hudi commit metadata to embed Flink checkpoint IDs, enabling deterministic recovery during rollbacks or failovers.
From Batch to Streaming: Accelerating Data Freshness in Uber’s Data Lake | Uber Blog
Links
- 06-sliding-window-analytics
- Apache Flink® SQL
- Apache Flink® SQL - YouTube
- https://dzone.com/articles/introduction-to-streaming-etl-with-apache-flink
- https://flink.apache.org/flink-architecture.html
- CDC Stream Processing with Apache Flink
- Apache Flink 1.19 - Deprecations, New Features, and Improvements
- Krones real-time production line monitoring with Amazon Managed Service for Apache Flink | AWS Big Data Blog
- Welcome to Amazon Managed Service for Apache Flink learning series | Amazon Web Services - YouTube
- Dynamic Tables | Apache Flink
- What is Apache Flink®?
- Apache Kafka Vs. Apache Flink
- Apache Flink - A Must-Have For Your Streams | Systems Design Interview 0...
- Apache Spark Vs. Apache Flink Vs. Apache Kafka Vs. Apache Storm! Data St...
- Stateless vs Stateful Stream Processing with Kafka Streams and Apache Flink
- Consume Apache Kafka Messages using Apache Flink and Java