Apache Hudi: Incremental Data Processing
Hudi - Hadoop Upserts Deletes and Incremental
Apache Hudi ingests & manages storage of large analytical datasets over DFS (hdfs or cloud stores).
Apache Hudi is a transactional data lake platform that brings database and data warehouse capabilities to the data lake. Hudi reimagines slow old-school batch data processing with a powerful new incremental processing framework for low latency minute-level analytics.

Hudi Features
- Mutability support for all data lake workloads - Quickly update & delete data with Hudi’s fast, pluggable indexing. This includes streaming workloads, with full support for out-of-order data, bursty traffic & data deduplication.
- Improved efficiency by incrementally processing new data - Replace old-school batch pipelines with incremental streaming on your data lake. Experience faster ingestion and lower processing times for analytical workloads.
- ACID Transactional guarantees to your data lake - Bring transactional guarantees to your data lake, with consistent, atomic writes and concurrency controls tailored for longer-running lake transactions.
- Unlock historical data with time travel - Query historical data with the ability to roll back to a table version; debug data versions to understand what changed over time; audit data changes by viewing the commit history.
- Interoperable multi-cloud ecosystem support - Extensive ecosystem support with plug-and-play options for popular data sources & query engines. Build future-proof architectures interoperable with your vendor of choice.
- Comprehensive table services for high-performance analytics - Fully automated table services that continuously schedule & orchestrate clustering, compaction, cleaning, file sizing & indexing to ensure tables are always ready.
- A rich platform to build your lakehouse faster - Effortlessly build your lakehouse with built-in tools for auto ingestion from services like Debezium and Kafka and auto catalog sync for easy discoverability & more.
- Query acceleration through multi-modal indexes - Experience faster write transactions on huge/wide tables & faster query performance with first-of-its kind multi-modal indexing subsystem.
- Resilient Pipelines with schema evolution & enforcement - Easily change the current schema of a Hudi table to adapt to the data that is changing over time and ensure pipeline resilience by failing fast and avoiding data corruption.
Original Motivation
- Batch ingestion is too slow
- Rewrite entire table/partition several times a day
- ETLs off raw data have no smarts to recompute
- Late arriving data is a nightmare
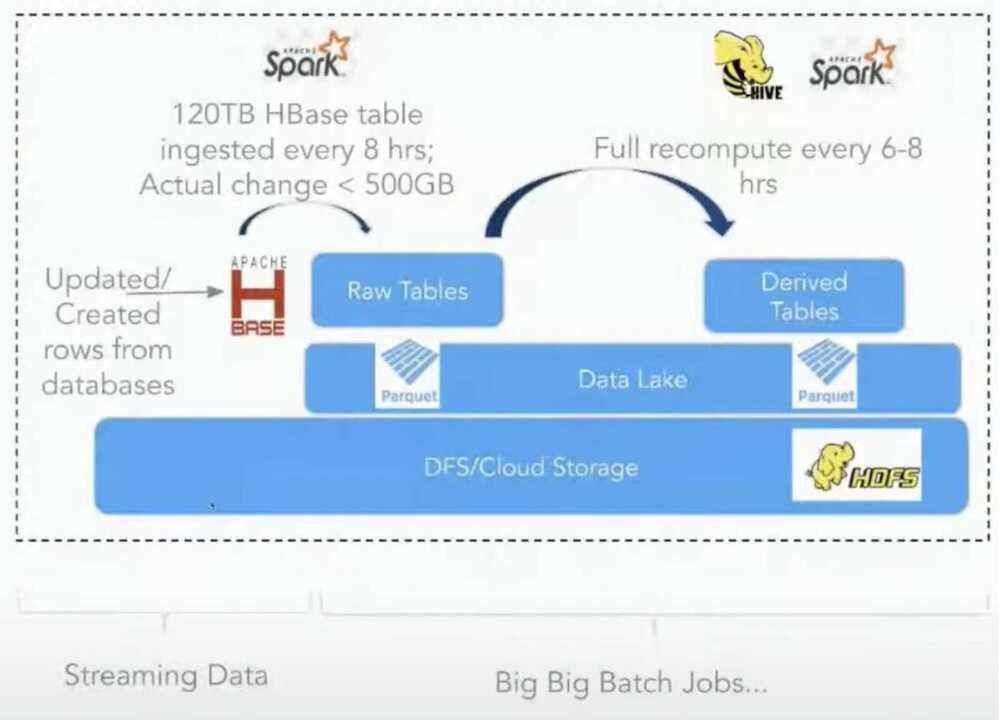
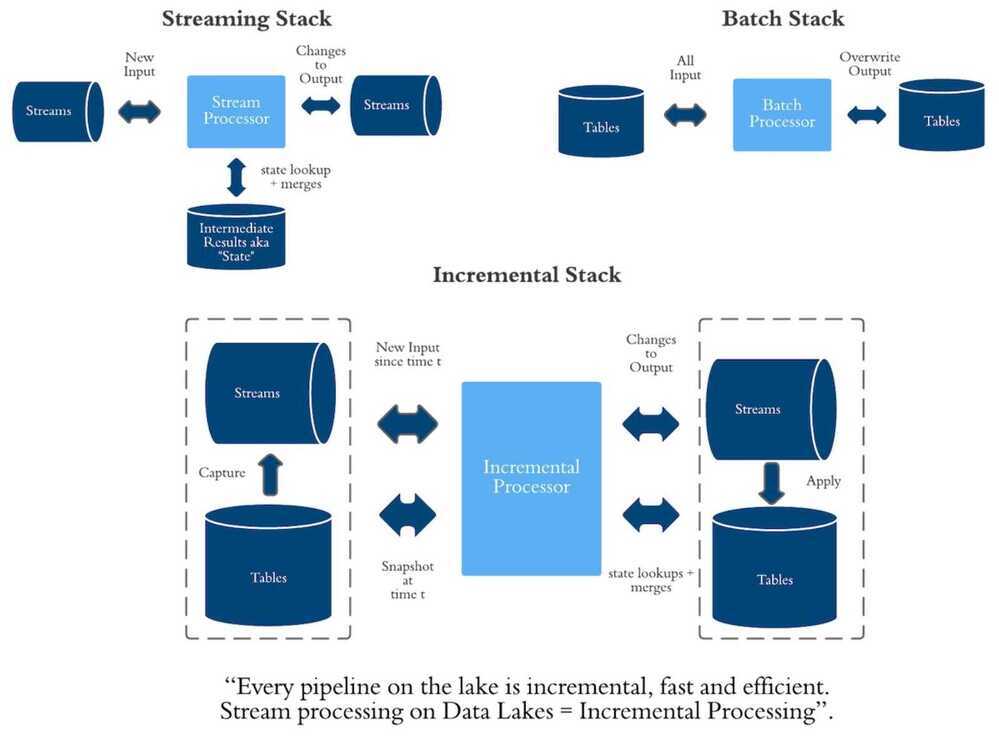
Architecture
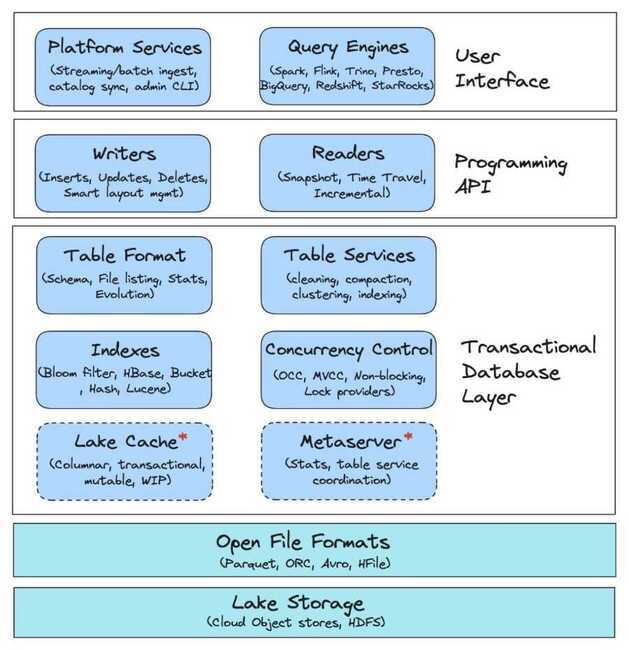
Storage Type
Copy On Write (COW)
Queries: Snapshot, Incremental
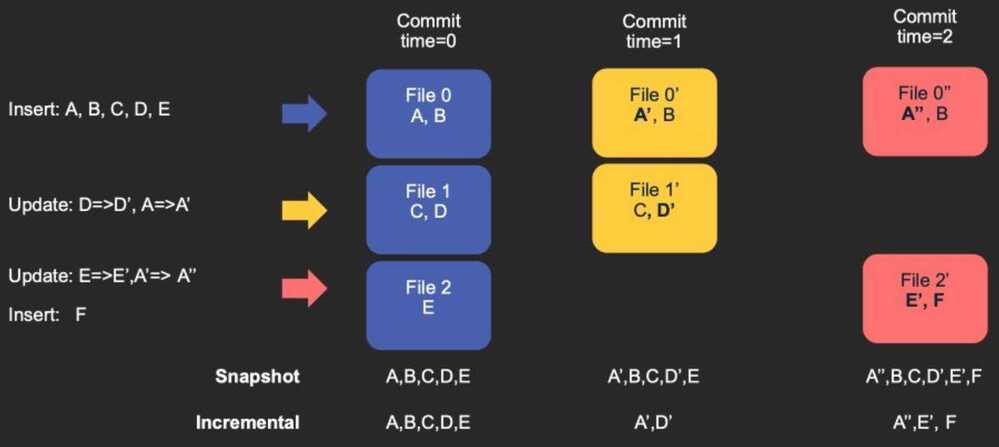
Merge on read (MOR)
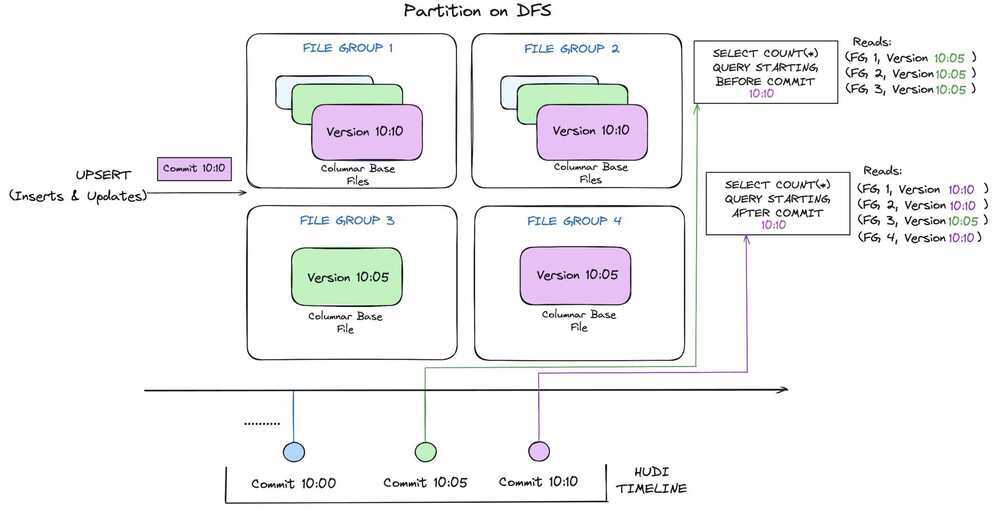
Choosing Between COW and MOR
The choice between COW and MOR in Apache Hudi largely depends on your specific requirements.
- Read vs. Write Frequency: If your workload is read-heavy, COW may be the better choice due to its optimized read performance. Conversely, for write-heavy applications where data is ingested frequently, MOR can handle the load more efficiently.
- Data Consistency: If your application requires strong consistency and atomicity during writes, COW is preferable. MOR is better suited for scenarios where eventual consistency is acceptable.
- Use Case: For analytical workloads and batch processing, COW shines. For real-time data processing and streaming applications, MOR is often the way to go.
Apache Hudi 1.0 Release
- Secondary Indexing - 95% decreased query latency with additional indexes that accelerate queries beyond primary keys. For example, build a Bloom Index on any column using new SQL syntax to create/drop indexes asynchronously.
- Expression Indexes - Borrowing a page from Postgres, you can now define indexes as expressions of columns. This allows you to build crucial metadata for data skipping without relying on table schema or directory structures typically needed for partitioning.
- Partial Updates - 2.6x performance boost and 85% reduction in write amplification with MERGE INTO SQL statements that modify only changed fields of a record, massively improving performance for update-heavy workloads.
- Non-blocking Concurrency Control - Simultaneous writing from multiple writers and compaction of the same record without blocking processes, achieved via lightweight distributed locks and new TrueTime semantics.
- Merge Modes - First-class support for both stream processing styles: commit_time_ordering, event_time_ordering, and custom record merger APIs.
- LSM Timeline - A revamped timeline storing all action history as a scalable LSM tree, enabling users to retain extensive table history.
- TrueTime - Strengthened TrueTime semantics, ensuring forward-moving clocks for distributed processes with a maximum tolerable clock skew, similar to OLTP/NoSQL stores.
Announcing Apache Hudi 1.0 and the Next Generation of Data Lakehouses | Apache Hudi
Apache Hudi vs Clickhouse
Apache Hudi and ClickHouse are both powerful tools in the data ecosystem, but they serve different purposes, making them complementary in many use cases rather than direct competitors.
1. Overview
| Feature | Apache Hudi | ClickHouse |
|---|---|---|
| Purpose | Data management for data lakes with support for mutability (upserts, deletes) and incremental processing. | OLAP database optimized for real-time analytics with focus on high-speed aggregation and query performance. |
| Best Use Case | Managing mutable datasets in a data lake (e.g., CDC pipelines, data lakehouse architecture). | Running real-time, ad-hoc, and analytical queries on immutable data with very low latency. |
2. Key Features
| Feature | Apache Hudi | ClickHouse |
|---|---|---|
| Data Storage | Stores data in Amazon S3, HDFS, or other cloud object storage, organized as CoW or MoR tables. | Stores data on disk in a columnar format for fast analytical queries. |
| Mutability | Supports upserts, deletes, and incremental updates. Ideal for mutable datasets. | Immutable; requires rebuilding partitions or tables for updates. |
| Query Engines | Queryable via Presto/Trino, Athena, Spark, Hive. | Native SQL engine optimized for real-time analytics. |
| Performance | Optimized for write-heavy workloads with background compactions and incremental reads. | Optimized for read-heavy workloads with fast queries and low-latency analytics. |
| Cost Efficiency | Cost-effective for large-scale storage on S3 with efficient updates and reads. | Requires dedicated servers with high-performance hardware (e.g., SSDs, memory). |
3. Real-Time Data Ingestion
| Feature | Apache Hudi | ClickHouse |
|---|---|---|
| Data Ingestion | Real-time ingestion via Hudi DeltaStreamer or frameworks like Flink and Spark. | Real-time ingestion through Kafka Connect or direct batch loads. |
| Stream Processing | Supports incremental writes to storage, with options for compaction (CoW/MoR modes). | Requires entire batches to be ingested; data is immutable once written. |
4. Querying Capabilities
| Feature | Apache Hudi | ClickHouse |
|---|---|---|
| Ad-Hoc Querying | Query Hudi datasets via Presto/Trino, Athena, or other query engines. Performance depends on the engine. | Native SQL interface delivers sub-second query results for large datasets. |
| Real-Time Queries | MoR tables can provide low-latency querying, but not as fast as ClickHouse. | Designed for real-time, high-frequency queries on structured data. |
5. Scalability
| Feature | Apache Hudi | ClickHouse |
|---|---|---|
| Storage Layer | Scales with object storage (S3, HDFS), decoupled from compute. | Scales with cluster size but tightly couples storage and compute. |
| Data Volume | Handles petabyte-scale data lakes effectively. | Handles terabyte-scale analytical datasets; large-scale datasets require careful tuning. |
6. When to Choose Hudi
- Use Cases:
- CDC Pipelines: Managing Change Data Capture from databases.
- Data Lakehouse: Incremental data updates with near real-time querying.
- ETL Pipelines: As a staging layer for transforming and cleaning data.
- Strengths:
- Cost-effective for large, mutable datasets.
- Works well with existing data lake architectures (e.g., S3, HDFS).
- Limitations:
- Query latency may not match ClickHouse for highly interactive analytics.
7. When to Choose ClickHouse
- Use Cases:
- Real-Time Dashboards: Low-latency analytics for user-facing dashboards.
- Ad-Hoc Analytics: High-speed querying of structured and semi-structured data.
- Event Analytics: Time-series analysis, log analytics, and performance monitoring.
- Strengths:
- Extremely fast read performance for analytics.
- Native SQL capabilities and real-time aggregations.
- Limitations:
- Updates require significant effort (e.g., re-ingestion).
- Costs can rise with larger datasets due to hardware requirements.
8. Example Architecture for Combined Use
You can combine Hudi and ClickHouse to leverage their strengths:
-
Ingestion:
- Stream data from Kafka (Confluent Cloud) into both Hudi (S3) and ClickHouse.
- Use Flink or Spark to process data for Hudi and aggregate it for ClickHouse.
-
Hudi for Data Lake:
- Store the complete dataset in Hudi on S3 for cost-effective storage and long-term querying.
- Provide incremental updates and CDC support.
-
ClickHouse for Analytics:
- Store aggregated data and important metrics in ClickHouse for real-time dashboards and ad-hoc analytics.
Decision Matrix
| Criteria | Apache Hudi | ClickHouse |
|---|---|---|
| Real-Time Analytics | Moderate (MoR tables) | Excellent |
| Mutable Datasets | Excellent | Poor |
| Query Performance | Moderate (depends on engine) | Excellent |
| Cost Efficiency | High | Moderate (requires dedicated infra) |
| Scale | Petabyte-scale | Terabyte-scale |
In summary:
- Use Hudi for managing mutable datasets in a data lake.
- Use ClickHouse for real-time, interactive analytics where query speed is critical.
Links
- https://hudi.apache.org
- Apache Hudi: A Deep Dive with Python Code Examples
- Apache Hudi vs. Delta Lake: Choosing the Right Tool for Your Data Lake on AWS | by Siladitya Ghosh | Medium
- Exploring Time Travel Queries in Apache Hudi - DEVOPS DONE RIGHT..
- Understanding COW and MOR in Apache Hudi: Choosing the Right Storage Strategy - DEVOPS DONE RIGHT..
- Apache Hudi vs Delta Lake vs Apache Iceberg - Data Lakehouse Feature Comparison
- Apache Hudi: A Database Layer Over Cloud Storage for Fast Mutations & Queries (Vinoth Chandar) - YouTube