Queries
SELECT * REPLACE
SELECT * EXCEPT
SQL comparison
BigQuery standard SQL supports compliance with the SQL 2011 standard and has extensions that support querying nested and repeated data. Redshift SQL is based on PostgreSQL but has several differences which are detailed in the Redshift documentation. For a detailed comparison between Redshift and BigQuery SQL syntax and functions, see the Redshift to BigQuery SQL translation reference.
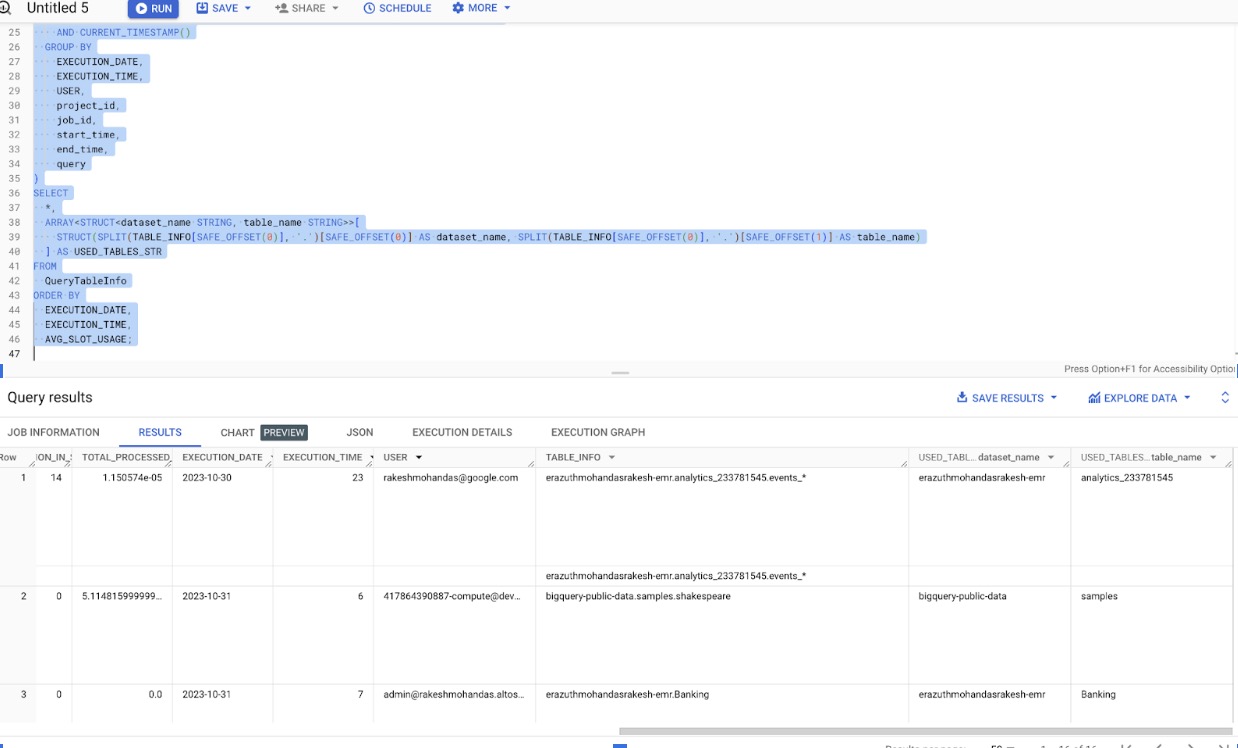
BigQuery Table usage in a Query - Information Schema
Best Practice: Utilize Expiration Settings
To optimize your BigQuery usage, it is crucial to manage the lifecycle of your tables and partitions effectively. By configuring expiration settings, you can automatically remove unneeded tables and partitions, thus saving storage costs and maintaining a clean dataset environment.
- Default Table Expiration for Datasets: Set a default expiration time for all new tables created in a dataset. This ensures that any table not explicitly configured with an expiration date will be automatically deleted after the specified period.
- Table Expiration: Define specific expiration times for individual tables. This allows you to control the retention period for each table based on its relevance and usage patterns.
- Partition Expiration for Partitioned Tables: For partitioned tables, configure expiration times at the partition level. This helps in managing data retention for specific time periods within the table, such as removing older data while retaining recent data.
Implementing these expiration settings helps in automating data lifecycle management, reducing manual efforts, and optimizing storage costs.
Identifying Tables That Are Not Being Used for a Long Time
The following query is essential for customers using Google BigQuery because it identifies and records which tables are utilized in each SQL query. By extracting dataset and table names from the queries, it offers a clear understanding of which tables are accessed during query executions. This information is invaluable for data governance, query optimization, and resource allocation.
- Data Governance: Understanding which tables are accessed ensures that you can maintain data integrity and security. You can manage access controls more effectively and ensure sensitive data is only accessed by authorized users.
- Query Optimization: By identifying frequently accessed tables, you can prioritize optimization efforts, such as indexing or restructuring data, to improve query performance.
- Resource Allocation: Analyzing table usage patterns allows for informed decisions about dataset organization and resource allocation, ensuring efficient use of the BigQuery environment.
- Historical Context: Tracking changes in table usage patterns over time provides insights into data usage evolution. This helps predict future trends and plan capacity accordingly.
Overall, this query enhances transparency and control over table dependencies within BigQuery, facilitating better data management and query performance optimization.
WITH QueryTableInfo AS (
SELECT
project_id,
job_id,
start_time,
end_time,
query,
COUNT(*) TOTAL_QUERIES,
SUM(
total_slot_ms / TIMESTAMP_DIFF(
end_time, creation_time, MILLISECOND
)
) AVG_SLOT_USAGE,
SUM(
TIMESTAMP_DIFF(end_time, creation_time, SECOND)
) TOTAL_DURATION_IN_SECONDS,
AVG(
TIMESTAMP_DIFF(end_time, creation_time, SECOND)
) AVG_DURATION_IN_SECONDS,
MAX(
TIMESTAMP_DIFF(end_time, creation_time, SECOND)
) Max_DURATION_IN_SECONDS,
SUM(total_bytes_processed * 10e - 12) TOTAL_PROCESSED_TB,
EXTRACT(
DATE
FROM
creation_time
) AS EXECUTION_DATE,
EXTRACT(
HOUR
FROM
creation_time
) AS EXECUTION_TIME,
user_email AS USER,
-- Extract dataset and table names separately using regular expression
REGEXP_EXTRACT_ALL(query, r '`([^`]+)`') AS TABLE_INFO
FROM
`dealshare-d82f7.region-asia-south1.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
state = 'DONE'
AND statement_type = 'SELECT'
AND creation_time BETWEEN TIMESTAMP_SUB(
CURRENT_TIMESTAMP(),
INTERVAL 1 DAY
)
AND CURRENT_TIMESTAMP()
GROUP BY
EXECUTION_DATE,
EXECUTION_TIME,
USER,
project_id,
job_id,
start_time,
end_time,
query
)
SELECT
*,
ARRAY < STRUCT < dataset_name STRING,
table_name STRING >> [ STRUCT(
SPLIT(
TABLE_INFO[SAFE_OFFSET(0) ],
'.'
) [SAFE_OFFSET(0) ] AS dataset_name,
SPLIT(
TABLE_INFO[SAFE_OFFSET(0) ],
'.'
) [SAFE_OFFSET(1) ] AS table_name
) ] AS USED_TABLES_STR
FROM
QueryTableInfo
ORDER BY
EXECUTION_DATE,
EXECUTION_TIME,
AVG_SLOT_USAGE;
With the changes above that can be implemented for BigQuery storage costs, one could have potential savings of around 20-30% by switching from logical storage to physical storage, though actual savings may vary based on the data type.
Optimizing Streaming Insert Cost
Recommendation: Optimize Streaming Insert Operations
Streaming inserts can contribute significantly to BigQuery costs, especially at scale. Consider the following strategies to optimize streaming insert costs:
- Batch Inserts: Instead of streaming data continuously, batch your inserts where possible. This reduces the frequency of insert operations and can lead to lower overall costs.
- Use of Cloud Pub/Sub: If feasible, use Cloud Pub/Sub to batch and deliver messages to BigQuery in larger chunks rather than individually. This reduces the number of insert operations and can optimize costs.
- Control Data Volume: Implement data filtering and validation before data reaches BigQuery to reduce unnecessary data ingestion, thus lowering costs.
- If you're using Google Analytics for Firebase or Google Analytics to stream data into BigQuery, optimizing streaming costs involves understanding how data flows and making strategic adjustments. Here are several ways to reduce streaming costs in this context:
- Google Analytics allows you to adjust the data sampling rate, which affects the volume of data streamed into BigQuery. By lowering the sampling rate, especially for less critical or less frequently analyzed data, you can reduce the volume of data being processed and thereby lower costs.
- Adjust sampling settings in Google Analytics to strike a balance between data accuracy and cost efficiency. Focus high sampling on critical data and lower it for less critical data.
- Event Filtering: Configure Firebase or Google Analytics to filter out events that are not necessary for your analysis, reducing the volume of data being ingested.
- Data Transformation: Use Firebase functions or Google Cloud Functions to pre-process and filter data before it enters BigQuery, ensuring only relevant data is streamed.
Data scanning analysis
-- find how much data is being scanned by month
SELECT
FORMAT_TIMESTAMP('%Y-%m', creation_time) AS month,
ROUND(SUM(total_bytes_processed) / POW(2, 30), 2) AS total_gb_scanned
FROM
`region-asia-south1.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
state = 'DONE'
AND job_type = 'QUERY'
AND creation_time BETWEEN TIMESTAMP('2024-01-01') AND CURRENT_TIMESTAMP()
GROUP BY
month
ORDER BY
month;
-- find how much data is being scanned by day
SELECT
FORMAT_TIMESTAMP('%Y-%m-%d', creation_time) AS day,
ROUND(SUM(total_bytes_processed) / POW(2, 30), 2) AS total_gb_scanned
FROM
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
state = 'DONE'
AND job_type = 'QUERY'
AND creation_time BETWEEN TIMESTAMP('2025-01-01') AND CURRENT_TIMESTAMP()
GROUP BY
day
ORDER BY
day;
-- find the top queries that scanned the most amount of data
SELECT
query,
user_email,
COUNT(*) AS query_count,
ROUND(SUM(total_bytes_processed) / POW(2, 30), 2) AS total_gb_scanned,
ROUND(SUM(total_bytes_processed) / COUNT(*) / POW(2, 30), 2) AS avg_gb_scanned_per_query,
ARRAY_AGG(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', creation_time) ORDER BY creation_time) AS query_run_timestamps
FROM
`region-asia-south1.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
state = 'DONE'
AND job_type = 'QUERY'
AND creation_time BETWEEN TIMESTAMP('2025-01-01') AND CURRENT_TIMESTAMP()
GROUP BY
query,
user_email
ORDER BY
total_gb_scanned DESC
LIMIT 10;
SQL
-- standardSQL
SELECT
departure_airport,
arrival_airport,
COUNT(1) AS num_flights
FROM
`bigquery-samples.airline_ontime_data.flights`
GROUP BY
departure_airport,
arrival_airport
ORDER BY
num_flights DESC
LIMIT
10
-- standardSQL
SELECT
departure_delay,
COUNT(1) AS num_flights,
APPROX_QUANTILES(arrival_delay, 5) AS arrival_delay_quantiles
FROM
`bigquery-samples.airline_ontime_data.flights`
GROUP BY
departure_delay
HAVING
num_flights > 100
ORDER BY
departure_delay ASC
-- get all datasets
SELECT
schema_name AS dataset_id
FROM
`project_id.region-asia-south1.INFORMATION_SCHEMA.SCHEMATA`;
-- size of each dataset
SELECT SUM(size_bytes) AS bytes FROM dataset.__TABLES__;
-- size of tables desc for a dataset
SELECT
table_id,
size_bytes / (1024 * 1024 * 1024) AS table_size_gb
FROM
`dataset_id.__TABLES__`
ORDER BY
table_size_gb DESC;
-- get count of tables
SELECT
table_schema,
COUNT(*) AS number_of_tables
FROM
`dealshare-d82f7.region-asia-south1.INFORMATION_SCHEMA.TABLES`
GROUP BY
table_schema
order by number_of_tables desc;
-- delete data from specific table
TRUNCATE TABLE `dataset-name.database_name.table_name`;
Commands
from google.cloud import bigquery
client = bigquery.Client()
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
dataset_ref = client.dataset("chicago_crime", project="bigquery-public-data")
dataset = client.get_dataset(dataset_ref)