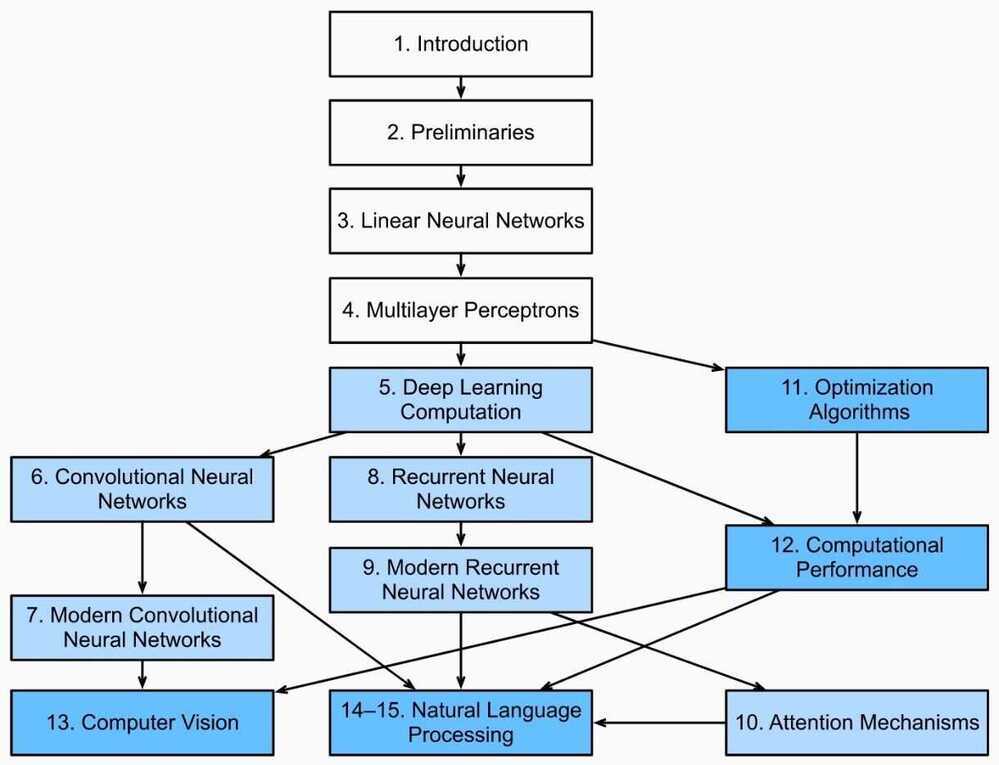
Table of contents
Preface - https://d2l.ai/chapter_preface/index.html
Notation - https://d2l.ai/chapter_notation/index.html
3.2. Linear Regression Implementation from Scratch
3.3. Concise Implementation of Linear Regression
3.5. The Image Classification Dataset
3.6. Implementation of Softmax Regression from Scratch
3.7. Concise Implementation of Softmax Regression
4.2. Implementation of Multilayer Perceptrons from Scratch
4.3. Concise Implementation of Multilayer Perceptrons
4.4. Model Selection, Underfitting, and Overfitting
4.7. Forward Propagation, Backward Propagation, and Computational Graphs
4.8. Numerical Stability and Initialization
4.9. Environment and Distribution Shift
4.10. Predicting House Prices on Kaggle
6. Convolutional Neural Networks
6.1. From Fully-Connected Layers to Convolutions
6.4. Multiple Input and Multiple Output Channels
6.6. Convolutional Neural Networks (LeNet)
7. Modern Convolutional Neural Networks
7.1. Deep Convolutional Neural Networks (AlexNet)
7.2. Networks Using Blocks (VGG)
7.4. Networks with Parallel Concatenations (GoogLeNet)
7.6. Residual Networks (ResNet)
7.7. Densely Connected Networks (DenseNet)
8.3. Language Models and the Dataset
8.4. Recurrent Neural Networks
8.5. Implementation of Recurrent Neural Networks from Scratch
8.6. Concise Implementation of Recurrent Neural Networks
8.7. Backpropagation Through Time
9. Modern Recurrent Neural Networks
9.1. Gated Recurrent Units (GRU)
9.2. Long Short-Term Memory (LSTM)
9.3. Deep Recurrent Neural Networks
9.4. Bidirectional Recurrent Neural Networks
9.5. Machine Translation and the Dataset
9.6. Encoder-Decoder Architecture
9.7. Sequence to Sequence Learning
10.2. Attention Pooling: Nadaraya-Watson Kernel Regression
10.3. Attention Scoring Functions
10.6. Self-Attention and Positional Encoding
11.1. Optimization and Deep Learning
11.4. Stochastic Gradient Descent
11.5. Minibatch Stochastic Gradient Descent
11.11. Learning Rate Scheduling
12.1. Compilers and Interpreters
12.2. Asynchronous Computation
12.5. Training on Multiple GPUs
12.6. Concise Implementation for Multiple GPUs
16.1. Overview of Recommender Systems
16.4. AutoRec: Rating Prediction with Autoencoders
16.5. Personalized Ranking for Recommender Systems
16.6. Neural Collaborative Filtering for Personalized Ranking
16.7. Sequence-Aware Recommender Systems
16.8. Feature-Rich Recommender Systems
16.10. Deep Factorization Machines
17. Generative Adversarial Networks
17.1. Generative Adversarial Networks
17.2. Deep Convolutional Generative Adversarial Networks
AI Conferences