MLOps / Model Deployment

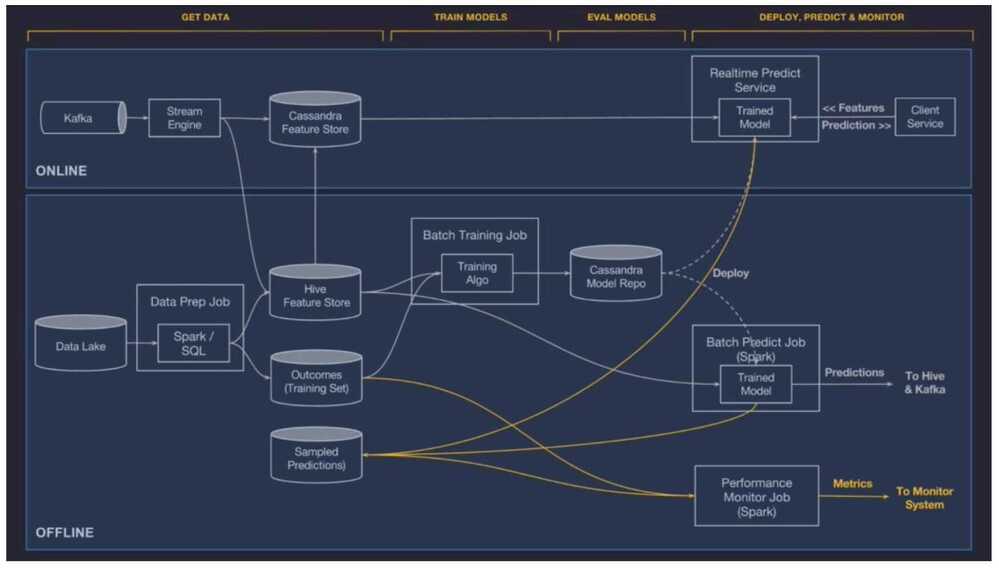
Offline Deployment
The model is deployed to an offline container and run in a Spark job to generate batch predictions either on demand or on a repeating schedule.
Online Deployment
The model is deployed to an online prediction service cluster (generally containing hundreds of machines behind a load balancer) where clients can send individual or batched prediction requests as network RPC calls.
Monitor predictions
DataOps
DataOps is an approach to data analytics and data-driven decision making that follows the agile development methodology of continuous improvement. The goal of DataOps is to reduce the cost of data management, improve data quality, and deliver insights to analysts and business users faster by creating datapipelines.
DataOps vs. DevOps: What's the Difference?
MLOps
MLOps is an engineering discipline that aims to unify ML systems development (dev) and ML systems deployment (ops) in order to standardize and streamline the continuous delivery of high-performing models in production.
ML Lifecycle
- Framing ML problems from business goals
- Access, prepare and process data for the model
- Architect ML solution and develop ML models
- Deploy ML models
- Iterate - Monitor, optimize and maintain the performance of the model
Deploying models to the production system
There are mainly two ways of deploying an ML model:
- Static deployment or embedded model - where the model is packaged into installable application software and is then deployed. For example, an application that offers batch-scoring of requests.
- Dynamic deployment - where the model is deployed using a web framework like FastAPI or Flask and is offered as an API endpoint that responds to user requests.
What is MLOps? Machine Learning Operations Explained
MLOps Course - Build Machine Learning Production Grade Projects - YouTube
MLOps Components
- Version Control
- CI/CD
- Orchestration
- Experiment Tracking & Model Registry
- Data Lineage & Feature Stores
- Model Training & Serving
- Monitoring & Observability
Tools
KubeFlow
Kubeflow is a Cloud Native platform for machine learning based on Google's internal machine learning pipelines.
https://github.com/kubeflow/kubeflow
TensorFlow Serving
TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. It deals with the inference aspect of machine learning, taking models after training and managing their lifetimes, providing clients with versioned access via a high-performance, reference-counted lookup table. TensorFlow Serving provides out-of-the-box integration with TensorFlow models, but can be easily extended to serve other types of models and data.
To note a few features:
- Can serve multiple models, or multiple versions of the same model simultaneously
- Exposes both gRPC as well as HTTP inference endpoints
- Allows deployment of new model versions without changing any client code
- Supports canarying new versions and A/B testing experimental models
- Adds minimal latency to inference time due to efficient, low-overhead implementation
- Features a scheduler that groups individual inference requests into batches for joint execution on GPU, with configurable latency controls
- Supports many servables: Tensorflow models, embeddings, vocabularies, feature transformations and even non-Tensorflow-based machine learning models
GitHub - tensorflow/serving: A flexible, high-performance serving system for machine learning models ⭐ 6.4k
Serving Models | TFX | TensorFlow
ONNX (Open Neural Network Exchange)
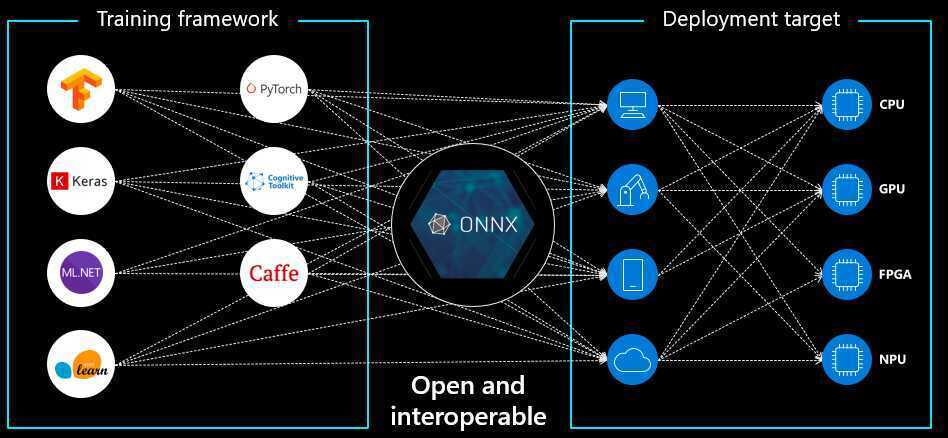
ONNX (Open Neural Network Exchange), an open-source format for representing deep learning models, was developed by Microsoft and is now managed by the Linux Foundation. It addresses the challenge of model packaging by providing a standardized format that enables easy transfer of machine learning models between different deep learning frameworks.
Since various deep learning frameworks use different formats to represent their models, using models trained in one framework with another can be challenging. ONNX resolves this issue by providing a standard format that multiple deep learning frameworks, including TensorFlow, PyTorch, and Caffe2 can use.
With ONNX, models can be trained in one framework and then easily exported to other frameworks for inference, making it convenient for developers to experiment with different deep learning frameworks and tools without having to rewrite their models every time they switch frameworks. It can execute models on various hardware platforms, including CPUs, GPUs, and FPGAs, making deploying models on various devices easy.
Seldon Core
An open source platform to deploy your machine learning models on Kubernetes at massive scale.
https://docs.seldon.io/projects/seldon-core/en/v1.1.0
Others
- ZenML - Seamless End-to-End MLOps
- Starter guide - ZenML Documentation
- Home Page | Pachyderm
- neptune.ai | Experiment tracker purpose-built for foundation models
- ML Model Packaging [The Ultimate Guide]
- Machine Learning: Models to Production | by Ashutosh Kumar | Analytics Vidhya | Medium
- Comet ML - Build better models faster
- GitHub - kitops-ml/kitops: An open source DevOps tool for packaging and versioning AI/ML models, datasets, code, and configuration into an OCI artifact. ⭐ 1.4k
Roadmap
sig-mlops/roadmap/2022/MLOpsRoadmap2022.md at main · cdfoundation/sig-mlops · GitHub ⭐ 631
Examples
Roadmap To Become A Successful MLOps Engineer - The Workfall Blog
Courses
The Full Stack 7-Steps MLOps Framework - Paul Iusztin
GitHub - DataTalksClub/mlops-zoomcamp: Free MLOps course from DataTalks.Club ⭐ 15k
Profiles
- Machine Learning Engineer Job Description Jan 2024 | Toptal
- Meghana Bhange - Developer in Montreal, QC, Canada | Toptal
- Alessandro Pedori - Developer in Berlin, Germany | Toptal
- Ruggiero Dargenio - Developer in Zürich, Switzerland | Toptal
- Andrei Apostol - Developer in Iași, Romania | Toptal
- Artificial Intelligence Resume Sample and Writing guide - 2024
Newsletter
- Pinterest introduces LinkSage, Google combines Neural Networks with Bayesian theory
- DSPy through a RAG System
- Pathscopes: Inspect Hidden Representation of Neural Networks!
- Personalizing Heart Rate Prediction
Links
- GitHub - graviraja/MLOps-Basics ⭐ 8.9k
- Ray | Faster Python
- Home - MLOps Community
- GitHub - visenger/awesome-mlops: A curated list of references for MLOps ⭐ 14k
- GitHub - kelvins/awesome-mlops: 😎 A curated list of awesome MLOps tools ⭐ 5.2k
- 10 Awesome Resources for Learning MLOps | DataCamp
- Let’s Architect! Learn About Machine Learning on AWS | AWS Architecture Blog
- AWS re:Invent 2023 - Introduction to MLOps engineering on AWS (TNC215) - YouTube
- AWS re:Invent 2023 - Zero to machine learning: Jump-start your data-driven journey (SMB204) - YouTube
- Step-by-Step Guide to Deploying ML Models with Docker
- End-to-End Machine Learning Project – AI, MLOps - YouTube
- ZenML
- MLflow
- KubeFlow
- GitHub - Meesho/BharatMLStack: BharatMLStack is an open-source, end-to-end machine learning infrastructure stack built at Meesho to support real-time and batch ML workloads at Bharat scale ⭐ 693
- The Full MLOps Blueprint: Background and Foundations for ML in Production
- If you would like to start learning MLOps in 2025, start with this : Day 1: Intro to MLOps: ML Meets DevOps: https://lxop.in/day1 Day 2: MLOps Tools Landscape: https://lxop.in/day2 Day 3: Data… | Sandip Das | 54 comments