Tools
Dagster
Dagster is a system for building modern data applications. Combining an elegant programming model and beautiful tools, Dagster allows infrastructure engineers, data engineers, and data scientists to seamlessly collaborate to process and produce the trusted, reliable data needed in today's world.
Data applications built with Dagster will have the following properties:
- Queryable, operable, and monitor-able by tools through an API.
- Constructed with data dependencies, rather than just execution dependencies. In addition to defining the execution order of computation within a graph, Dagster also expresses data flowing through a graph.
- Self-describing with well-defined metadata, consumable by users and tooling alike.
- Business logic defined in your tool of choice, from Spark, to Python, to SQL, to Jupyter notebooks, or any arbitrary computation.
- Executable in a number of environments - locally, within CI/CD pipelines, staging, production so forth - by having first-class abstractions that allow an author to modify their computing environment/context while leaving their business logic unchanged.
- Designed for local development, with an out-of-the-box IDE-esque tool called Dagit.
- Monitorable by emitting a structured stream of events during computation, rather than solely relying on unstructured logging. These events describes the semantic meaning of a computation using a well-defined API, consumable and interpretable by tooling.
- Able to describe their data using a type system which is gradual, flexible, and optional, allowing for incremental adoption. It is designed to supplement, not supplant, the type system of language or system that defines the actual computation.
- Designed for reuse. Solids describe their metadata, types, configuration, and resource requirements and are potentially reusable within many contexts.
- A typed configuration system, which enables high-quality error messages and tooling support, such as the config editor provided within Dagit.
- Targets existing computational infrastructure - e.g. Kubernetes, Airflow, Dask, FaaS platforms, etc - for scheduling and execution in a pluggable fashion. Airflow and Dask initially supported.
https://dagster.readthedocs.io/en/0.6.6
https://medium.com/dagster-io/introducing-dagster-dbd28442b2b7
https://dagster.readthedocs.io/en/stable/sections/learn/tutorial/index.html
Dagster: A New Programming Model for Data Processing | Elementl
Dremel
Dremel is a scalable, interactive ad-hoc query system for analysis of read-only nested data. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. The system scales to thousands of CPUs and petabytes of data, and has thousands of users at Google.
https://ai.google/research/pubs/pub36632
Dremio - The missing link in data lakes
The Intelligent Lakehouse Platform for Agentic Al. From the leaders of Apache Polaris, Arrow, and Iceberg.
Dremio is the only lakehouse that meets the needs of AI agents (and humans) – providing autonomous optimization, a unified semantic layer, Zero-ETL federation and agent flexibility via MCP. Built on our proven semantic layer technology, now optimized for AI agents.
- Metadata Catalog - Apache Polaris
- In-Memory / Transport Format - Apache Arrow
- Table Format - Apache Iceberg
Intelligent Lakehouse Platform for Unified Data Access | Dremio
Talend
- Talend | A Complete, Scalable Data Management Solution | Talend
- Talend Full Course - Learn Talend in 6 Hours | Talend Tutorial For Beginners | Edureka - YouTube
- Talend Data Quality: Trusted Data for the Insights You Need | Talend
- Collibra vs Talend: Similarities, Differences, FAQ
Data on EKS
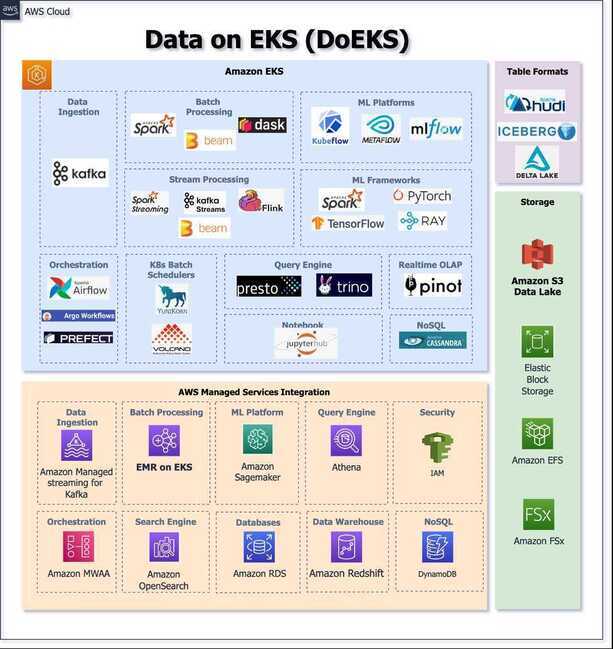
- Hello from Data on EKS | Data on EKS
- GitHub - awslabs/data-on-eks: DoEKS is a tool to build, deploy and scale Data & ML Platforms on Amazon EKS ⭐ 849
- Introducing Data on EKS – Modernize Data Workloads on Amazon EKS | Containers
Data Ingestion
DLT (Data Load Tool)
Features
- Automatic Schema: Data structure inspection and schema creation for the destination.
- Data Normalization: Consistent and verified data before loading.
- Seamless Integration: Colab, AWS Lambda, Airflow, and local environments.
- Scalable: Adapts to growing data needs in production.
- Easy Maintenance: Clear data pipeline structure for updates.
- Rapid Exploration: Quickly explore and gain insights from new data sources.
- Versatile Usage: Suitable for ad-hoc exploration to advanced loading infrastructures.
- Start in Seconds with CLI: Powerful CLI for managing, deploying and inspecting local pipelines.
- Incremental Loading: Load only new or changed data and avoid loading old records again.
- Open Source: Free and Apache 2.0 Licensed.
Data Engineering with Python and AI/LLMs – Data Loading Tutorial - YouTube
Others
SAAS
- Atlan (Enterprise Data Catalogs for DataOps)
- The Leading Third-Gen Data Catalog
- Active Metadata Management with Atlan | Quick Demo - YouTube
- Databricks
- Snowflake
- Informatica