Others
Quantile
Each of any set of values of a variate which divide a frequency distribution into equal groups, each containing the same fraction of the total population. In statistics and probability quantiles are cut points dividing the range of a probability distribution into contiguous intervals with equal probabilities, or dividing the observations in a sample in the same way. There is one less quantile than the number of groups created. Thus quartiles are the three cut points that will divide a dataset into four equal-sized groups. Common quantiles have special names: for instance quartile, decile (creating 10 groups: see below for more). The groups created are termed halves, thirds, quarters, etc., though sometimes the terms for the quantile are used for the groups created, rather than for the cut points.
Decile
- each of ten equal groups into which a population can be divided according to the distribution of values of a particular variable.
- each of the nine values of the random variable which divide a population into ten deciles.
Law of Large Numbers (LLN)
In probability theory, thelaw of large numbers(LLN) is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value, and will tend to become closer as more trials are performed, if the observations are independent and identically distributed Few exceptions to the law of large numbers
- The first is if the sample observatoins are not independent or identically distributed
- The other is for distributions with fat tails (higher chance of extreme outcomes)
The Weak Law of Large Numbers
Even when observations are not independent or identically distributed, the sample average will approach the population average, albeit slower and only if the variance is finite
Kullback-Leibler Divergence (KL Divergence)
In mathematical statistics, theKullback--Leibler divergence(also calledrelative entropy) is a measure of how one probability distribution diverges from a second, expected probability distribution.Applications include characterizing the relative(Shannon)entropy in information systems, randomness in continuous time-series, andinformation gain when comparing statistical models of inference. In contrast to variation of information, it is a distribution-wise asymmetricmeasure and thus does not qualify as a statistical metricof spread. In the simple case, a Kullback--Leibler divergence of 0 indicates that we can expect similar, if not the same, behavior of two different distributions, while a Kullback--Leibler divergence of 1 indicates that the two distributions behave in such a different manner that the expectation given the first distribution approaches zero. In simplified terms, it is a measure of surprise, with diverse applications such as applied statistics, fluid mechanics, neuroscience and machine learning.
Continuous probability distribution
A continuous probability distributionis a probability distribution that has a cumulative distribution function that is continuous. Most often they are generated by having a probability density function. Mathematicians call distributions with probability density functionsabsolutely continuous, since their cumulative distribution function is absolutely continuous with respect to the Lebesgue measureλ. If the distribution of X is continuous, then X is called acontinuous random variable. There are many examples of continuous probability distributions:normal, uniform, chi-squared, and others.
Entropy
"The entropy of a random variable is a function which attempts to characterize the unpredictability of a random variable." (Entropy and Mutual Information)" It is used for the construction of an automatic decision tree at each step of tree building; feature selection is done such using entropy criteria. Model selection is based on the principle of the maximum entropy, which states from the conflicting models, the one with the highest entropy is the best.
"If a random variable X takes on values in a set χ={x1, x2,..., xn}, and is defined by a probability distribution P(X), then we will write the entropy of the random variable as," (Entropy and Mutual Information)

"If the log in the above equation is taken to be to the base 2, then the entropy is expressed in bits. If the log is taken to be the natural log, then the entropy is expressed in nats. More commonly, entropy is expressed in bits."
Softmax Function
Softmax turns arbitrary real values into probabilities
In mathematics, the softmax function, also known as softargmax or normalized exponential function, is a function that takes as input a vector of K real numbers, and normalizes it into a probability distribution consisting of K probabilities proportional to the exponentials of the input numbers. That is, prior to applying softmax, some vector components could be negative, or greater than one; and might not sum to 1; but after applying softmax, each component will be in the interval(0, 1), and the components will add up to 1, so that they can be interpreted as probabilities. Furthermore, the larger input components will correspond to larger probabilities. Softmax is often used in neural networks, to map the non-normalized output of a network to a probability distribution over predicted output classes.
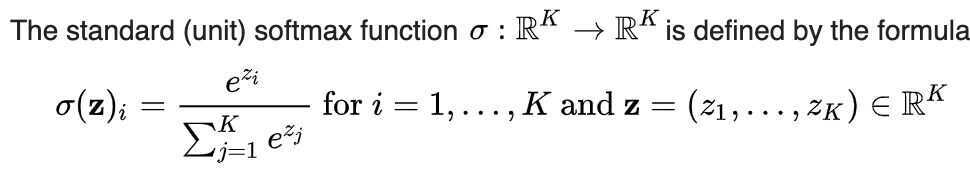
https://en.wikipedia.org/wiki/Softmax_function
Probabilistic Tools
- Probit/Logit: A probit/logit measures the likelihood or probability of an event happening, based upon observable variables
- Example: Measuring the probability that a company will be acquired, given variables that you believe are correlated
- Decision Trees: When you have a series of discrete events that are sequential, a decision tree allows you to compute the likelihood of events happening, condidtional on events leading up to it
- Example: The process by which an FDA drug works its way through the drug approval pipeline, from research to commercial development
- Monte Carlo Simulations: When you have multiple inputs that determine an output variable, a simulation allows you specify probabilistic distributions for each input variable and get a distribution for the output variable
- Example: Valuing a company, given its cash flows, growth and risk characteristics


