Overview of Prometheus Monitoring
A CNCF (Cloud Native Computing Foundation) project, is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true.
Features
- amulti-dimensionaldata model (timeseries defined by metric name and set of key/value dimensions)
- PromQL, aflexible query languageto leverage this dimensionality
- no dependency on distributed storage;single server nodes are autonomous
- timeseries collection happens via apull modelover HTTP
- pushing timeseriesis supported via an intermediary gateway
- targets are discovered viaservice discoveryorstatic configuration
- multiple modes ofgraphing and dashboarding support
- support for hierarchical and horizontalfederation
Components
- the main Prometheus server ⭐ 64k which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway ⭐ 3.3k for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager ⭐ 8.5k to handle alerts
- various support tools
Architecture Overview
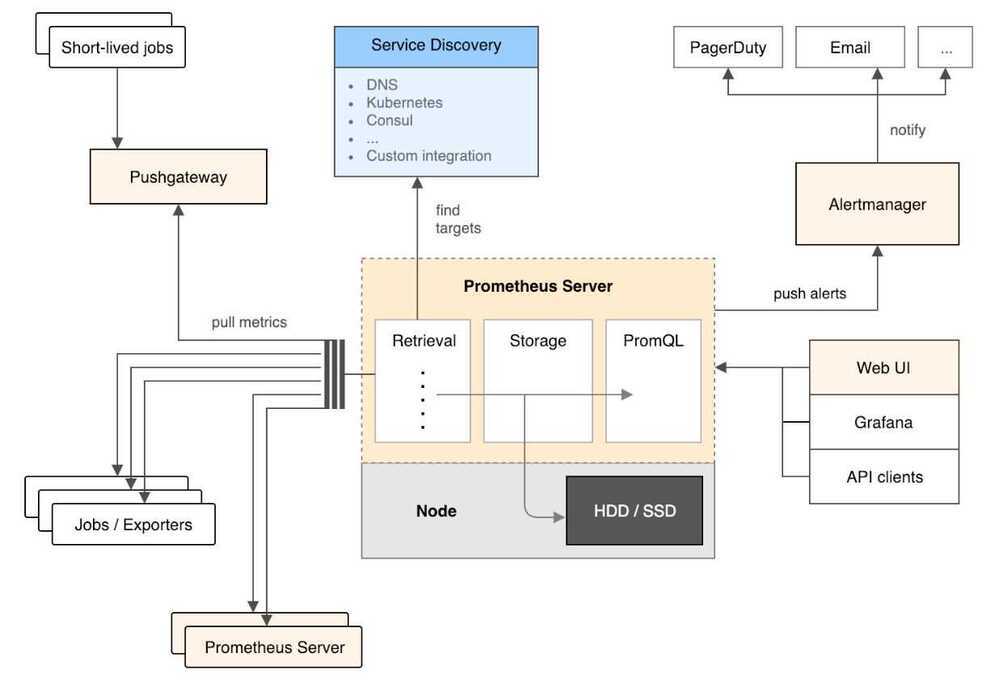
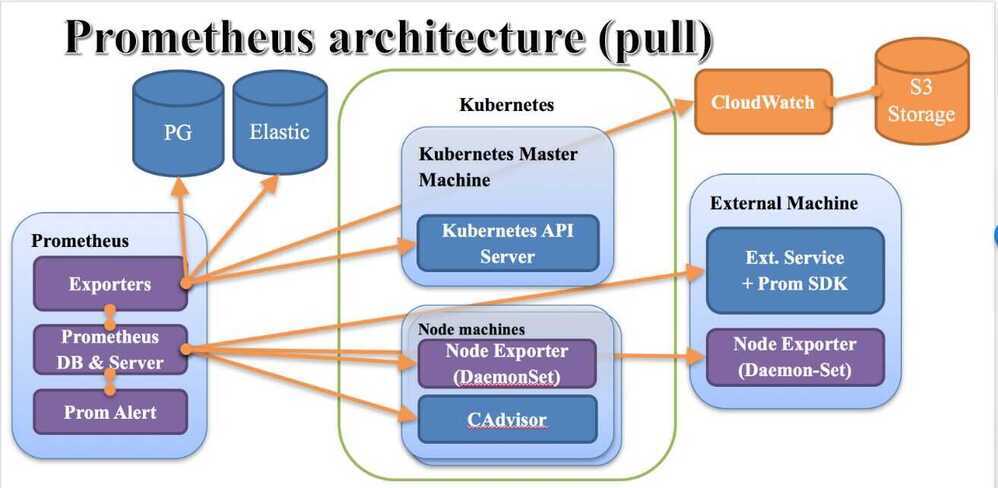
Concepts
- Data model
- Metric types
- Jobs and instances
Dashboards
- http://localhost:9090/metrics # for seeing all metrics that are currently scraped
- http://localhost:9090/graph # for visualizing graphs for the metrics
- Introduction to Kubernetes Monitoring | Grafana Cloud documentation
Metrics
-
Node metrics (related to physical or virtual machines)
- CPU, RAM, disk usage on the whole node
- Total number of processes running, and their states
- Number of open files, sockets, and their states
- I/O activity (disk, network), per operation or volume
- Physical/hardware (when applicable): temperature, fan speed ...
-
Container metrics (resource usage per container)
- Similar to node metrics, but not totally identical
- RAM breakdown will be different
- active vs inactive memory
- some memory issharedbetween containers, and accounted specially
- I/O activity is also harder to track
- async writes can cause deferred "charges"
- some page-ins are also shared between containers
http://jpetazzo.github.io/2013/10/08/docker-containers-metrics
-
Application Metrics
- Arbitrary metrics related to your application and business
- System performance: request latency, error rate ...
- Volume information: number of rows in database, message queue size ...
- Business data: inventory, items sold, revenue ...
-
Databases, message queues, load balancers, ...
-
Instrumentation (=deluxeprintffor our code)
-
Business metrics (customers served, revenue, ...)
Scraping config
additionalScrapeConfigs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: **metrics_path**
regex: (.+)
- source_labels: [**address**, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::d+)?;(d+)
replacement: $1:$2
target_label: **address**
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
Tools
- M3DB
Distributed TSDB, Aggregator and Query Engine, Prometheus Sidecar, Metrics Platform
The fully open source metrics platform built on M3DB, a distributed timeseries database
- PushGateway
The Prometheus Pushgateway exists to allow ephemeral and batch jobs to expose their metrics to Prometheus. Since these kinds of jobs may not exist long enough to be scraped, they can instead push their metrics to a Pushgateway. The Pushgateway then exposes these metrics to Prometheus.
https://github.com/prometheus/pushgateway
Deployment
helm-charts/charts/kube-prometheus-stack at main · prometheus-community/helm-charts · GitHub ⭐ 6.1k
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm show values prometheus-community/kube-prometheus-stack
helm install -f values.yaml straw prometheus-community/kube-prometheus-stack -n promstack
# otherwise
helm install straw prometheus-community/kube-prometheus-stack -n promstack
kubectl --namespace promstack get pods -l "release=straw"
helm upgrade -f values.yaml straw prometheus-community/kube-prometheus-stack -n promstack
kubectl port-forward svc/straw-grafana 3000:80 -n promstack --address='0.0.0.0'
kubectl port-forward service/straw-kube-prometheus-stac-alertmanager 3000:8080 -n promstack --address='0.0.0.0'
username - admin
default - prom-operator
kubectl get secret grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
helm uninstall straw
Monitoring in the Kubernetes Era | Datadog
References
- https://github.com/prometheus/prometheus
- https://prometheus.io
- https://prometheus.io/docs/introduction/overview
- TSDB - https://fabxc.org/tsdb
- On Kubernetes - https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus
- https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
- VictoriaMetrics: Simple & Reliable Monitoring for Everyone