Essential Status Page Tools
Status pages
- blackbox exporter - Prometheus Blackbox Exporter: Guide & Tutorial | Squadcast
- statuspage.io
- Statuspage | Atlassian - Paid
- Uptime Kuma
- Status.io - Hosted Status Pages - Paid
- UptimeRobot: Free Website Monitoring Service - Free
- Get 50 monitors with 5-minute checks totally FREE.
- Better Stack: Spot, Resolve, and Prevent Downtime.
- 10 monitors & heartbeats
- E-mail alerts with 3 minute checks
- 1 status page
- 3 GB ingested logs per month retained for 3 days
- 10M ingested metrics data points retained for 30 days
- Connect with Slack
- https://instatus.com/
netdata
Netdata is high-fidelity infrastructure monitoring and troubleshooting.
Open-source, free, preconfigured, opinionated, and always real-time.
Netdata'sdistributed, real-time monitoring Agentcollects thousands of metrics from systems, hardware, containers, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices, and is perfectly safe to install on your systems mid-incident without any preparation.
You can install Netdata on most Linux distributions (Ubuntu, Debian, CentOS, and more), container platforms (Kubernetes clusters, Docker), and many other operating systems (FreeBSD, macOS). Nosudorequired.
Netdata is designed by system administrators, DevOps engineers, and developers to collect everything, help you visualize metrics, troubleshoot complex performance problems, and make data interoperable with the rest of your monitoring stack.
https://github.com/netdata/netdata
https://my-netdata.io/infographic.html
Kube-state-metrics
kube-state-metrics is a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects. (See examples in the Metrics section below.) It is not focused on the health of the individual Kubernetes components, but rather on the health of the various objects inside, such as deployments, nodes and pods.
kube-state-metrics is about generating metrics from Kubernetes API objects without modification. This ensures that features provided by kube-state-metrics have the same grade of stability as the Kubernetes API objects themselves. In turn, this means that kube-state-metrics in certain situations may not show the exact same values as kubectl, as kubectl applies certain heuristics to display comprehensible messages. kube-state-metrics exposes raw data unmodified from the Kubernetes API, this way users have all the data they require and perform heuristics as they see fit.
The metrics are exported on the HTTP endpoint/metricson the listening port (default 80). They are served as plaintext. They are designed to be consumed either by Prometheus itself or by a scraper that is compatible with scraping a Prometheus client endpoint. You can also open/metricsin a browser to see the raw metrics.
https://github.com/kubernetes/kube-state-metrics
cAdvisor (Container Advisor)
Analyzes resource usage and performance characteristics of running containers.
cAdvisor (Container Advisor) provides container users an understanding of the resource usage and performance characteristics of their running containers. It is a running daemon that collects, aggregates, processes, and exports information about running containers. Specifically, for each container it keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage and network statistics. This data is exported by container and machine-wide.
cAdvisor has native support for Docker ⭐ 72k containers and should support just about any other container type out of the box. We strive for support across the board so feel free to open an issue if that is not the case. cAdvisor's container abstraction is based on lmctfy ⭐ 3.4k's so containers are inherently nested hierarchically.
- cAdvisor is embedded into the kubelet, so we scrape the kubelet to get container metrics
- These are the so-called Kubernetes "core" metrics
- For each container on the node:
- CPU Usage (user and system) and time throttled
- Filesystem read/writes/limits
- Memory usage and limits
- Network transmit/receive/dropped
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
networks:
- monitoring
restart: always
Zabbix
Zabbix is an open source monitoring software tool for diverse IT components, including networks, servers, virtual machines (VMs) and cloud services. Zabbix provides monitoring metrics, among others network utilization, CPU load and disk space consumption. Zabbix monitoring configuration can be done using XML based templates which contains elements to monitor. The software monitors operations on Linux, Hewlett Packard Unix (HP-UX), Mac OS X, Solaris and other operating systems (OSes); however, Windows monitoring is only possible through agents. Zabbix can use MySQL, MariaDB, PostgreSQL, SQLite, Oracle or IBM DB2 to store data. Its backend is written in C and the web frontend is written in PHP.
Zabbix offers several monitoring options:
- Simple checks can verify the availability and responsiveness of standard services such as SMTP or HTTP without installing any software on the monitored host.
- A Zabbix agent can also be installed on UNIX and Windows hosts to monitor statistics such as CPU load, network utilization, disk space, etc.
- As an alternative to installing an agent on hosts, Zabbix includes support for monitoring via SNMP, TCP and ICMP checks, as well as over IPMI, JMX, SSH, Telnet and using custom parameters. Zabbix supports a variety of near-real-time notification mechanisms, including XMPP.
https://en.wikipedia.org/wiki/Zabbix
Creating custom dashboards
Creating and customizing dashboards in Zabbix
Nagios
Nagios /ˈnɑːɡiːoʊs/, now known as Nagios Core, is a free and open sourcecomputer-software application that monitors systems, networks and infrastructure. Nagios offers monitoring and alerting services for servers, switches, applications and services. It alerts users when things go wrong and alerts them a second time when the problem has been resolved
Features
- Monitoring of network services (SMTP, POP3, HTTP, NNTP, ICMP, SNMP, FTP, SSH)
- Monitoring of host resources (processor load, disk usage, system logs) on a majority of network operating systems, including Microsoft Windows, using monitoring agents.
- Monitoring of any hardware (like probes for temperature, alarms, etc.) which have the ability to send collected data via a network to specifically written plugins
- Monitoring via remotely run scripts via Nagios Remote Plugin Executor
- Remote monitoring supported through SSH or SSLencrypted tunnels.
- A simple plugin design that allows users to easily develop their own service checks depending on needs, by using their tools of choice (shell scripts, C++, Perl, Ruby, Python, PHP, C#, etc.)
- Available data graphing plugins
- Parallelized service checks
- Flat-text formatted configuration files (integrates with many config editors)
- The ability to define network host using 'parent' hosts, allowing the detection of and distinction between hosts that are down or unreachable
- Contact notifications when service or host problems occur and get resolved (via e-mail, pager, SMS, or any user-defined method through plugin system)
- The ability to define event handlers to be run during service or host events for proactive problem resolution
- Automatic log file rotation
- Support for implementing redundant monitoring hosts
- Support for implementing performance data graphing
- Support for database backend (such as NDOUtils)
- A web-interface for viewing current network status, notifications, problem history, log files, etc.
https://en.wikipedia.org/wiki/Nagios
Monit
Monit is a small Open Source utility for managing and monitoring Unix systems. Monit conducts automatic maintenance and repair and can execute meaningful causal actions in error situations.
Mmonit
M/Monit can monitor and manage distributed computer systems, conduct automatic maintenance and repair and execute meaningful causal actions in error situations.
Sentry
Sentry fundamentally is a service that helps you monitor and fix crashes in realtime. The server is in Python, but it contains a full API for sending events from any language, in any application.
settings.py
settings.py
example_SENTRY_PROJECT_ID=11
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
if not DEBUG:
sentry_sdk.init(
dsn="https://5495d5289c414d00b217c2ff52e914d7@sentry.example.com/" + str(
os.environ ['example_SENTRY_PROJECT_ID']),
integrations=[DjangoIntegration()],
attach_stacktrace=True,
debug=True, )
Commands
sentry
sentry upgrade
sentry cleanup
sentry cleanup --days 7
psql -h localhost -p 5432 -U postgres
1RtBZRNxG7
VACUUM FULL;
sentry run cron
Links
- https://github.com/getsentry/sentry/blob/master/src/sentry/conf/server.py
- https://github.com/getsentry/sentry
- https://sentry.io/welcome
- https://blog.hlab.tech/a-step-by-step-tutorial-on-how-to-monitor-software-errors-in-real-time-using-sentry-in-django-web-applications
- https://getsentry.github.io/sentry-python/api.html
- https://docs.sentry.io/platforms/python
- Android - https://sentry.io/for/android
- https://docs.sentry.io/platforms/javascript/guides/react
- https://docs.sentry.io/platforms/android
Others - RunWhen Home - Help every engineer troubleshoot any part of your tech stack
- We combine a community writing troubleshooting scripts for apps, platform and infrastructure in the Kubernetes ecosystem with Digital Assistants to help any engineer find which to run, and when.
NewRelic
newrelic-admin generate-config <license_key> newrelic.ini
newrelic-admin validate-config newrelic.ini
import newrelic.agent
newrelic.agent.initialize('/path/to/newrelic.ini')
newrelic-admin generate-config $YOUR_LICENSE_KEY newrelic.ini
NEW_RELIC_CONFIG_FILE=newrelic.ini newrelic-admin run-program gunicorn app:app -b 0.0.0.0:5000 --workers 2 -k gevent --timeout 300 --worker-connections 1000 --max-requests 1000000 --limit-request-line 8190 --access-logfile '-'
if debug:
newrelic.agent.initialize('newrelic.ini', 'development')
else:
newrelic.agent.initialize('newrelic.ini', 'production')
Query Builder in NewRelic One along with Data Explorer
SELECT count(*) FROM Transaction FACET httpResponseCode, request.uri WHERE appName= 'lms-prod' SINCE 30 MINUTES AGO TIMESERIES
SELECT count(*) FROM Transaction FACET httpResponseCode, request.uri WHERE httpResponseCode LIKE '5%' AND appName= 'lms-prod' SINCE 1 week ago TIMESERIES
SELECT count(*) FROM Transaction FACET appName, httpResponseCode, request.uri WHERE httpResponseCode != 200 SINCE 30 MINUTES AGO LIMIT MAX
SELECT count(*) FROM Transaction WHERE httpResponseCode LIKE '5%' SINCE 1 week ago FACET appName
SELECT count(*) FROM Transaction FACET appName, httpResponseCode, request.uri WHERE httpResponseCode LIKE '5%' SINCE 30 MINUTES AGO LIMIT MAX
https://pypi.org/project/newrelic
Send error logs (record exception) - https://docs.newrelic.com/docs/agents/python-agent/python-agent-api/record_exception
https://discuss.newrelic.com/c/customer-on-boarding/proven-practices-best-practices-guide
Data Tables
- A screenshot of a table in New Relic where you were particularly frustrated by how it displays your data.
- A screenshot of a table in New Relic where you felt it was missing information that would make it easier for you to complete a task that you're trying to do.
- A screenshot of a table in New Relic where you felt that this table is really is really well set up for your needs.
- A screenshot of a data table from somewhere else, that you think New Relic could learn from something that they are doing differently
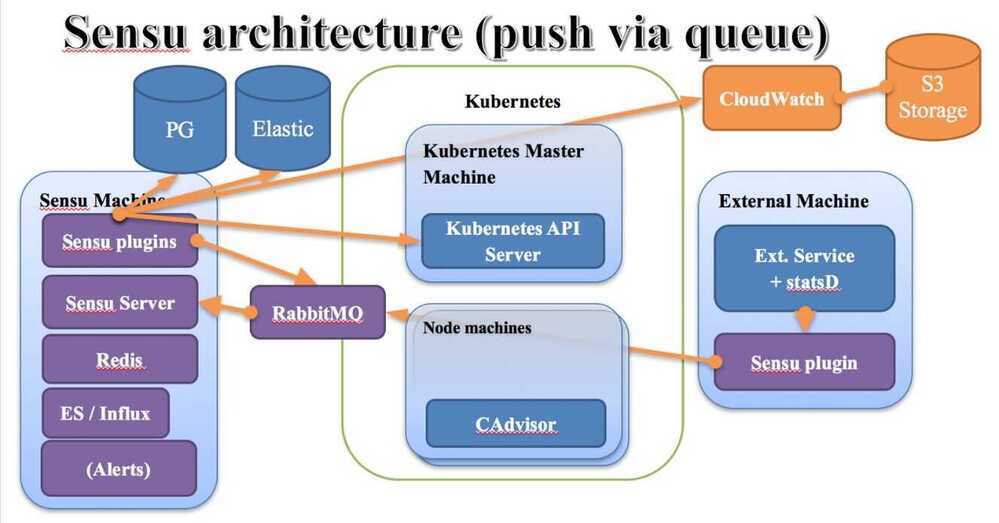
Sensu
syslog
https://docs.docker.com/config/containers/logging/syslog
syslog-ng
- GitHub - syslog-ng/syslog-ng: syslog-ng is an enhanced log daemon, supporting a wide range of input and output methods: syslog, unstructured text, queueing, SQL & NoSQL. ⭐ 2.3k
- syslog-ng - Log Management Solutions
DataDog
- Best Practices for Tagging Your Infrastructure and Applications | Datadog
- Monitoring Kubernetes With Datadog | Datadog
- Monitor Apache Airflow With Datadog | Datadog
- Datadog Monitoring | Datadog
- Airflow
- Monitoring in the Kubernetes Era | Datadog
- Introducing Husky, Datadog's third-generation event store | Datadog
Opentelemetry
- OpenTelemetry
- OpenTelemetry - CNCF · GitHub
- Demo Docs - Hackathon
- OpenTelemetry Demo Docs | OpenTelemetry
- Demo Architecture | OpenTelemetry
- GitHub - open-telemetry/opentelemetry-demo: This repository contains the OpenTelemetry Astronomy Shop, a microservice-based distributed system intended to illustrate the implementation of OpenTelemetry in a near real-world environment. ⭐ 3.1k
signoz
- Metrics
- Traces
- Logs
- Dashboards
- Errors
- Alerts
OpenTelementry APM Python - Python OpenTelemetry Instrumentation | SigNoz
Storage (Clickhouse)
SigNoz stores both metrics and logs, along with traces, under a single pane of glass. It's designed to be a comprehensive observability platform, consolidating these three crucial telemetry data types for easy analysis and monitoring.
- Logs: SigNoz uses Clickhouse, a high-performance columnar database, to store and manage logs at scale. This allows for efficient querying, filtering, and analysis of log data.
- Metrics: SigNoz also supports metrics data, allowing users to track key performance indicators (KPIs) and system health.
- Traces - SigNoz integrates distributed tracing, enabling users to understand the flow of requests across different services and pinpoint performance bottlenecks.
Others
- https://victoriametrics.com/products/open-source
- Airbrake
- Home - ThoughtData
- No-code Enterprise Data Quality Monitoring Tool: Lightup
- Kloudfuse
- AI-ENABLED UNIFIED OBSERVABILITY, Designed for 10X More Data At 1/10th of the Cost
- GitHub - vectordotdev/vector: A high-performance observability data pipeline. ⭐ 22k (19.5K stars)
- Vector is a high-performance, end-to-end (agent & aggregator) observability data pipeline that puts you in control of your observability data. Collect, transform, and route all your logs and metrics to any vendors you want today and any other vendors you may want tomorrow. Vector enables dramatic cost reduction, novel data enrichment, and data security where you need it, not where it is most convenient for your vendors. Additionally, it is open source and up to 10x faster than every alternative in the space.
- Vector | A lightweight, ultra-fast tool for building observability pipelines
- ClickHouse Docs
- ClickStack is an open source, production-grade observability platform built on ClickHouse and OpenTelemetry (OTel) that unifies logs, traces, metrics, and sessions in a single high-performance solution. It enables developers and SREs to monitor and debug complex systems end-to-end without switching tools or manually correlating data.