Redis Concepts
Redis keys
Redis keys are binary safe, this means that you can use any binary sequence as a key, from a string like "foo" to the content of a JPEG file. The empty string is also a valid key. A few other rules about keys:
- Very long keys are not a good idea. For instance a key of 1024 bytes is a bad idea not only memory-wise, but also because the lookup of the key in the dataset may require several costly key-comparisons. Even when the task at hand is to match the existence of a large value, hashing it (for example with SHA1) is a better idea, especially from the perspective of memory and bandwidth.
- Very short keys are often not a good idea. There is little point in writing "u1000flw" as a key if you can instead write "user:1000:followers". The latter is more readable and the added space is minor compared to the space used by the key object itself and the value object. While short keys will obviously consume a bit less memory, your job is to find the right balance.
- Try to stick with a schema. For instance "object-type:id" is a good idea, as in "user:1000". Dots or dashes are often used for multi-word fields, as in "comment:1234:reply.to" or "comment:1234:reply-to".
- The maximum allowed key size is 512 MB.
Redis Strings
Values can be strings (including binary data) of every kind, for instance you can store a jpeg image inside a value. A value can't be bigger than 512 MB. Note that SET will replace any existing value already stored into the key, in the case that the key already exists, even if the key is associated with a non-string value. So SET performs an assignment. The SET command has interesting options, that are provided as additional arguments. For example, I may ask SET to fail if the key already exists, or the opposite, that it only succeed if the key already exists:
> set mykey newval nx
(nil)
> set mykey newval xx
OK
Even if strings are the basic values of Redis, there are interesting operations you can perform with them. For instance, one is atomic increment:
> set counter 100
OK
> incr counter
(integer) 101
> incr counter
(integer) 102
> incrby counter 50
(integer) 152
The INCR command parses the string value as an integer, increments it by one, and finally sets the obtained value as the new value. There are other similar commands like INCRBY, DECR and DECRBY. Internally it's always the same command, acting in a slightly different way. What does it mean that INCR is atomic? That even multiple clients issuing INCR against the same key will never enter into a race condition. For instance, it will never happen that client 1 reads "10", client 2 reads "10" at the same time, both increment to 11, and set the new value to 11. The final value will always be 12 and the read-increment-set operation is performed while all the other clients are not executing a command at the same time. There are a number of commands for operating on strings. For example the GETSET command sets a key to a new value, returning the old value as the result. You can use this command, for example, if you have a system that increments a Redis key using INCR every time your web site receives a new visitor. You may want to collect this information once every hour, without losing a single increment. You can GETSET the key, assigning it the new value of "0" and reading the old value back.
The ability to set or retrieve the value of multiple keys in a single command is also useful for reduced latency. For this reason there are the MSET and MGET commands:
> mset a 10 b 20 c 30
OK
> mget a b c
1) "10"
2) "20"
3) "30"
When MGET is used, Redis returns an array of values.
Redis Expires
- They can be set both using seconds or milliseconds precision.
- However the expire time resolution is always 1 millisecond.
- Information about expires are replicated and persisted on disk, the time virtually passes when your Redis server remains stopped (this means that Redis saves the date at which a key will expire).
How Redis expires keys
Redis keys are expired in two ways: a passive way, and an active way. A key is passively expired simply when some client tries to access it, and the key is found to be timed out. Of course this is not enough as there are expired keys that will never be accessed again. These keys should be expired anyway, so periodically Redis tests a few keys at random among keys with an expire set. All the keys that are already expired are deleted from the keyspace. Specifically this is what Redis does 10 times per second:
-
Test 20 random keys from the set of keys with an associated expire.
-
Delete all the keys found expired.
-
If more than 25% of keys were expired, start again from step 1. This is a trivial probabilistic algorithm, basically the assumption is that our sample is representative of the whole key space, and we continue to expire until the percentage of keys that are likely to be expired is under 25% This means that at any given moment the maximum amount of keys already expired that are using memory is at max equal to max amount of write operations per second divided by 4.
https://redis.io/commands/expire#how-redis-expires-keys
https://redis.io/topics/data-types-intro
Scan
Time complexity:O(1) for every call. O(N) for a complete iteration, including enough command calls for the cursor to return back to 0. N is the number of elements inside the collection
The SCAN command and the closely related commands SSCAN, HSCAN and ZSCAN are used in order to incrementally iterate over a collection of elements.
- SCAN iterates the set of keys in the currently selected Redis database.
- SSCAN iterates elements of Sets types.
- HSCAN iterates fields of Hash types and their associated values.
- ZSCAN iterates elements of Sorted Set types and their associated scores.
These commands allow for incremental iteration, returning only a small number of elements per call, they can be used in production without the downside of commands likeKEYSorSMEMBERSthat may block the server for a long time (even several seconds) when called against big collections of keys or elements.
SCAN is a cursor based iterator. This means that at every call of the command, the server returns an updated cursor that the user needs to use as the cursor argument in the next call.
An iteration starts when the cursor is set to 0, and terminates when the cursor returned by the server is 0.
Starting an iteration with a cursor value of 0, and calling SCAN until the returned cursor is 0 again is called afull iteration.
> sscan myset 0 match f*
> redis-cli -a a6ad92769ef04b711eea18dccfff85ea --no-auth-warning --scan | while read LINE ; do TTL=`redis-cli --no-auth-warning -a a6ad92769ef04b711eea18dccfff85ea ttl "$LINE"`; if [ $TTL -eq -1 ]; then echo "$LINE"; fi; done;
https://redis.io/commands/scan
Persistence
- RDB (Redis Database): RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
- AOF (Append Only File): AOF persistence logs every write operation received by the server. These operations can then be replayed again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself.
- No persistence: You can disable persistence completely. This is sometimes used when caching.
- RDB + AOF: You can also combine both AOF and RDB in the same instance. Notice that, in this case, when Redis restarts the AOF file will be used to reconstruct the original dataset since it is guaranteed to be the most complete.
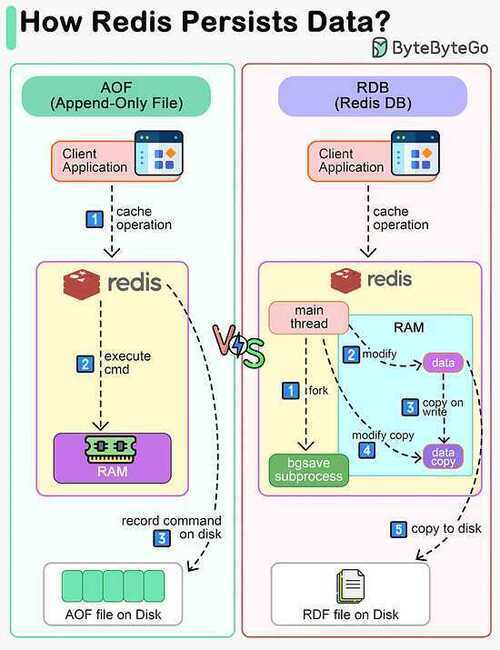
AOF - Append Only File
It's the change-log style persistent format.
AOF is actually a persistence technique in which an RDB file is generated once and all the data is appended to it as it comes
RDB - Redis Database Backup
It's the snapshot style persistence format.
RDB file is a dump of all user data stored in an internal, compressed serialization format at a particular timestamp which is used for point-in-time recovery (recovery from a timestamp).
# take backup locally
redis-cli --rdb /tmp/dump.rdb
Compress AOF
BGREWRITEAOF
https://redis.io/commands/bgrewriteaof
https://stackoverflow.com/questions/39953542/aof-and-rdb-backups-in-redis
https://redis.io/topics/persistence
The complete Redis backups guide (with examples)
Redis Keyspace Notifications
Keyspace notifications allow clients to subscribe to Pub/Sub channels in order to receive events affecting the Redis data set in some way. Examples of events that can be received are:
- All the commands affecting a given key.
- All the keys receiving an LPUSH operation.
- All the keys expiring in the database 0.
Events are delivered using the normal Pub/Sub layer of Redis, so clients implementing Pub/Sub are able to use this feature without modifications.
Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.
In the future there are plans to allow for more reliable delivering of events, but probably this will be addressed at a more general level either bringing reliability to Pub/Sub itself, or allowing Lua scripts to intercept Pub/Sub messages to perform operations like pushing the events into a list.