Introduction to Apache Flink
Apache Flink is a stream processing framework that can also handle batch tasks. It considers batches to simply be data streams with finite boundaries, and thus treats batch processing as a subset of stream processing. This stream-first approach to all processing has a number of interesting side effects.
This stream-first approach has been called the Kappa architecture, in contrast to the more widely known Lambda architecture (where batching is used as the primary processing method with streams used to supplement and provide early but unrefined results). Kappa architecture, where streams are used for everything, simplifies the model and has only recently become possible as stream processing engines have grown more sophisticated.
The four cornerstones on which Flink is built
- Streaming
- State
- Time
- Snapshots
Real-time Stream Processors
Advanced stream processors allow you to perform a wide range of tasks including:
- Windowed aggregations (e.g., count pageviews per minute)
- Stream-to-table joins (e.g., enrich clickstream data with user profiles)
- Event filtering and deduplication
- Resilience to late or out-of-order data
Stream processing frameworks are purpose-built to manage state, ordering, and fault tolerance at scale.
Streaming
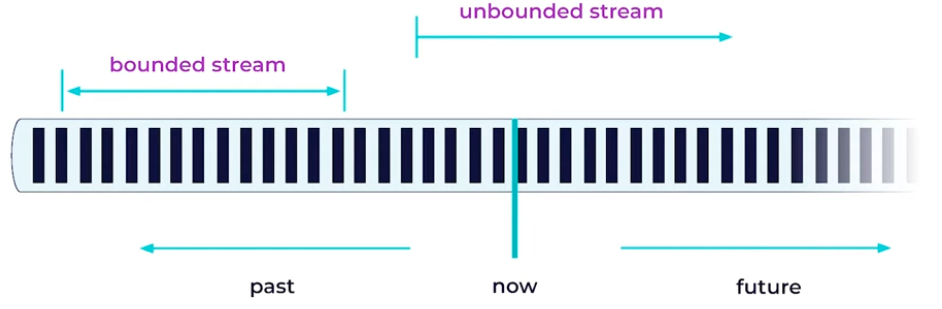
- A stream is a sequence of events
- Business data is always a stream: bounded or unbounded
- For Flink, batch processing is just a special case in the runtime
Use Cases of Apache Flink
Although built as a generic data processor, Flink’s native support of unbounded streams contributed to its popularity as a stream processor. Flink’s common use cases are very similar to Kafka’s use cases, although Flink and Kafka serve slightly different purposes. Kafka usually provides the event streaming while Flink is used to process data from that stream. Flink and Kafka are commonly used together for:
- Batch processing: Flink is good at processing bounded data sets, suitable for traditional batch processing tasks.
- Stream processing: Flink handles unbounded data streams for continuous, real-time processing.
- Event-driven applications: Flink’s event stream capabilities make it valuable for fraud detection, credit card systems, and process monitoring.
- Update stateful applications (savepoints): Flink’s stateful processing and savepoints ensure consistency during updates or failures.
- Streaming applications: Real-time data processing to complex event pattern detection.
- Data analytics (batch, streaming): Ideal for real-time and historical data analysis.
- Data pipelines/ETL: Flink is used in building pipelines for ETL processes.
Others
- A consequence of using the "group by" operation in Flink is: Messages will be repartitioned across the cluster.
Links
- 06-sliding-window-analytics
- Stream Processing | Apache Kafka 101 (2025 Edition) - YouTube
- Apache Flink 101 - YouTube
- Glossary | Apache Flink
- Getting Started | Apache Flink
- Apache Flink® SQL
- Apache Flink® SQL - YouTube
- https://dzone.com/articles/introduction-to-streaming-etl-with-apache-flink
- https://flink.apache.org/flink-architecture.html
- CDC Stream Processing with Apache Flink
- Apache Flink 1.19 - Deprecations, New Features, and Improvements
- Krones real-time production line monitoring with Amazon Managed Service for Apache Flink | AWS Big Data Blog
- Welcome to Amazon Managed Service for Apache Flink learning series | Amazon Web Services - YouTube
- Dynamic Tables | Apache Flink
- What is Apache Flink®?
- Apache Kafka Vs. Apache Flink
- Apache Flink - A Must-Have For Your Streams | Systems Design Interview 0...
- Apache Spark Vs. Apache Flink Vs. Apache Kafka Vs. Apache Storm! Data St...
- Stateless vs Stateful Stream Processing with Kafka Streams and Apache Flink
- Consume Apache Kafka Messages using Apache Flink and Java
- Apache Flink: What it is and how it works.
- Mastering Production Data Streaming Systems with Apache Kafka® - YouTube
- GitHub - confluentinc/quickstart-streaming-agents at gko ⭐ 83
- Lab1 - Price Matching Orders With MCP Tool Calling
- Lab2 - Vector Search & RAG
- Lab3 - Agentic Fleet Management Using Confluent Intelligence
- GitHub - confluentinc/online-retailer-flink-demo at gko-2026 ⭐ 23
- Flink SQL Autopilot in Confluent Cloud for Apache Flink | Confluent Documentation
- Using Apache Flink for Model Inference: A Guide for Real-Time AI Applications | Confluent
- Materialized Tables in Apache Flink
- How Smartsheet built Real-time Dynamic Filtering on Apache Flink reducing $40K/month in messaging costs | AWS Big Data Blog