Understanding Information Retrieval Techniques
Link Analysis and Web Search
Talks about "How Google Search indexes pages"
tf-idf (term frequency - inverse document frequency)
In information retrieval, tf-id for TFIDF, short for term frequency - inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling. The tf--idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general. Tf--idf is one of the most popular term-weighting schemes today; 83% of text-based recommender systems in digital libraries use tf-idf.
Variations of the tf-idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document's relevance given a user query. tf-idf can be successfully used for stop-words filtering in various subject fields, including text summarization and classification.
One of the simplest ranking functions is computed by summing the tf--idf for each query term; many more sophisticated ranking functions are variants of this simple model.
Term frequency
Suppose we have a set of English text documents and wish to rank which document is most relevant to the query, "the brown cow". A simple way to start out is by eliminating documents that do not contain all three words "the", "brown", and "cow", but this still leaves many documents. To further distinguish them, we might count the number of times each term occurs in each document; the number of times a term occurs in a document is called itsterm frequency. However, in the case where the length of documents varies greatly, adjustments are often made (see definition below). The first form of term weighting is due to Hans Peter Luhn(1957) which may be summarized as:
- The weight of a term that occurs in a document is simply proportional to the term frequency.
Inverse document frequency
Because the term "the" is so common, term frequency will tend to incorrectly emphasize documents which happen to use the word "the" more frequently, without giving enough weight to the more meaningful terms "brown" and "cow". The term "the" is not a good keyword to distinguish relevant and non-relevant documents and terms, unlike the less-common words "brown" and "cow". Hence aninverse document frequencyfactor is incorporated which diminishes the weight of terms that occur very frequently in the document set and increases the weight of terms that occur rarely.
Karen Spärck Jones(1972) conceived a statistical interpretation of term specificity called Inverse Document Frequency (idf), which became a cornerstone of term weighting:
- The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs.
Just the idea that you can enter in a query and then you could turn that query into a vector and then you have all of your documents also modeled as vectors and then you have a mathematical relationship that you can define between your search query and each of those documents. You can model them in space and then find how the query differs from all of those documents in space and then you have a ranking.
References
https://en.wikipedia.org/wiki/Tf%E2%80%93idf
Okapi BM25
In information retrieval, Okapi BM25(BM stands for Best Matching) is a ranking function used by search engines to rank matching documents according to their relevance to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones, and others.
The name of the actual ranking function is BM25. To set the right context, however, it is usually referred to as "Okapi BM25", since the Okapi information retrieval system, implemented at London's City University in the 1980s and 1990s, was the first system to implement this function.
BM25 and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval.

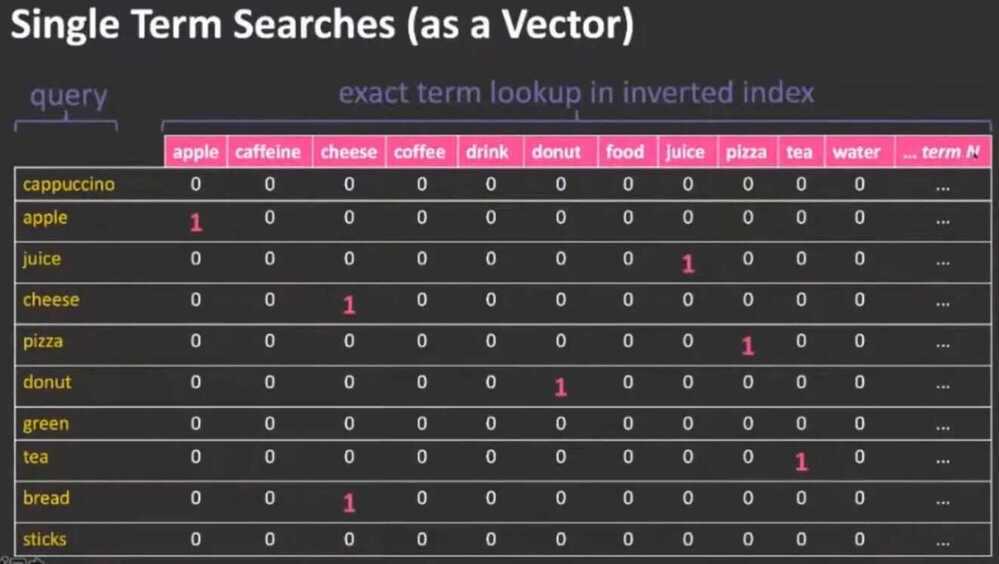
Knowledge graph, Keyword Search
- Inverted Index -> Term / Document
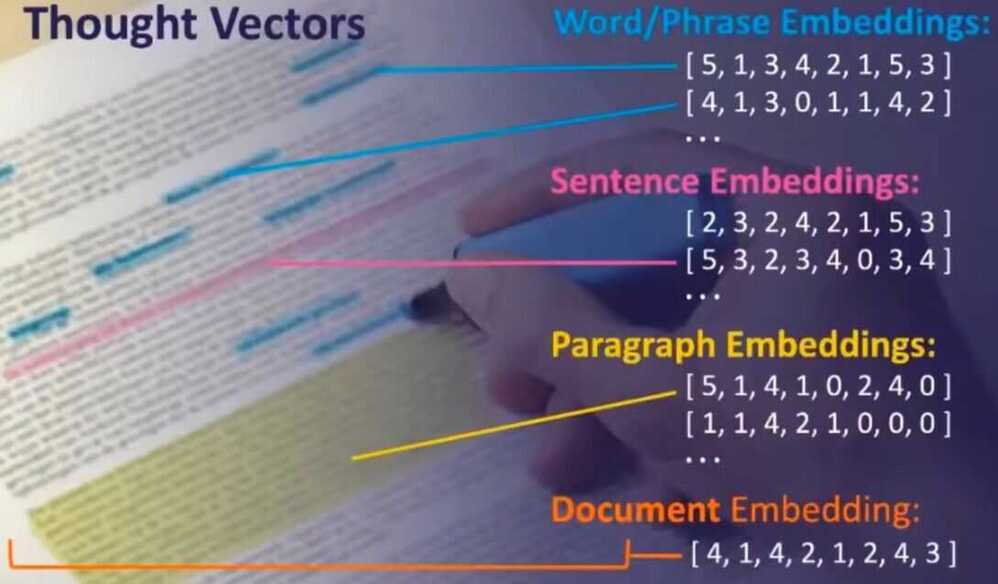
- Embeddings
- Word / Phrase embeddings
- Sentence embeddings
- Paragraph embeddings
- Document embeddings
- One hot encoding


- Dimensionality reduction
- Vector similarity scoring
Solr
- Streaming expressions
- Vectors fields/functions in solr



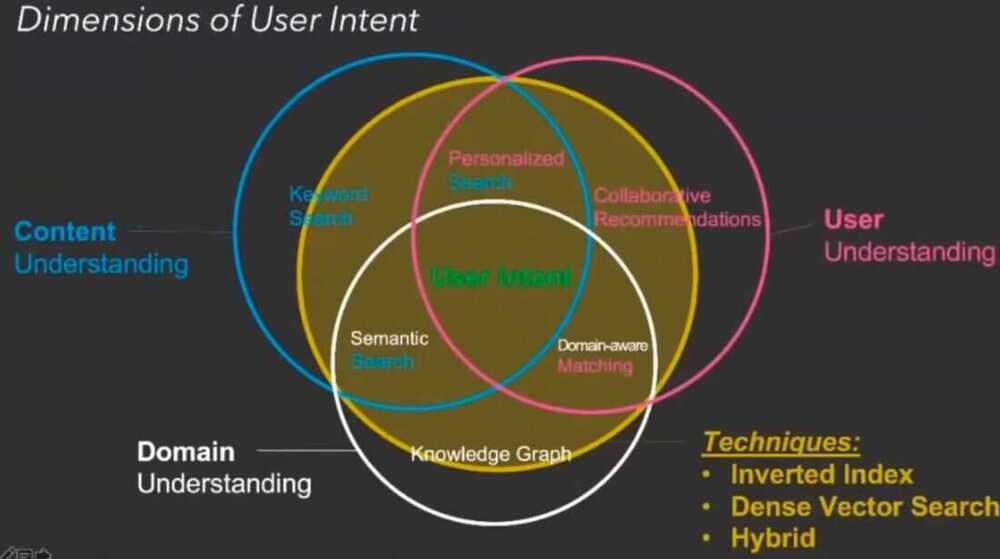

Thought Vectors, Knowledge Graphs, and Curious Death(?) of Keyword Search
Neural Search
The core idea of neural search is to leverage state-of-the-art deep neural networks to build every component of a search system. In short, neural search is deep neural network-powered information retrieval.In academia, it's often called neural IR.
What can it do?
Thanks to recent advances in deep neural networks, a neural search system can go way beyond simple text search. It enables advanced intelligence on all kinds of unstructured data, such as images, audio, video, PDF, 3D mesh, you name it.
For example, retrieving animation according to some beats; finding the best-fit memes according to some jokes; scanning a table with your iPhone's LiDAR camera and finding similar furniture at IKEA. Neural search systems enable what traditional search can't: multi/cross-modal data retrieval.
Think outside the (search)box
Many neural search-powered applications do not have a search box:
- A question-answering chatbot can be powered by neural search: by first indexing all hard-coded QA pairs and then semantically mapping user dialog to those pairs.
- A smart speaker can be powered by neural search: by applying STT (speech-to-text) and semantically mapping text to internal commands.
- A recommendation system can be powered by neural search: by embedding user-item information into vectors and finding top-K nearest neighbours of a user/item.
Neural search creates a new way to comprehend the world. It is creating new doors that lead to new businesses.
https://github.com/jina-ai/jina/blob/master/.github/2.0/neural-search