Optimizations
Delta Lake Files - S3 Effect
Save on storage costs with Databricks on AWS | Medium
The only way to delete files no longer needed for the table’s state is by running the VACUUM command on the table. The command takes a threshold (days), and only removes files beyond the threshold days so that the time-travel/restore is available for the threshold period. This is great and appears to have solved the problem of exponential file duplication, but there is one more caveat. Unless the S3 bucket backing the delta table is disabled for versioning, the previous delete operation only adds a Delete Marker to the files, and the actual version is still retained for X number of days for general purpose restoration. The X number of days is defined in the Lifecycle Policy of the S3 bucket.
Bottom line, if the delta tables are backed by a version enabled S3 Bucket with a very generous lifecycle policy, the storage cost will increase exponentially and mitigation efforts through VACUUM has very little effect. The bitter truth is, after a while, much of your S3 cost is towards the files that does not make up your table.
Best practices: Delta Lake
- Provide data location hints
- Compact files
- Replace the content or schema of a table
- Spark caching
- Differences between Delta Lake and Parquet on Apache Spark
- Improve performance for Delta Lake merge
- Manage data recency
- Enhanced checkpoints for low-latency queries
- Manage column-level statistics in checkpoints
- Enable enhanced checkpoints for Structured Streaming queries
Best practices: Delta Lake | Databricks on AWS
Databricks Runtime performance enhancements
- Disk caching accelerates repeated reads against Parquet data files by loading data to disk volumes attached to compute clusters.
- Dynamic file pruning improves query performance by skipping directories that do not contain data files that match query predicates.
- Low shuffle merge reduces the number of data files rewritten by
MERGEoperations and reduces the need to recalculateZORDERclusters. - Apache Spark 3.0 introduced adaptive query execution, which provides enhanced performance for many operations.
Databricks recommendations for enhanced performance
- You can clone tables on Databricks to make deep or shallow copies of source datasets.
- The cost-based optimizer accelerates query performance by leveraging table statistics.
- You can auto optimize Delta tables using optimized writes and automatic file compaction; this is especially useful for long-running Structured Streaming jobs.
- You can use Spark SQL to interact with semi-structured JSON data without parsing strings.
- Higher order functions provide built-in, optimized performance for many operations that do not have common Spark operators. Higher order functions provide a performance benefit over user defined functions.
- Databricks provides a number of built-in operators and special syntax for working with complex data types, including arrays, structs, and JSON strings.
- You can manually tune settings for joins that include ranges or contain data with substanial skew.
Opt-in behaviors
- Databricks provides a write serializable isolation guarantee by default; changing the isolation level to serializable can reduce throughput for concurrent operations, but might be necessary when read serializability is required.
- You can use bloom filter indexes to reduce the likelihood of scanning data files that don’t contain records matching a given condition.
Optimize your file size for fast file pruning
Two of the biggest time sinks in an Apache Spark query are the time spent reading data from cloud storage and the need to read all underlying files. With data skipping on Delta Lake, queries can selectively read only the Delta files containing relevant data, saving significant time. Data skipping can help with static file pruning, dynamic file pruning, static partition pruning and dynamic partition pruning.
One of the first things to consider when setting up data skipping is the ideal data file size - too small and you will have too many files (the well-known "small-file problem"); too large and you won’t be able to skip enough data.
A good file size range is 32-128MB (1024*1024*32 = 33554432 for 32MB of course). Again, the idea is that if the file size is too big, the dynamic file pruning will skip to the right file or files, but they will be so large it will still have a lot of work to do. By creating smaller files, you can benefit from file pruning and minimize the I/O retrieving the data you need to join.
You can set the file size value for the entire notebook in Python:
spark.conf.set("spark.databricks.delta.targetFileSize", 33554432)
Or in SQL:
SET spark.databricks.delta.targetFileSize=33554432
Or you can set it only for a specific table using:
ALTER TABLE (database).(table) SET TBLPROPERTIES (delta.targetFileSize=33554432)
If you happen to be reading this article after you have already created tables, you can still set the table property for the file size and, when optimizing and creating the ZORDER, the files will be proportioned to the new file size. If you have already added a ZORDER, you can add and/or remove a column to force a re-write before arriving at the final ZORDER configuration.
As Databricks continues to add features and capabilities, we can also Auto Tune the file size based on the table size. For smaller databases, the above setting will likely provide better performance but for larger tables and/or just to make it simpler, you can follow the guidance here and implement the delta.tuneFileSizesForRewrites table property.
Create a Z-Order on your fact tables
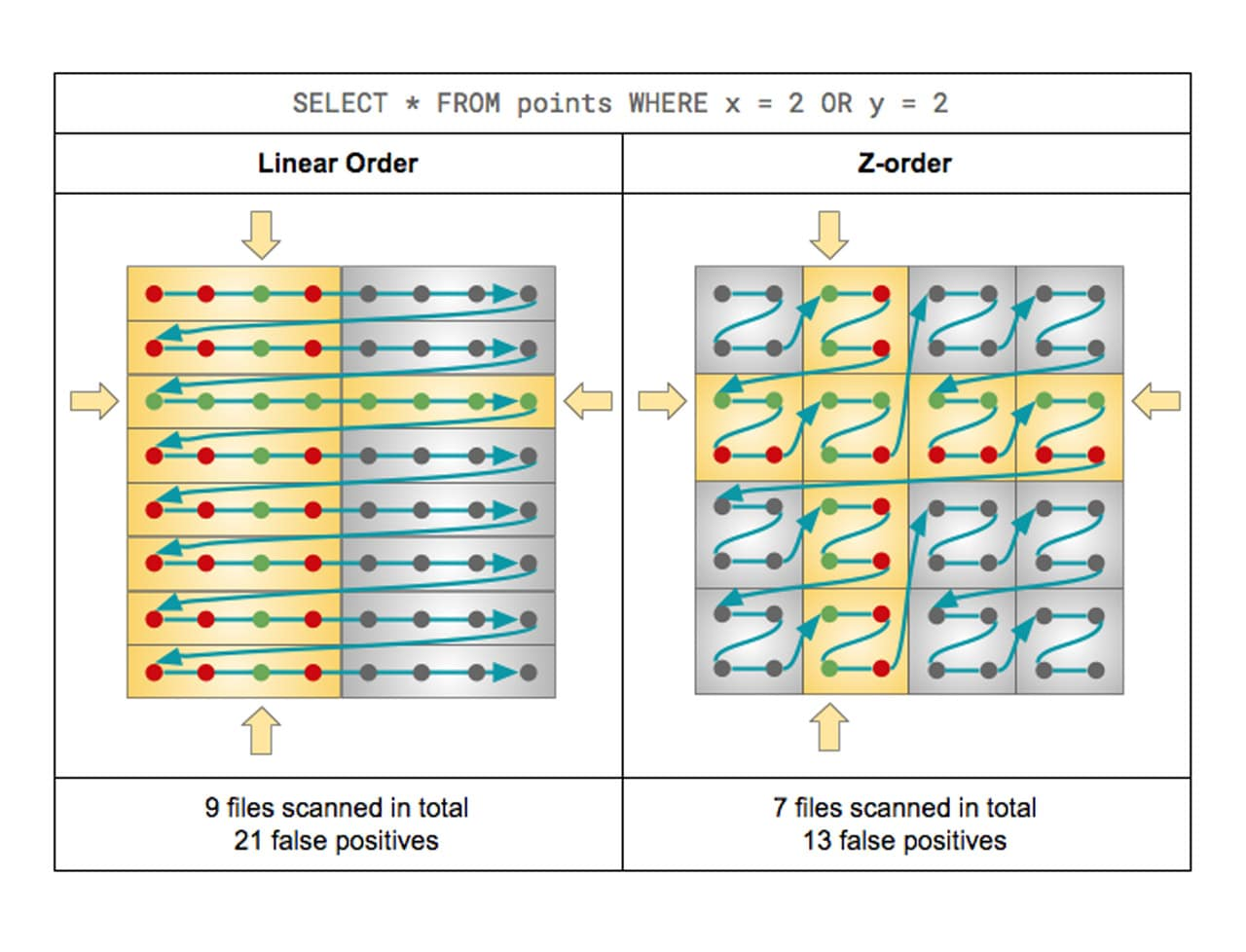
If you expect a column to be commonly used in query predicates and if that column has high cardinality (that is, a large number of distinct values), then use ZORDER BY.
You can specify multiple columns for ZORDER BY as a comma-separated list. However, the effectiveness of the locality drops with each extra column. Z-ordering on columns that do not have statistics collected on them would be ineffective and a waste of resources. This is because data skipping requires column-local stats such as min, max, and count. You can configure statistics collection on certain columns by reordering columns in the schema, or you can increase the number of columns to collect statistics on.
To improve query speed, Delta Lake supports the ability to optimize the layout of data stored in cloud storage with Z-Ordering, also known as multi-dimensional clustering. Z-Orders are used in similar situations as clustered indexes in the database world, though they are not actually an auxiliary structure. A Z-Order will cluster the data in the Z-Order definition, so that rows like column values from the Z-order definition are collocated in as few files as possible.
Most database systems introduced indexing as a way to improve query performance. Indexes are files, and thus as the data grows in size, they can become another big data problem to solve. Instead, Delta Lake orders the data in the Parquet files to make range selection on object storage more efficient. Combined with the stats collection process and data skipping, Z-Order is similar to seek vs. scan operations in databases, which indexes solved, without creating another compute bottleneck to find the data a query is looking for.
For Z-Ordering, the best practice is to limit the number of columns in the Z-Order to the best 1-4. We chose the foreign keys (foreign keys by use, not actually enforced foreign keys) of the 3 largest dimensions which were too large to broadcast to the workers.
OPTIMIZE MY_FACT_TABLE
ZORDER BY (LARGEST_DIM_FK, NEXT_LARGEST_DIM_FK, ...)
Additionally, if you have tremendous scale and 100's of billions of rows or Petabytes of data in your fact table, you should consider partitioning to further improve file skipping. Partitions are effective when you are actively filtering on a partitioned field.
Data skipping with Z-order indexes for Delta Lake | Databricks on AWS
Create Z-Orders on your dimension key fields and most likely predicates
Although Databricks does not enforce primary keys on a Delta table, since you are reading this blog, you likely have dimensions and a surrogate key exists - one that is an integer or big integer and is validated and expected to be unique.
One of the dimensions we were working with had over 1 billion rows and benefitted from the file skipping and dynamic file pruning after adding our predicates into the Z-Order. Our smaller dimensions also had Z-Orders on the dimension key field and were broadcasted in the join to the facts. Similar to the advice on fact tables, limit the number of columns in the Z-Order to the 1-4 fields in the dimension that are most likely to be included in a filter in addition to the key.
OPTIMIZE MY_BIG_DIM
ZORDER BY (MY_BIG_DIM_PK, LIKELY_FIELD_1, LIKELY_FIELD_2)
Partitions vs Z-Ordering
- Z-order works in tandem with the
OPTIMIZEcommand. You cannot combine files across partition boundaries, and so Z-order clustering can only occur within a partition. For unpartitioned tables, files can be combined across the entire table. - Partitioning works well only for low or known cardinality fields (for example, date fields or physical locations), but not for fields with high cardinality such as timestamps. Z-order works for all fields, including high cardinality fields and fields that may grow infinitely (for example, timestamps or the customer ID in a transactions or orders table).
When to partition tables on Databricks | Databricks on AWS
Analyze Table to gather statistics for Adaptive Query Execution Optimizer
One of the major advancements in Apache Spark 3.0 was the Adaptive Query Execution, or AQE for short. As of Spark 3.0, there are three major features in AQE, including coalescing post-shuffle partitions, converting sort-merge join to broadcast join, and skew join optimization. Together, these features enable the accelerated performance of dimensional models in Spark.
In order for AQE to know which plan to choose for you, we need to collect statistics about the tables. You do this by issuing the ANALYZE TABLE command. Customers have reported that collecting table statistics has significantly reduced query execution for dimensional models, including complex joins.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
Photon runtime
Photon runtime | Databricks on AWS
Optimization recommendations on Databricks | Databricks on AWS
How to Get the Best Performance from Delta Lake Star Schema Databases - The Databricks Blog
Findings
- using createdAtDate vs createdAt::date doesn't make any difference in run query
Compute
Databricks supports various cluster types:
- All-purpose clusters
- Job clusters
- SQL Warehouses (Classic and Serverless)
All-purpose clusters are dedicated for interactive usage, e.g.:
- exploration of the datasets using Notebooks
- development of new ETL pipelines
- interactive ML model development
- Multiple users might use the same cluster at the same time
It's not recommended to use all-purpose clusters for any kind of automated workflow deploy and launch. For such cases, use job clusters - by this you'll ensure proper resource isolation and independence of any other activities of other users on the all-purpose clusters.
Others
Optimizing AWS S3 Access for Databricks - The Databricks Blog
- S3 Endpoint is almost always better than NAT Gateway.
How to Extract Large Query Results Through Cloud Object Stores - The Databricks Blog