Deep dive / Best practices
Insert performance
https://stackoverflow.com/questions/16485425/aws-redshift-jdbc-insert-performance
Optimizations / Best practices
- https://aws.amazon.com/about-aws/whats-new/2020/12/amazon-redshift-announces-automatic-table-optimization
- https://docs.aws.amazon.com/redshift/latest/dg/c_designing-tables-best-practices.html
- https://docs.aws.amazon.com/redshift/latest/dg/c_designing-queries-best-practices.html
- https://www.youtube.com/watch?v=TJDtQom7SAA
- https://aws.amazon.com/blogs/big-data/top-8-best-practices-for-high-performance-etl-processing-using-amazon-redshift
- https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-techniques-for-amazon-redshift
- https://aws.amazon.com/blogs/big-data/amazon-redshift-engineerings-advanced-table-design-playbook-preamble-prerequisites-and-prioritization
- Improve your ETL performance using multiple Redshift warehouses for writes (Preview) | AWS Big Data Blog
Data storage, ingestion and ELT
Redundancy
Amazon Redshift utilizes locally attached storage devices
Compute nodes have 2 to 3 times the advertised storage capacity
Global commit ensures all permanent tables have written blocks to another node in the cluster to ensure data redundancy
Asynchronously backup blocks to Amazon S3 - always consistent snapshot
Every 5 GB of changed data or eight hours
User on-demand manual snapshots
To disable backups at the table level: CREATE TABLE example (id int) BACKUP NO; Temporary tables
Blocks are not mirrored to the remote partition - two-times faster write performance
Do not trigger a full commit or backups
Transactions
Amazon Redshift is a fully transactional, ACID complaint data warehourse
- Isolation level is serializable
- Two phase commits (local and global commit phases)
Design consideration
- Because of the expense of commit overhead, limit commits by explicitly creating transactions
Data ingestion: COPY statement
Ingestion throughput
Each slice's query processors can load one file at a time:
- Streaming decompression
- Parse
- Distribute
- Write
Realizing only partial node usage at 6.25% of slices are active
Number of input files should be a multiple of the number of slices
Splitting the single file into 16 input files, all slices are working to maximize ingestion performance
COPY continues to scale linearly as you add nodes
Recommendation is to use delimited files - 1 MB to 1 GB after gzip compression
Best practices: COPY ingestion
Delimited files are recommend
- Pick a simple delimites '|' or ',' or tabs
- Pick a simple NULL character (N)
- Use double quotes and an escape character ('') for varchars
- UTF-8 varchar columns take four bytes per char
Split files into a nuber that is a multiple of the total number of slices in the Amazon Redshift cluster
SELECT count(slice) from stv_slices;
Data ingestion: Amazon Redshift Spectrum
Use INSERT INTO SELECT against external Amazon S3 tables
- Aggregate incoming data
- Select subset of columns and/or rows
- Manipulate incoming column data with SQL
Best practices:
- Save cluster resources for querying and reporting rather than on ELT
- Filtering/aggregating incoming data can improve performance over COPY
Design considerations
- Repeated reads against Amazon S3 are not transactional
- $5/TB of (compressed) data scanned
Design considerations: Data ingestion
Designed for large writes
- Batch processing system, optimized for processing massive amounts of data
- 1 MB size plus immutable blocks means that we clone blocks on write so as not to introduce fragmentation
- Small write (
110 rows) has similar cost to a larger write (~100K rows)
UPDATE and DELETE
- Immutable blocks means that we only logically delete rows on UPDATE or DELETE
- Must VACUUM or DEEP COPY to remove ghost rows from table
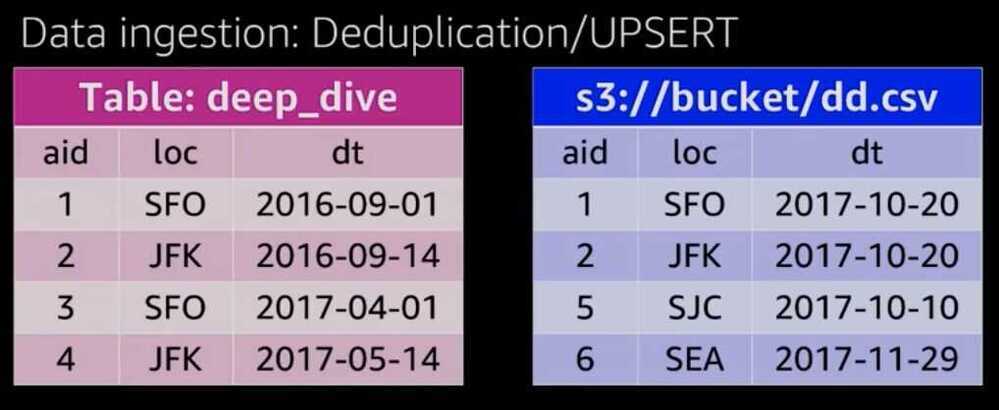
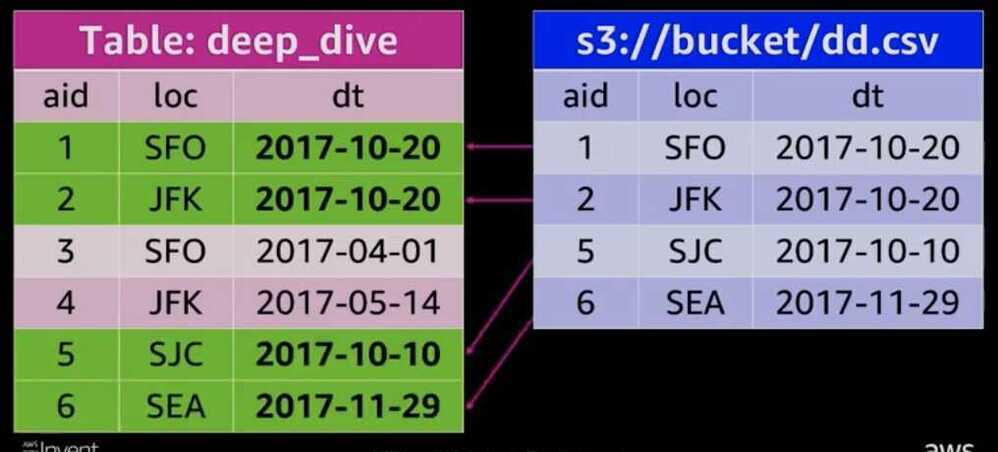
Steps
- Load CSV data into a staging table
- Delete duplicate data from the production table
- Insert (or append) data from the staging into the production table
Create a Transaction

Best practices: ELT
Wrap workflow/statements in an explicit transaction
Consider using DROP TABLE or TRUNCATE instead of DELETE
Staging tables:
- Use temporary table or permanent table with the "BACKUP NO" option
- If possible use DISTSTYLE KEY on both the staging table and production table to speed up the the INSERT INTO SELECT statement
- Turn off automatic compression - COMPUPDATE OFF
- Copy compression settings from production table or use ANALYZE COMPRESSION statement
- Use CREATE TABLE LIKE or write encodings into the DDL
- For copying a large number of rows (> hundreds of millions) consider using ALTER TABLE APPEND instead of INSERT INTO SELECT
VACUUM and ANALYZE
VACUUM will globally sort the table and remove rows that are marked as deleted
- For tables with a sort key, ingestion operations will locally sort new data and write it into the unsorted region
ANALYZE collects table statistics for optimal query planning
Best Practices:
- VACUUM should be run only as necessary
- Typically nightly or weekly
- Consider Deep Copy (recreating and copying data) for larger or wide tables
- ANALYZE can be run periodically after ingestion on just the columns taht WHERE predicates are filtered on
- Utility to VACUUM and ANALYZE all the tables in the cluster