Understanding Basic Computer Organization
Instruction Execution Cycle
-
Instruction Fetch - Obtain instruction from program store
-
Instruction Decode - Determine required actions and instruction size
-
Operand Fetch - Locate and obtain operand data
-
Execute - Compute result value or status
-
Result Store - Deposit results in storage for later use
-
Next Instruction - Determine successor instruction
Processor Memory Interaction
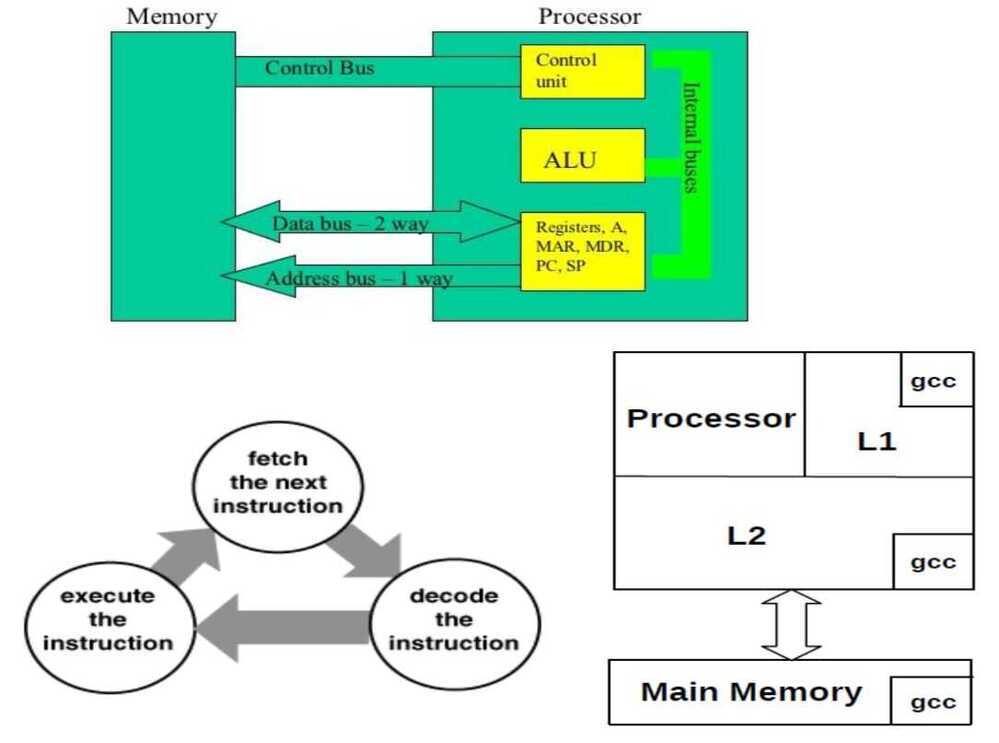
Inside the CPU
 Instruction Execution Cycle
Instruction Execution Cycle
-
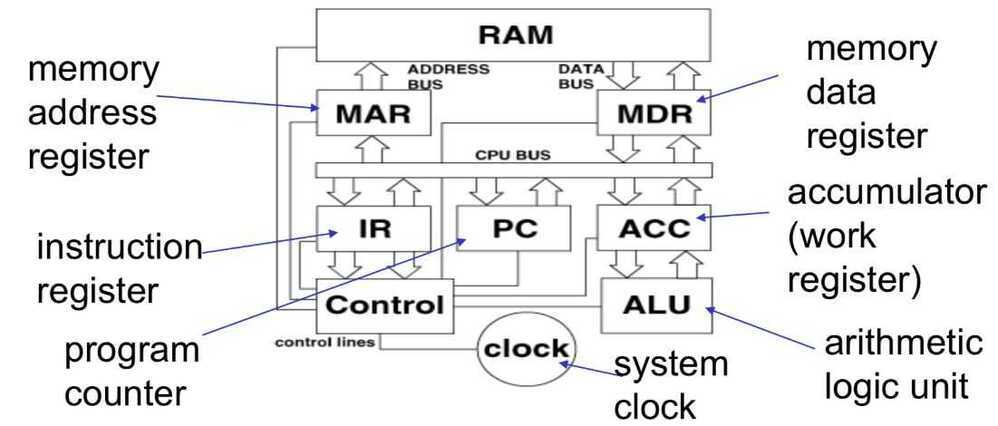
Address of the next instruction is transferred from PC to MAR
-
The instruction is located in memory
-
Instruction is copied from memory to MDR
-
Instruction is transferred to and decoded in the IR
-
Control unit sends signals to appropriate devices to cause execution of the instruction
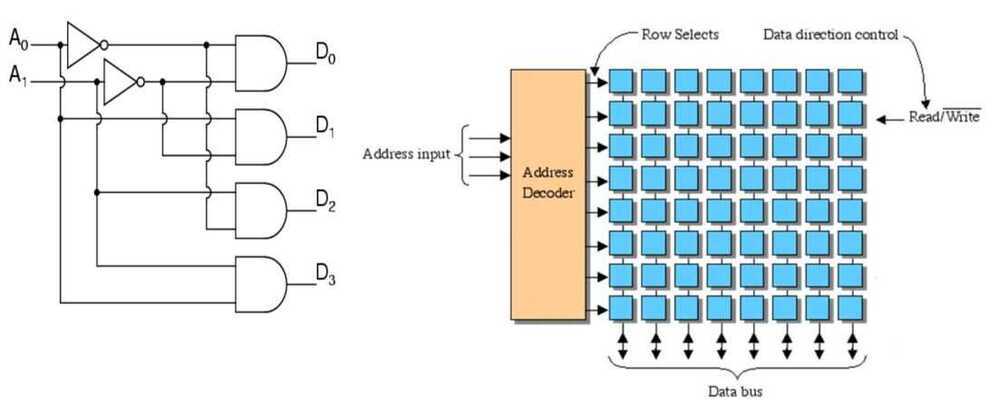
Address Decoder is used to decode memory addresses
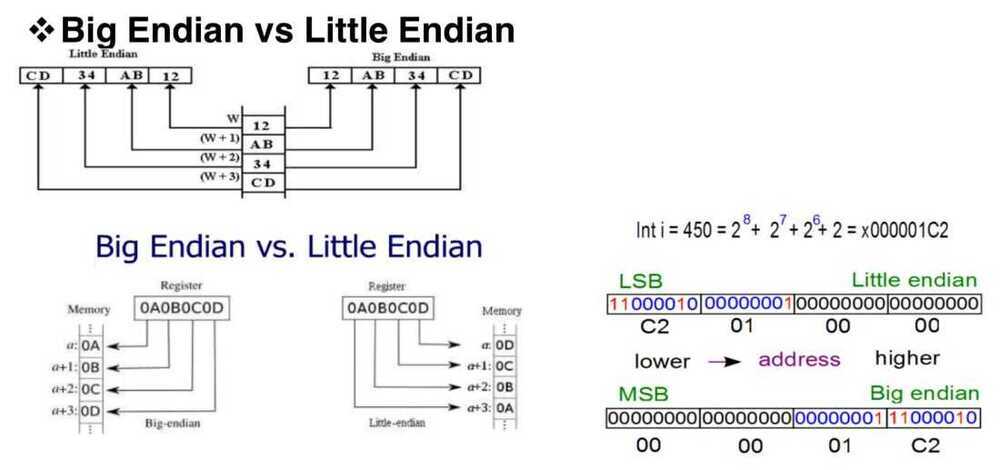
Byte Ordering
Byte/Word Alignment
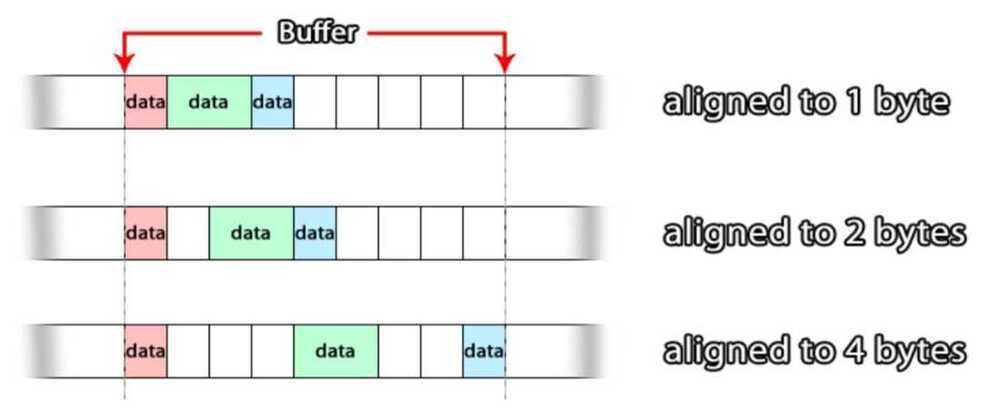
Types of Processor Operations
-
Arithmetic and Logical Operations
-
integer arithmetic
-
comparing two quantities
-
shifting, rotating bits in a quantity
-
testing, comparing, and converting bits
-
-
Data Movement Operations
-
moving data from memory to cpu
-
moving data from memory to memory
-
input and output
-
-
Program Control Operations
-
starting a program
-
halting a program
-
skipping to other instructions
-
testing data to decide whether to skip over some instructions
-
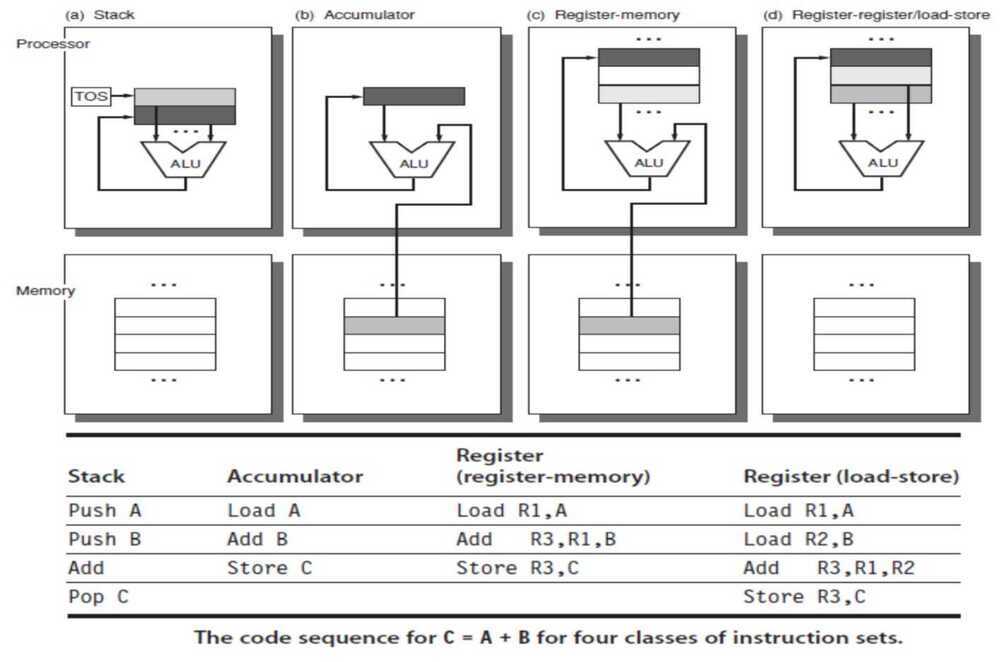
Instruction Set Architecture (ISA)
An ISA is an abstract model of a computer. It is also referred to as architecture or computer architecture. A realization of an ISA, such as a central processing unit(CPU), is called an implementation.
https://en.wikipedia.org/wiki/Instruction_set_architecture Based on where opcode and operand are
-
Stack architecture
-
Accumulator architecture
-
Register-Memory architecture
-
Register-Register / Load Store architecture

Addressing Modes
 - Immediate Addressing
- Immediate Addressing
The simplest addressing mode isImmediate addressing where you write the data value into the instruction.
In Pentium assembler this is the default and:
MOV EAX,04
- Register Indirect Addressing
- Indexed Addressing https://www.i-programmer.info/babbages-bag/150.html
Branch Predictor
In computer architecture, a branch predictor is a digital circuit that tries to guess which way a branch(e.g. an if--then--else structure) will go before this is known definitively. The purpose of the branch predictor is to improve the flow in the instruction pipeline. Branch predictors play a critical role in achieving high effective performance in many modern pipelinedmicroprocessor architectures such as x86.
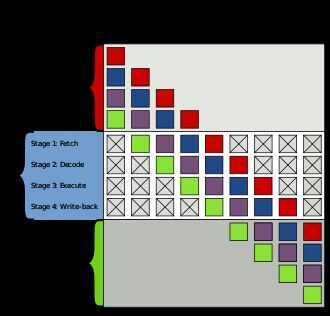
Example of 4-stage pipeline. The colored boxes represent instructions independent of each other. Two-way branching is usually implemented with a conditional jump instruction. A conditional jump can either be "not taken" and continue execution with the first branch of code which follows immediately after the conditional jump, or it can be "taken" and jump to a different place in program memory where the second branch of code is stored. It is not known for certain whether a conditional jump will be taken or not taken until the condition has been calculated and the conditional jump has passed the execution stage in the instruction pipeline (see fig. 1). Without branch prediction, the processor would have to wait until the conditional jump instruction has passed the execute stage before the next instruction can enter the fetch stage in the pipeline. The branch predictor attempts to avoid this waste of time by trying to guess whether the conditional jump is most likely to be taken or not taken. The branch that is guessed to be the most likely is then fetched and speculatively executed. If it is later detected that the guess was wrong then the speculatively executed or partially executed instructions are discarded and the pipeline starts over with the correct branch, incurring a delay. The time that is wasted in case of abranch misprediction is equal to the number of stages in the pipeline from the fetch stage to the execute stage. Modern microprocessors tend to have quite long pipelines so that the misprediction delay is between 10 and 20 clock cycles. As a result, making a pipeline longer increases the need for a more advanced branch predictor. The first time a conditional jump instruction is encountered, there is not much information to base a prediction on. But the branch predictor keeps records of whether branches are taken or not taken. When it encounters a conditional jump that has been seen several times before then it can base the prediction on the history. The branch predictor may, for example, recognize that the conditional jump is taken more often than not, or that it is taken every second time. Branch prediction is not the same as branch target prediction. Branch prediction attempts to guess whether a conditional jump will be taken or not. Branch target prediction attempts to guess the target of a taken conditional or unconditional jump before it is computed by decoding and executing the instruction itself. Branch prediction and branch target prediction are often combined into the same circuitry. Implementation
- 1.1 Static branch prediction
- 1.2 Dynamic branch prediction
- 1.3 Random branch prediction
- 1.4 Next line prediction
- 1.5 One-level branch prediction
- 1.6 Two-level predictor
- 1.7 Local branch prediction
- 1.8 Global branch prediction
- 1.9 Alloyed branch prediction
- 1.10 Agree predictor
- 1.11 Hybrid predictor
- 1.12 Loop predictor
- 1.13 Indirect branch predictor
- 1.14 Prediction of function returns
- 1.15 Overriding branch prediction
- 1.16 Neural branch prediction
https://en.wikipedia.org/wiki/Branch_predictor
Application Binary Interface (ABI)
In computer software, anapplication binary interface(ABI) is an interface between two binary program modules; often, one of these modules is a library or operating system facility, and the other is a program that is being run by a user. AnABIdefines how data structures or computational routines are accessed in machine code, which is a low-level, hardware-dependent format; in contrast, an API defines this access in source code, which is a relatively high-level, hardware-independent, often human-readable format. A common aspect of an ABI is the calling convention, which determines how data is provided as input to or read as output from computational routines; examples are the x86 calling conventions. Adhering to an ABI (which may or may not be officially standardized) is usually the job of a compiler, operating system, or library author; however, an application programmer may have to deal with an ABI directly when writing a program in a mix of programming languages, which can be achieved by using foreign function calls.
https://en.wikipedia.org/wiki/Application_binary_interface
ELF (Executable and Linkable Format)
In computing, theExecutable and Linkable Format(ELF, formerly namedExtensible Linking Format), is a common standard file format for executable files, object code, shared libraries, and core dumps. First published in the specification for the application binary interface(ABI) of the Unix operating system version named System V Release 4 (SVR4), and later in the Tool Interface Standard, it was quickly accepted among different vendors of Unix systems. In 1999, it was chosen as the standard binary file format for Unix and Unix-like systems on x86 processors by the 86open project.
By design, the ELF format is flexible, extensible, and cross-platform. For instance it supports different endiannesses and address sizes so it does not exclude any particular central processing unit (CPU) or instruction set architecture. This has allowed it to be adopted by many different operating systems on many different hardware platforms
ELF is used as standard file format for object files on Linux. Prior to this, the a.out file format was being used as a standard but lately ELF took over the charge as a standard.
ELF supports :
- Different processors
- Different data encoding
- Different classes of machines
File Layout
Each ELF file is made up of one ELF header, followed by file data. The data can include:
- Program header table, describing zero or more memory segments
- Section header table, describing zero or more sections
- Data referred to by entries in the program header table or section header table
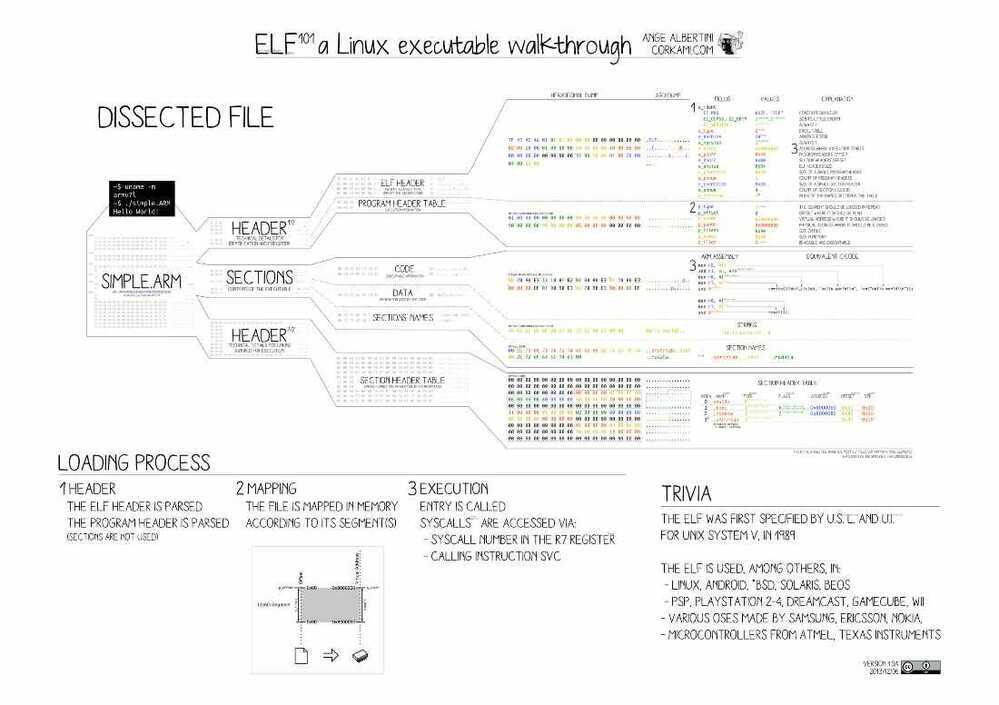
https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
https://www.thegeekstuff.com/2012/07/elf-object-file-format
Von Neumann Architecture
Thevon Neumann architecture - also known as thevon Neumann modelorPrinceton architecture - is a computer architecture based on a 1945 description by John von Neumann and others in the First Draft of a Report on the EDVAC. That document describes a design architecture for an electronic digital computer with these components:
- A processing unit that contains an arithmetic logic unit and processor registers
- A control unit that contains an instruction register and program counter
- Memory that stores data and instructions
- External mass storage
- Input and output mechanisms
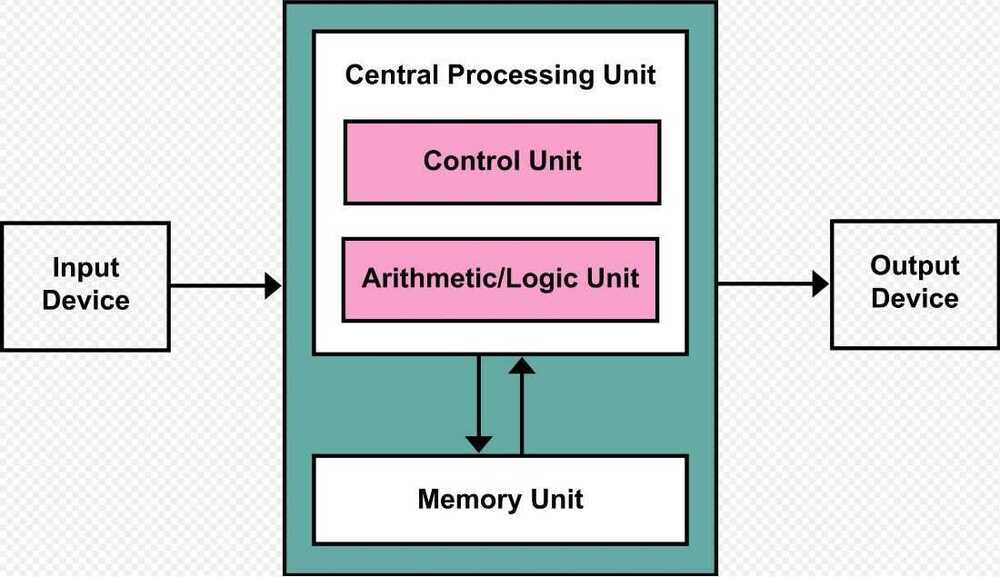
The term "von Neumann architecture" has evolved to mean any stored-program computer in which an instruction fetch and a data operation cannot occur at the same time because they share a common bus. This is referred to as the von Neumann bottleneck, and often limits the performance of the system.
The design of a von Neumann architecture machine is simpler than a Harvard architecture machine - which is also a stored-program system but has one dedicated set of address and data buses for reading and writing to memory, and another set of address and data buses to fetch instructions.
A stored-program digital computer keeps both program instructions and data in read--write, random-access memory(RAM). Stored-program computers were an advancement over the program-controlled computers of the 1940s, such as the Colossus and the ENIAC. Those were programmed by setting switches and inserting patch cables to route data and control signals between various functional units. The vast majority of modern computers use the same memory for both data and program instructions, but have caches between the CPU and memory, and, for the caches closest to the CPU, have separate caches for instructions and data, so that most instruction and data fetches use separate buses ([split cache architecture](https://en.wikipedia.org/wiki/Modified_Harvard_architecture#Split-cache_(or_almost-von-Neumann) _architecture)).
Historically there have been 2 types of Computers:
-
Fixed Program Computers -- Their function is very specific and they couldn't be programmed, e.g. Calculators.
-
Stored Program Computers -- These can be programmed to carry out many different tasks, applications are stored on them, hence the name.
Main Memory Unit (Registers)
-
**Accumulator:**Stores the results of calculations made by ALU
-
**Program Counter (PC):**Keeps track of the memory location of the next instructions to be dealt with. The PC then passes this next address to Memory Address Register (MAR)
-
**Memory Address Register (MAR):**It stores the memory locations of instructions that need to be fetched from memory or stored into memory
-
**Memory Data Register (MDR):**It stores instructions fetched from memory or any data that is to be transferred to, and stored in, memory
-
**Current Instruction Register (CIR):**It stores the most recently fetched instructions while it is waiting to be coded and executed
-
**Instruction Buffer Register (IBR):**The instruction that is not to be executed immediately is placed in the instruction buffer register IBR
https://en.wikipedia.org/wiki/Von_Neumann_architecture
https://www.geeksforgeeks.org/computer-organization-von-neumann-architecture