Amazon CloudWatch
Monitor Resources and Applications
Queries
Cloudwatch search queries
-Select -query
-QUERY -READ -WRITE
-server -lms_p2021030122 -sttashrdsmain -vishal_goyal -rdsadmin -deepak_sood -api-v2_p2021030121 -loan-tape-etl_c2021030122
Logs Insight
fields *@timestamp*, *@message*
| sort *@timestamp* desc
| limit 20
fields *@timestamp*, *@message* | filter *@message* like /(?i)(connect)/ # | filter @timestamp > 1668527666 | fields tomillis(*@timestamp*) as millis # | filter @millis < 1668566034 | parse *@message* ',*,*,' as @instance,@user | parse *@message* /(?<@ip>d{1,3}.d{1,3}.d{1,3}.d{1,3})/ | stats count() AS counter by @user | sort by @counter desc | limit 100
3 categories of logs
- Vended logs - natively published by AWS services on behalf of the customer
- Logs published by AWS services
- Custom logs
CloudWatch billing and cost - Amazon CloudWatch
Publish custom metrics - Amazon CloudWatch
Amazon CloudWatch Application Insights
Amazon CloudWatch Application Insights - Amazon CloudWatch
Cost Optimizing
- Determine which log group is causing a bill increase | AWS re:Post
- Optimizing Amazon CloudWatch Costs in Under 5 Minutes (Step-by-Step Guide) - YouTube
- Reduce and prevent charges in Amazon CloudWatch | AWS re:Post
Cloudwatch Alarm Actions
Using Amazon CloudWatch alarm actions, you can create alarms that automatically stop, terminate, reboot, or recover your EC2 instances. You can use the stop or terminate actions to help you save money when you no longer need an instance to be running. You can use the reboot and recover actions to automatically reboot those instances or recover them onto new hardware if a system impairment occurs.
There are a number of scenarios in which you might want to automatically stop or terminate your instance. For example, you might have instances dedicated to batch payroll processing jobs or scientific computing tasks that run for a period of time and then complete their work. Rather than letting those instances sit idle (and accrue charges), you can stop or terminate them, which helps you to save money. The main difference between using the stop and the terminate alarm actions is that you can easily restart a stopped instance if you need to run it again later. You can also keep the same instance ID and root volume. However, you cannot restart a terminated instance. Instead, you must launch a new instance.
You can add the stop, terminate, or reboot, actions to any alarm that is set on an Amazon EC2 per-instance metric, including basic and detailed monitoring metrics provided by Amazon CloudWatch (in the AWS/EC2 namespace), in addition to any custom metrics that include the "InstanceId=" dimension, as long as the InstanceId value refers to a valid running Amazon EC2 instance. You can also add the recover action to alarms that is set on any Amazon EC2 per-instance metric except for StatusCheckFailed_Instance.
Create alarms to stop, terminate, reboot, or recover an EC2 instance - Amazon CloudWatch
Composite Alarms
Combining alarms - Amazon CloudWatch
CW composite alert to create complex alert. We can use operators like OR, AND and NOT. For example, if we want to trigger an alert when both CPU and DiskReadOnly breach their thresholds, we would need to create a composite alert. This involves using two metrics with an AND operator to ensure that both conditions are met before triggering the alert.
ALARM("django-slave-2-alarm-CPU-80%") OR
ALARM("learn-dbread-alarm-CPU-80%") OR
ALARM("django-prod-slave1-alarm-CPU-80%") OR
ALARM("prod-django-master-alarm-CPU-80%")
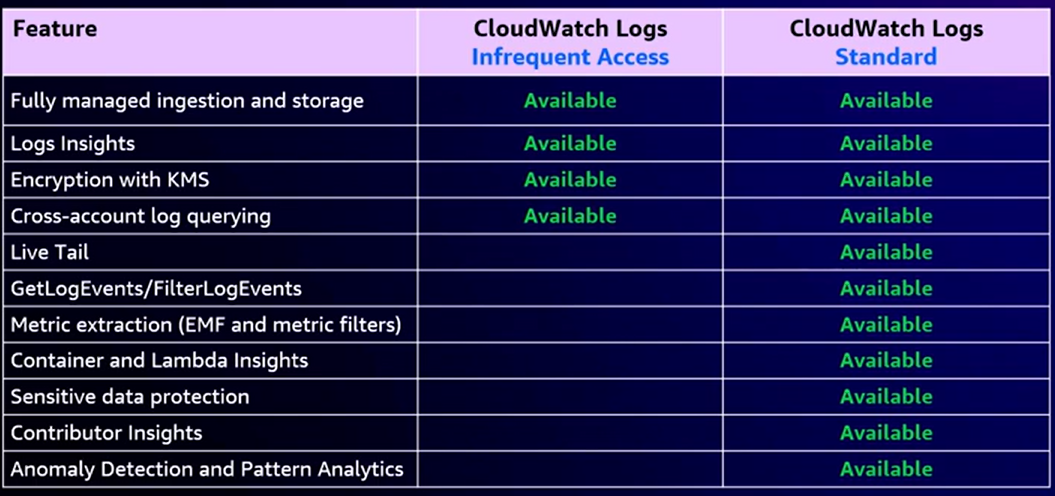
Features Comparison: IA vs Standard Log Class
Releases
- AWS re:Invent 2024 - [NEW LAUNCH] What’s new with Amazon CloudWatch (COP381-NEW) - YouTube
- CloudWatch Database Insights
- Unified view in CloudWatch
- Configurable fleet-wide views
- Detailed SQL query metrics
- Application context with dependency mapping
- Easy getting-started experience with pre-built health dashboards
- Fully managed no agent experience
- CloudWatch unified navigation
- Navigation across related telemetry and resources
- Automatically reveals contextual relationships
- Single-click visualizations of key telemetry
- Expertly navigate systems
- On by default!
- OpenSearch on CloudWatch
- Enhanced query capabilities (PPL/SQL)
- Analyze logs in OpenSearch without data duplication
- Eliminates the need for complex ETL pipelines
- Leverage best of CloudWatch and OpenSearch features
- Distributed systems visibility
- Ability to see which piece of a request pathway has the issue
- Compare and contrast against similar spans
- It's an analytics problem: Finding specific span types, aggregating spans by properties, slicing/dicing
- Answer the question: Which component, and what's unique about this component?
- CloudWatch span analytics
- Complete visibility into application transactions at any scale
- Ingest spans as structured logs: no more sampling
- Interactive visual editor to slice and dice spans
- Leverage all CloudWatch Logs features
- One-click enablement for AWS X-Ray customers
- Amazon Q Developer Ops Assistant
- Investigate and remediate operational issues
- Guided root-cause analysis
- Automatically initiate investigations from alarms
- Collaborative space to share information
- End-to-end integrations with curated runbooks, chat, and ticketing systems
- CloudWatch Database Insights
- AWS re:Invent 2023 - Get actionable insights from Amazon CloudWatch Logs (COP326) - YouTube
- Challenges with logs management
- Volume of logs continues of grow
- One size fits all
- Managing multiple solutions
- Amazon CloudWatch Logs Infrequent Access
- Fully managed ingestion, storage and encryption
- Investigate logs using purpose build Log Insights query engine
- 50% lower costs than standard class
- Consolidate all your logs in CloudWatch
- Pattern Analysis in Logs Insights
- AI-powered natural language query generation
- Challenges with logs management
- 2022
- Cross account log analytics
- Sensitive data protection
- Increased query concurrency for logs insights
- 2023
- Live tail
- EMP enhancements (Hi-res metrics, Error visibility, Header removal)
- 3 New log insights commands (dedup, pattern and multi-stats)
- Logs insights enhancements (concurrency, timeout, log group selection)
- Account-level sensitive data protection