Sagemaker Lakehouse
Amazon SageMaker - Unified, Open, and Secure Data Lakehouse Architecture
Unified data lakehouse architecture in Amazon SageMaker - FAQs – AWS
Data lake centric
- Takes away decades of database capabilities such as transactions
- Slow interactive queries at high concurrency
- Lacks intelligent storage optimizations
Data warehouse centric
- Lacks open access to data warehouse data
- Limited engine interoperability with open table formats
- Still creates data silo
Zero-ETL Integration
Bring your data into the lakehouse without expensive pipeline management
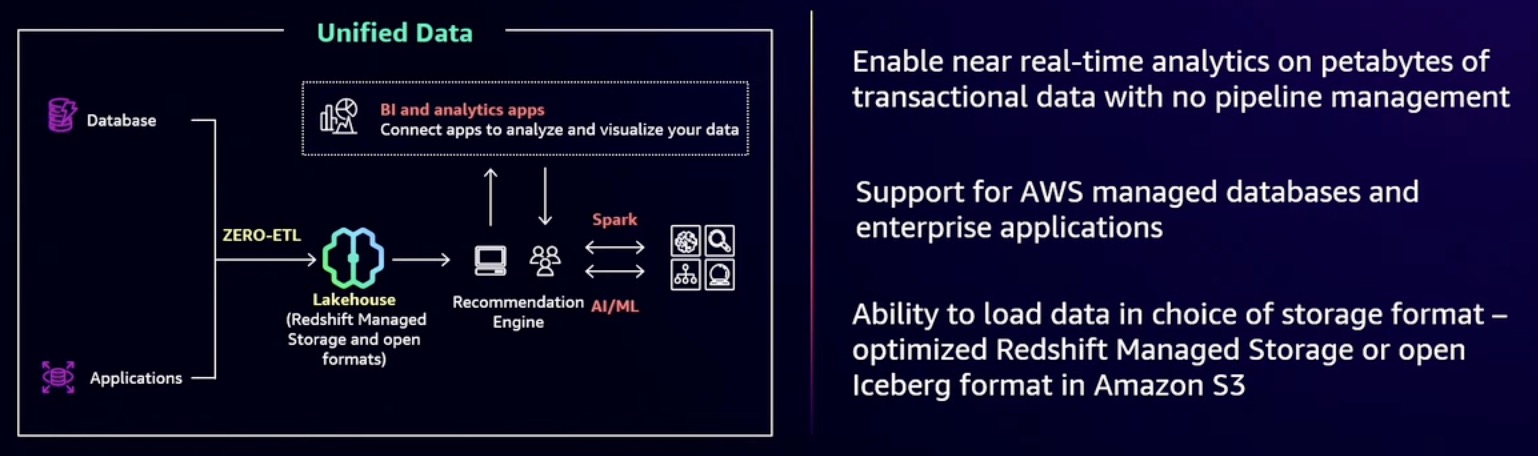
Aurora zero-ETL integrations - Amazon Aurora
Amazon Sagemaker Lakehouse Components
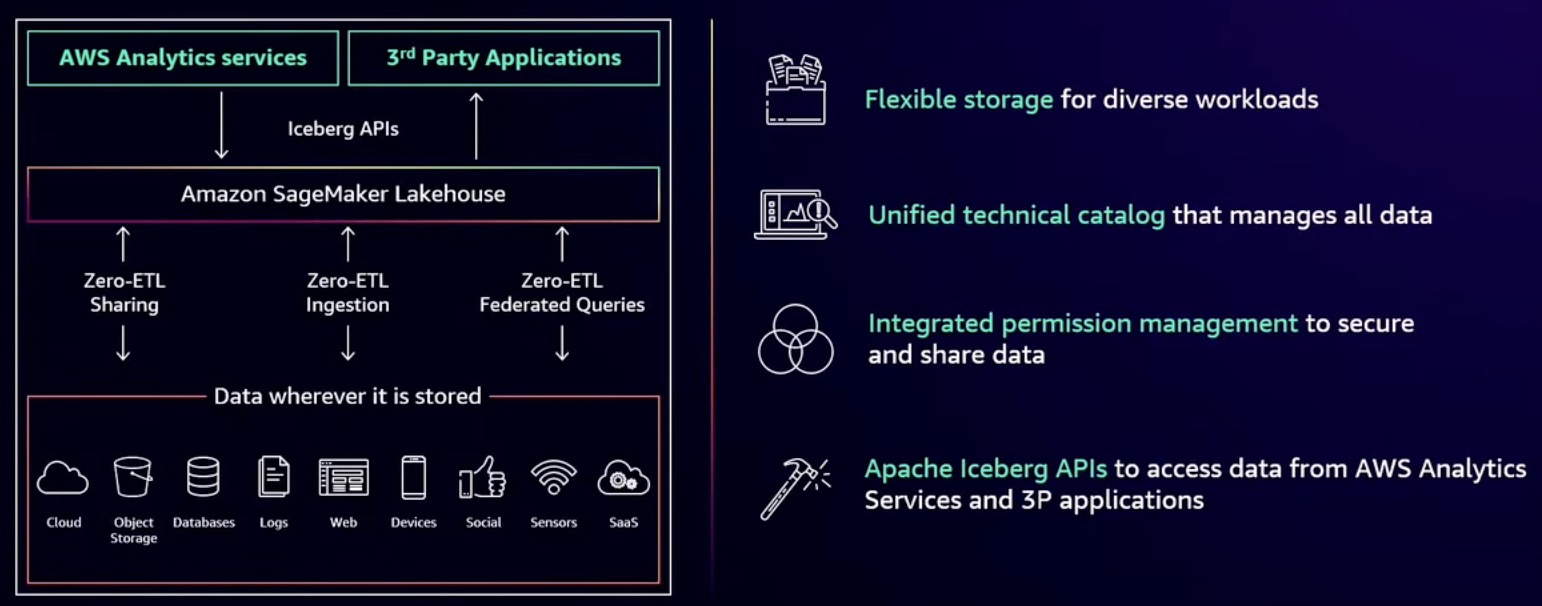
Storage
- Amazon S3
- Store your data in Amazon S3 buckets
- Access your data using Apache Iceberg REST catalog APIs
- Enable automatic table optimization for Apache Iceberg tables
- Get high performance with managed statistics
- Access data seamlessly from AWS and 3P engines
- Amazon S3 Tables
- New S3 storage class for Apache Iceberg data lakes
- Amazon S3 APls to read/write to S3 tables
- Managed Iceberg table maintenance
- Simple integration with Lakehouse (preview)
- 10x requests per second compared to standard Amazon S3 buckets
- Table Maintenance for Iceberg Tables
- Compaction: Consolidate small objects into larger ones to improve query performance
- Snapshot Retention: Remove unused snapshots
- Redshift Managed Storage (RMS)
- Publish data from your existing Amazon Redshift data warehouses to the Lakehouse
- Create new datasets for your data lake in Redshift Managed Storage natively in the Lakehouse
- Benefit from ML-powered optimizations for frequently running workloads
- Redshift Managed Storage use cases
- Near real-time ingestion
- Transactionally consistent change data capture (CDC) from operational data sources
- Multi-statement and multi-table transactional consistency
- 7x better throughput from Amazon Redshift for BI analytics
- Faster performance for small writes in Apache Spark
- Faster reads from Spark compared to Apache Iceberg tables
Unified Technical Catalog
- Dynamic catalog hierarchy to organize data in the storage system
- Each catalog maps to a storage type
- Managed catalogs to create new data
- Redshift Managed Storage
- Amazon S3
- Bring data into a Federated Catalog
- Amazon Redshift
- Amazon S3 table buckets
- External Sources like MySQL, BigQuery
Integrated Access Control
- Support for fine-grained access control
- Allow/deny access at table level
- Allow/deny access at column level
- Allow/deny access at cell level
- Industry standard access controls for 3P engines
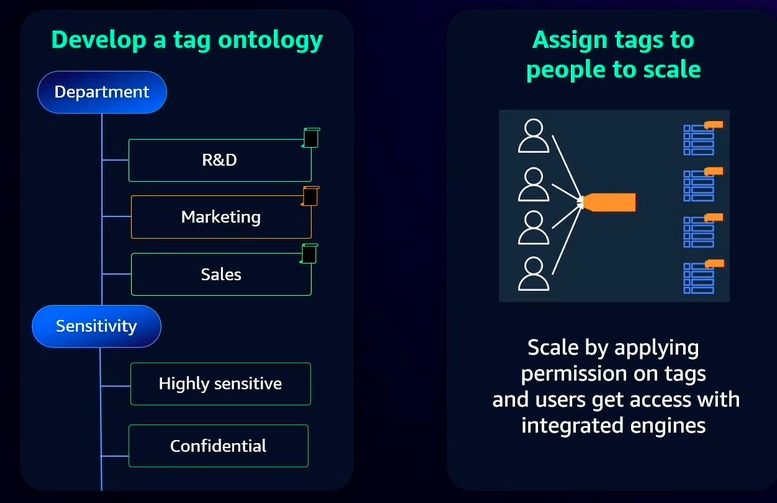
- Tag-based access to data(TBAC)
- Role-based access to data(RBAC)
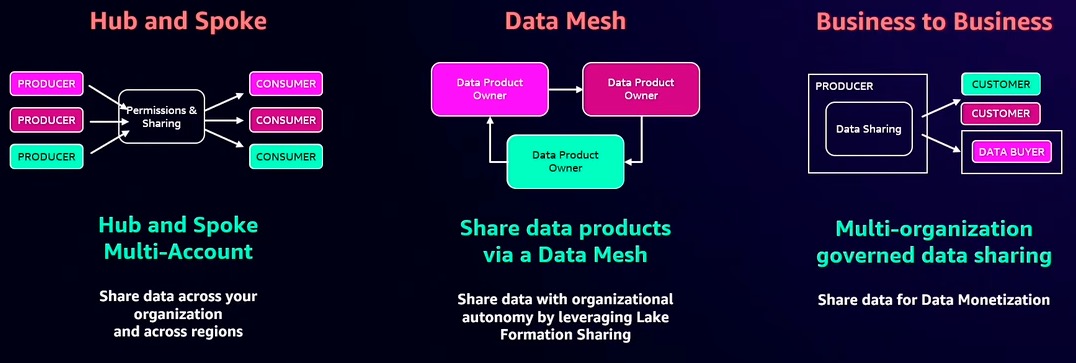
- Zero copy data sharing within and across enterprises
Fine Grained Access Control

Tag based access control (TBAC)
Zero copy data sharing models