Pre-Trained Models
Pre-trained models are neural networks trained on large datasets before being fine-tuned for specific tasks. These models capture intricate patterns and features, making them highly effective for image classification. By leveraging pre-trained models, developers can save time and computational resources. They can also achieve high accuracy with less data. Popular models like VGG, ResNet, and Inception have set benchmarks in the field.
Overview of Pre-Trained Models
Pre-trained models are an essential part of modern deep learning. These models are initially trained on large, general-purpose datasets like ImageNet. They learn to recognise various features, from simple edges to complex textures and objects. This extensive training allows them to generalise well, making them effective starting points for new tasks. By fine-tuning these models on specific datasets, developers can achieve high performance with less data and computation.
The architecture of pre-trained models varies, but they share common traits. They consist of multiple layers that progressively extract features from the input images. Early layers capture low-level features, while deeper layers recognise high-level patterns. Pre-trained models can be adapted to various domains, from medical imaging to autonomous driving. Their versatility and effectiveness make them invaluable tools in the field of computer vision.
Top Pre-Trained Models for Image Classification
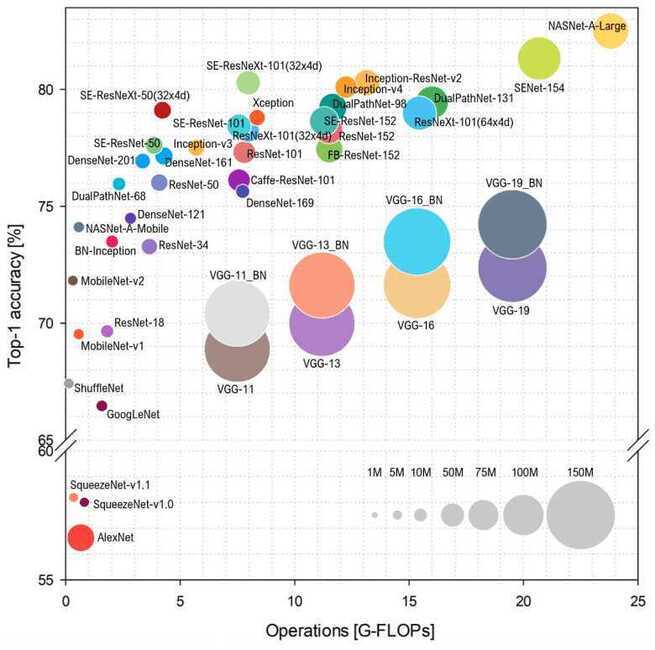
Several pre-trained models have become standards in image classification due to their performance and reliability. Here are the key models:
1. ResNet (Residual Networks)
- Overview: ResNet, introduced by Microsoft Research, revolutionized deep learning by using residual connections to mitigate the vanishing gradient problem in deep networks.
- Variants: ResNet-50, ResNet-101, ResNet-152.
- Key Features:
- Deep architectures (up to 152 layers).
- Residual blocks to allow gradients to flow through shortcut connections.
- Applications: General image classification, object detection, and feature extraction.
Vanishing gradient problem - Wikipedia
2. Inception (GoogLeNet)
- Overview: Developed by Google, the Inception network uses inception modules to capture multi-scale features.
- Variants: Inception v3, Inception v4, Inception-ResNet.
- Key Features:
- Inception modules with convolutional filters of multiple sizes.
- Efficient architecture balancing accuracy and computational cost.
- Applications: General image classification, object detection, and transfer learning.
3. VGG (Visual Geometry Group)
- Overview: Developed by the Visual Geometry Group at the University of Oxford, VGG models are known for their simplicity and depth.
- Variants: VGG-16, VGG-19.
- Key Features:
- Deep networks with 16 or 19 layers.
- Simple architecture using only 3×3 convolutions.
- Applications: General image classification and feature extraction.
4. EfficientNet
- Overview: Developed by Google, EfficientNet models achieve high accuracy with fewer parameters and computational resources.
- Variants: EfficientNet-B0 to EfficientNet-B7.
- Key Features:
- Compound scaling method to scale depth, width, and resolution.
- Efficient and accurate.
- Applications: General image classification and transfer learning.
5. DenseNet (Dense Convolutional Network)
- Overview: Developed by researchers at Cornell University, DenseNet connects each layer to every other layer in a feed-forward fashion.
- Variants: DenseNet-121, DenseNet-169, DenseNet-201.
- Key Features:
- Dense connections to improve gradient flow and feature reuse.
- Reduces the number of parameters compared to traditional convolutional networks.
- Applications: General image classification and feature extraction.
6. MobileNet
- Overview: Developed by Google, MobileNet models are designed for mobile and embedded vision applications.
- Variants: MobileNetV1, MobileNetV2, MobileNetV3.
- Key Features:
- Lightweight architecture optimized for mobile devices.
- Depthwise separable convolutions.
- Applications: Mobile image classification and embedded vision applications.
7. NASNet (Neural Architecture Search Network)
- Overview: Developed by Google using neural architecture search techniques to optimize the network structure.
- Variants: NASNet-A, NASNet-B, NASNet-C.
- Key Features:
- Automatically designed architectures using reinforcement learning.
- High accuracy with efficient performance.
- Applications: General image classification and transfer learning.
8. Xception (Extreme Inception)
- Overview: Developed by Google, Xception is an extension of the Inception architecture with depthwise separable convolutions.
- Key Features:
- Fully convolutional architecture.
- Depthwise separable convolutions for improved performance.
- Applications: General image classification and transfer learning.
9. AlexNet
- Overview: Developed by Alex Krizhevsky, AlexNet is one of the earliest deep learning models that popularized the use of CNNs in image classification.
- Key Features:
- Simple architecture with 8 layers.
- ReLU activation functions and dropout regularization.
- Applications: General image classification and historical benchmarks.
10. Vision Transformers (ViT)
- Overview: Developed by Google, Vision Transformers apply the transformer architecture, initially designed for NLP, to image classification.
- Key Features:
- Transformer encoder architecture.
- Scales well with large datasets and computational resources.
- Applications: General image classification and large-scale vision tasks.
YOLO - You Only Look Once
YOLO (You Only Look Once) is an object detection algorithm that uses a convolutional neural network (CNN), that's known for its speed and accuracy.
Here's how YOLO works:
- Grid: YOLO's CNN divides an image into a grid.
- Bounding boxes: Each cell in the grid predicts a number of bounding boxes.
- Class probabilities: Each cell also predicts a class probability, which indicates the likelihood of an object being present in the box.
YOLO is popular because of its single-stage architecture, real-time performance, and accuracy. It's well-suited for real-time applications like self-driving cars, video surveillance, and augmented reality.
Pre-trained models
- YOLOv8: This model offers a variety of pretrained models for different tasks and performance needs. It's easy to use, even for those new to computer vision, machine learning, or deep learning.
- YOLOv9: The pretrained models for YOLOv9 are open-source and available on GitHub.
Why YOLOv7 is better than CNN in 2024 ?
Differences
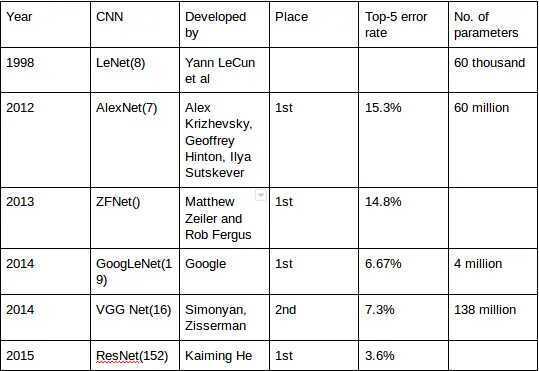
| Model name | Number of parameters (Millions) | ImageNet Top 1 Accuracy | Year |
|---|---|---|---|
| AlexNet | 60 M | 63.3 % | 2012 |
| Inception V1 | 5 M | 69.8 % | 2014 |
| VGG 16 | 138 M | 74.4 % | 2014 |
| VGG 19 | 144 M | 74.5 % | 2014 |
| Inception V2 | 11.2 M | 74.8 % | 2015 |
| ResNet-50 | 26 M | 77.15 % | 2015 |
| ResNet-152 | 60 M | 78.57 % | 2015 |
| Inception V3 | 27 M | 78.8 % | 2015 |
| DenseNet-121 | 8 M | 74.98 % | 2016 |
| DenseNet-264 | 22M | 77.85 % | 2016 |
| BiT-L (ResNet) | 928 M | 87.54 % | 2019 |
| NoisyStudent EfficientNet-L2 | 480 M | 88.4 % | 2020 |
| Meta Pseudo Labels | 480 M | 90.2 % | 2021 |
| CoCa (finetuned) | 2100M | 91.0% | 2022 |
| OmniVec (ViT) | 92.4% | 2023 |
Leaderboard - ImageNet Benchmark (Image Classification) | Papers With Code
Models - Models - Hugging Face
- CNN Architectures: LeNet, AlexNet, VGG, GoogLeNet, ResNet and more… | by Siddharth Das | Analytics Vidhya | Medium
- Difference between AlexNet, VGGNet, ResNet, and Inception | by Aqeel Anwar | Towards Data Science
Benefits of Pre-Trained Models for Image Classification
- Reduced Training Time: Pre-trained models significantly cut down on training time. Since they are already trained on large datasets, they only require fine-tuning for specific tasks. This efficiency allows developers to deploy models more quickly.
- Improved Accuracy: These models have been trained on vast amounts of data, enabling them to generalize well. As a result, they often achieve higher accuracy on various tasks compared to models trained from scratch. This leads to more reliable image classification results.
- Resource Efficiency: Using pre-trained models reduces the need for large datasets and computational power. Fine-tuning a pre-trained model requires fewer resources than training a new model, making it more accessible for organisations with limited resources.
Challenges of Pre-Trained Models for Image Classification
- Adaptability: Fine-tuning pre-trained models to fit specific tasks can be complex. Not all models adapt well to all tasks, and sometimes extensive tweaking is required to achieve optimal performance.
- Overfitting: There is a risk of overfitting, especially when fine-tuning on small datasets. The model might learn to perform well on the training data but fail to generalize to new, unseen data, reducing its effectiveness.
- Complexity: Some pre-trained models have intricate architectures that are difficult to implement and modify. This complexity can pose a barrier for developers who are not familiar with advanced neural network structures, potentially hindering their use.