Unlocking Analytics with DBT
Analytics engineering is the data transformation work that happens between loading data into your warehouse and analyzing it. dbt allows anyone comfortable with SQL to own that workflow.
With dbt, data teams work directly within the warehouse to produce trusted datasets for reporting, ML modeling, and operational workflows.
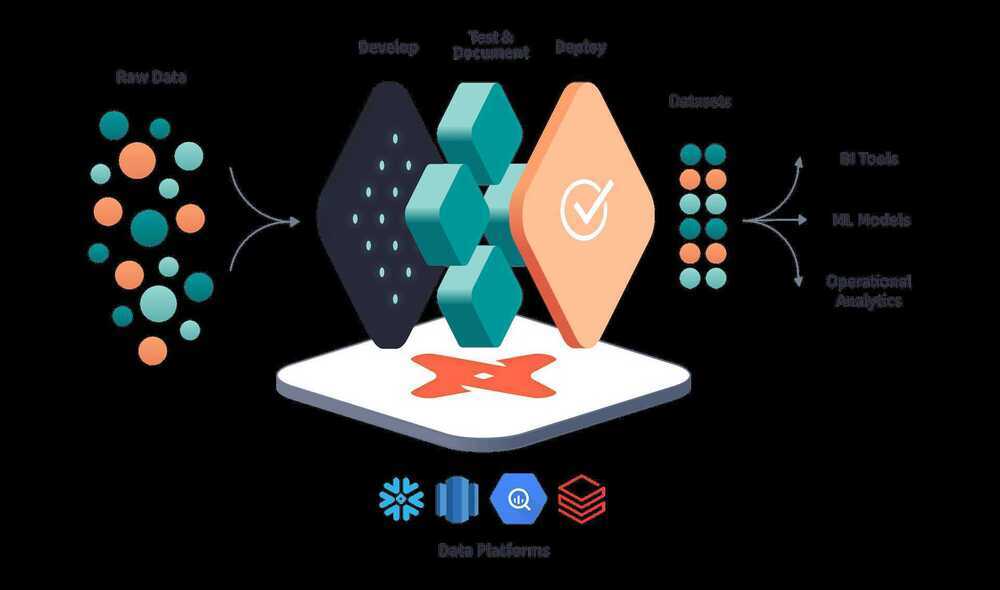
dbt is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone on the data team can safely contribute to production-grade data pipelines.
- https://www.getdbt.com
- What is dbt?
- What is Analytics Engineering?
- GitHub - dbt-labs/dbt-core: dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications. ⭐ 13k
- Setting Up dbt and Connecting to Snowflake
- How we structure our dbt projects | dbt Developer Hub
- Comparision
- dbt Core v2 is here: still open source, now rebuilt for what's next | dbt Developer Blog
What is DBT
Data Build Tool or dbt is built to transform data, and is therefore, the T in an ELT pipeline. I mentioned ELT because it is designed to work after data has been loaded, and is ready for transformation. Additionally, out of the box, it cannot connect with multiple databases, and depends on data that has been loaded, or otherwise accessible to the target database executing the dbt steps. Additionally, how dbt runs is that it executes SQL on the target database.
The utility of dbt that makes it superior to other approaches originates from the combination of Jinja templates with SQL, and re-usable components or models. For example, consider an online customer model, which is defined as a customer whose 50% or more sales are online:
WITH sales_by_type_cte as (
SELECT
customer_id,
SUM(CASE WHEN mode = 'online' THEN 1 ELSE 0 END) as online_sales,
COUNT(1) as total_sales
FROM {{ source('sales', 'sale') }}
GROUP BY customer_id
)
SELECT
c.id as identifier, c.first_name, c.last_name, c.country, c.region, c.address,
(s.online_sales / s.total_sales) * as online_sales_percent
FROM {{ source('sales', 'customer') }} c
JOIN sales_by_type_cte s
ON c.id = s.customer_id
WHERE (s.online_sales / s.total_sales) > 0.5
DBT Models
dbt models are files, typically in SQL or Python, that contain the logic to transform data in a data warehouse. They are written as SELECT statements in SQL and can be compiled into tables or views using different materialization strategies. dbt models enable modularity by breaking down complex transformations into logical, reusable steps and help build analytical data infrastructure by organizing transformation logic.
Key Characteristics
- Format: Most models are .sql files containing SELECT statements. Starting with dbt version 1.3, models can also be written in Python using return statements.
- Logic: Models define how raw source data is transformed, cleaned, and structured for analysis.
- Dependencies: Models are organized into a dependency graph, allowing dbt to run them in the correct order.
- Execution: When you run a dbt model, dbt wraps the SQL in the necessary Data Definition Language (DDL) to create a table or view in your data warehouse.
How They Work
- Write the Model: A developer writes a .sql or .py file in the /models/ directory of a dbt project.
- Compilation: dbt reads the model file and compiles it into a series of SQL statements.
- Materialization: dbt then executes these SQL statements against the data warehouse to create the defined database object (a table, view, or other materialization).
Types of Materializations
dbt provides different ways to persist your model's results:
- View: A query that runs every time the view is accessed.
- Table: A physical table stored in the data warehouse.
- Incremental: Appends or updates only new or changed data, rather than reprocessing the entire dataset, for efficiency.
- Ephemeral: A temporary object that doesn't persist in the warehouse.
Why Use dbt Models?
- Modularity: Break down complex transformations into smaller, manageable, and reusable units.
- Version Control: Manage transformation logic with other code, making it easier to collaborate and track changes.
- Documentation: Models serve as documentation, making the transformation logic clear to other team members.
- Efficiency: Use features like incremental models to significantly reduce processing time and costs.
Learning
- Getting Started with dbt (Data Build Tool): A Beginner’s Guide to Building Data Transformations | by Suffyan Asad | Medium
- GitHub - SA01/dbt-tutorial: This repository contains the code and project files for my article on Medium, which serves as an introduction to DBT (Data Build Tool) and how to build data transformations with it. ⭐ 7
- GitHub - lorint/AdventureWorks-for-Postgres: Set up the AdventureWorks sample database for use with Postgres ⭐ 478
- Ten years late to the dbt party (DuckDB edition)
Others
SQLMesh
SQLMesh is a next-generation data transformation framework designed to ship data quickly, efficiently, and without error. Data teams can run and deploy data transformations written in SQL or Python with visibility and control at any size.