Avro vs Protobuf: File Format Comparison
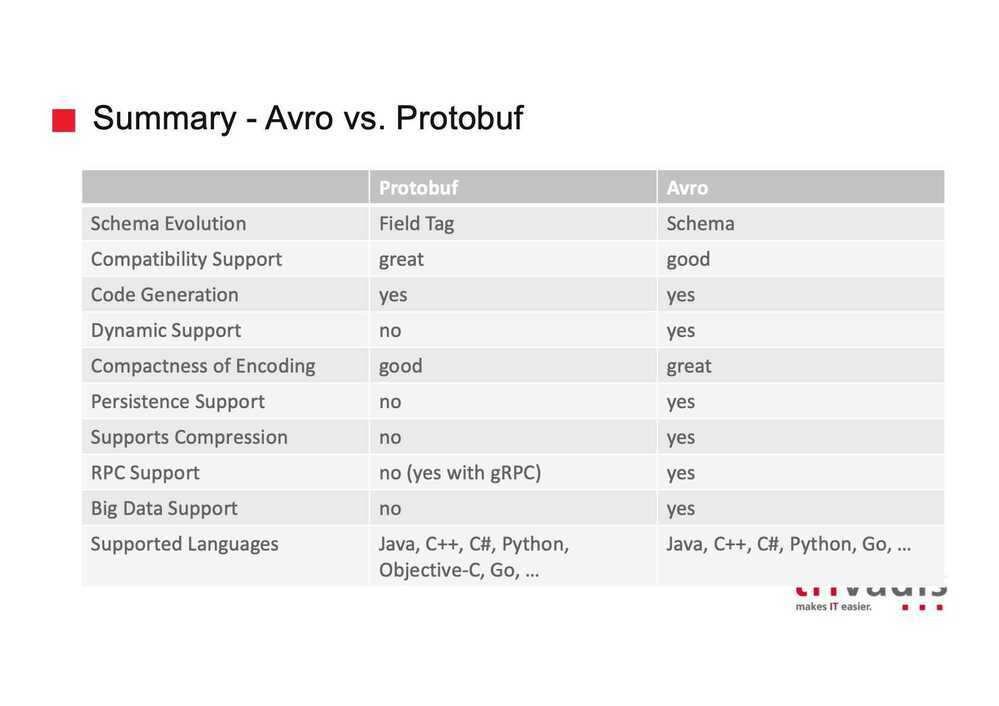
Avro vs Protobuf
What should you choose then? Avro, especially at the beginning, seems much easier to use. The cost of this is that you will need to provide both reader and writer schema to deserialize anything.
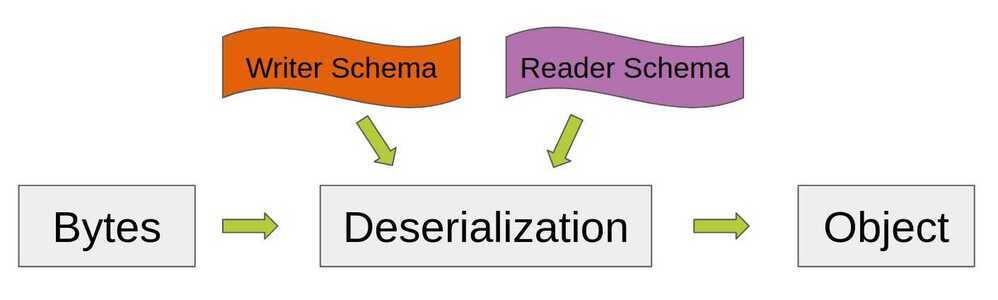
Sometimes this might be quite problematic. That's why tools like Schema Registry were developed.
The next problem you might face with Avro is the overall impact on your domain events. At some point, Avro can leak into your domain. Some constructions like e.g. a map with keys that are not strings are not supported in Avro model. When the serialization mechanism is forcing you to change something in your domain model - it's not a good sign.
With Protocol Buffers, schema management is much simpler - you just need schema artifact, which can be published as any other artifact to your local repository. Also, your domain can be perfectly separated from the serialization mechanism. The cost is the boilerplate code required for translation between domain and serialization layers.
Personally, I would use Avro for simple domains with mostly primitive types. For rich domains, with complex types and structures, I've been using Protocol Buffers for quite some time. Clean domain with no serialization influence is really worth paying the boilerplate code price.
https://blog.softwaremill.com/the-best-serialization-strategy-for-event-sourcing-9321c299632b
(Big) Data Serialization with Avro and Protobuf


















Big Data and Fast Data





Summary
Performance benchmarks
https://labs.criteo.com/2017/05/serialization
https://www.datanami.com/2018/05/16/big-data-file-formats-demystified
Parquet vs Avro
On their face, Avro and Parquet are similar they both write the schema of their enclosed data in a file header and deal well with schema drift (adding/removing columns). They're so similar in this respect that Parquet even natively supports Avro schemas ⭐ 3.1k, so you can migrate your Avro pipelines to Parquet storage in a pinch.
The big difference in the two formats is that Avro stores data BY ROW, and parquet stores data BY COLUMN..
BENEFITS OF PARQUET OVER AVRO
To recap on my columnar file format guide, the advantage to Parquet (and columnar file formats in general) are primarily two fold:
- Reduced Storage Costs (typically) vs Avro
- 10-100x improvement in reading data when you only need a few columns
I cannot overstate the benefit of a 100x improvement in record throughput. It provides a truly massive and fundamental improvement to data processing pipelines that it is very hard to overlook.
When simply counting rows, Parquet blows Avro away, thanks to the metadata parquet stores in the header of row groups.

When running a group-by query, parquet is still almost 2x faster (although I'm unsure of the exact query used here).

The same case study also finds improvements in storage space, and even in full-table scans, likely due to Spark having to scan a smaller datasize.
BENEFITS OF AVRO OVER PARQUET
I have heard some folks argue in favor of Avro vs Parquet. Such arguments are typically based around two points:
- When you are reading entire records at once, Avro wins in performance.
- Write-time is increased drastically for writing Parquet files vs Avro files
So the wider your dataset, the worse Parquet becomes for scanning entire records (which makes sense). This is an extreme example, most datasets are not 700 columns wide, for anything reasonable (< 100) Parquet read performance is close enough to Avro to not matter.
Others
https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html