Replication
Types
Streaming Replication
- Type: Asynchronous
- Method: Uses a continuous stream of write-ahead logs (WAL) from the primary server to the standby server(s).
- Data Transfer: Replicates entire database clusters at the block level.
- Failover: Generally used for read-only failover. Failover to a standby server in case the primary server fails.
- Consistency: Synchronous replication can be achieved by waiting for acknowledgments from the standby, ensuring transaction durability.
- Usage: Commonly used for high availability and disaster recovery.
Physical Replication
- Type: Synchronous or Asynchronous
- Method: Replicates physical blocks of data, similar to streaming replication, but allows for more flexibility in configuration.
- Data Transfer: Replicates entire data pages at the storage level.
- Failover: Primarily used for read-only failover, similar to streaming replication.
- Consistency: Can be synchronous, ensuring that a transaction is committed on both the primary and standby servers before returning to the client.
- Usage: Suitable for high availability, disaster recovery, and load balancing.
Logical Replication
- Type: Asynchronous
- Method: Replicates changes in the database on a logical level, such as tables, rows, or columns.
- Data Transfer: Replicates changes made to the data, providing more flexibility in what is replicated.
- Failover: Often used for upgrading databases with minimal downtime or for data distribution across different systems.
- Consistency: Typically asynchronous, so there might be some delay in data replication.
- Usage: Useful for selective data replication, upgrades, and data distribution.
Bi-Directional Replication (BDR)
- Type: Asynchronous
- Method: Replicates changes bidirectionally between nodes.
- Data Transfer: Allows for bidirectional replication of changes made to the data.
- Failover: Can be used for read and write failover, allowing writes on multiple nodes.
- Consistency: Asynchronous replication, so there might be some delay in data replication.
- Usage: Useful for multi-master setups where multiple nodes can accept both read and write operations. It enables data consistency across multiple nodes.
Streaming replication and physical replication are more focused on providing high availability and disaster recovery, while logical replication allows for more selective data replication. Bi-Directional Replication (BDR) is a specific implementation of multi-master replication, allowing for bidirectional data synchronization between nodes.
Bi-directional Replication (BDR)
PostgreSQL supports block-based (physical) replication as well as the row-based (logical) replication. Physical replication is traditionally used to create read-only replicas of a primary instance, and utilized in both self-managed and managed deployments of PostgreSQL. Uses for physical read replicas can include high availability, disaster recovery, and scaling out the reader nodes. Although there is flexibility in the use cases for physical replicas, consider that all data in the database must be replicated from the write instance to its readers.
In contrast, logical replication allows you to choose a subset of the data to replicate. Additionally, when using logical replication, there is no requirement for the secondary nodes to be read-only. You can configure logical replication to get data for some tables and at the same time, the application can directly write to the same or different tables in the database.
The publisher- and subscriber-based logical replication feature was introduced into core PostgreSQL starting with version 10, but prior to that, PostgreSQL started supporting the logical decoding feature from version 9.4. Much of the logical replication capability in core PostgreSQL was based on the work done for the open-source PostgreSQL logical replication extension called pglogical.
PostgreSQL bi-directional replication using pglogical | AWS Database Blog
PostgreSQL’s bidirectional replication (Postgres-BDR or BDR) is PostgreSQL’s first open-source multi-master replication system to achieve full production status. BDR was developed by 2ndQuadrant, specially designed for distribution in different geographical clusters, using efficient asynchronous logical replication, and supporting any node with more than 2 to 48 nodes in the distributed database.
EDB Docs - EDB Postgres Distributed (PGD) v4 - BDR (Bi-Directional Replication)
Converting from Asynchronous to Synchronous Replication in PostgreSQL | Severalnines
PostgreSQL: Software Catalogue - Clustering/replication
Multiple Masters to Single Slave (Multi-Source Replication)
Multi-Source Replication enables a replication slave to receive transactions from multiple sources simultaneously. Multi-source replication can be used to backup multiple servers to a single server, to merge table shards, and consolidate data from multiple servers to a single server.
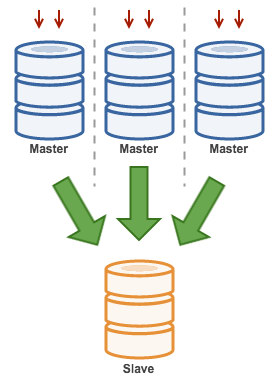
MySQL and MariaDB have different implementations of multi-source replication, where MariaDB must have GTID with gtid-domain-id configured to distinguish the originating transactions while MySQL uses a separate replication channel for each master the slave replicates from. In MySQL, masters in a multi-source replication topology can be configured to use either global transaction identifier (GTID) based replication, or binary log position-based replication.
MySQL replication for high availability | Severalnines
MySQL 8.0 Reference Manual - 19.1.5 MySQL Multi-Source Replication
The Difference Between MySQL Multi-Master and Multi-Source Replication | Severalnines
Dump and Restore
PostgreSQL: improving pg_dump, pg_restore performance - Stack Overflow
pg dump - Postgresql 13 - Speed up pg_dump to 5 minutes instead of 70 minutes - Server Fault
Speeding up Postgres Data Dumps
PostgreSQL: Documentation: 17: 25.3. Continuous Archiving and Point-in-Time Recovery (PITR)
Replication Slot
A PostgreSQL replication slot is a vital feature ensuring the master server retains necessary Write-Ahead Log (WAL) files, even when replicas are temporarily disconnected. In streaming replication scenarios with hot or archiving standbys, replication slots preserve WAL files, allowing the master to track standby lag. When a standby reconnects, preserved WAL files are decoded and applied.
PostgreSQL Replication slots are of two types:
- Physical PostgreSQL Replication Slots
- Logical PostgreSQL Replication Slots
1. Physical PostgreSQL Replication Slots
The changes that take place on the main server via streaming replication are recorded in the WAL segments. These WAL files are sent to the standby server and then replayed.
So, a physical replication slot can be created on the primary server, and the location to which the transactions are sent is stored on the standby. Now, if the standby loses connection, the primary server will keep those WAL files.
2. Logical PostgreSQL Replication Slots
Logical replication was introduced in PostgreSQL 10. Logical replication brings over only the SQL-like changes. It does not work without replication slots. Logical replication data has to be decoded using a plugin.
-- Monitor Postgres Replication Slots
select * from pg_replication_slots;
-- Drop Replication Slot
select pg_drop_replication_slot(‘ocean’);
Working with PostgreSQL Replication Slots: Simplified Guide
Links
- 26. High Availability, Load Balancing, and Replication
- 30. Logical Replication
- 49. Replication Progress Tracking
- EDB failover manager (EFM) for managing streaming replication - DBACLASS DBACLASS
- Difference between PostgreSQL and MySQL: (1) Replication · Hironobu SUZUKI @ InterDB
- Replicate data between partitioned and non-partitioned tables using trigger functions in Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL | AWS Database Blog