Scaling / Optimizations
What exactly needs to Scale?
-
Tables (Data)
- Partitioning, Co-location, Reference Tables
-
SQL (Reads)
- How do we express and optimze distributed SQL
-
Transactions (Writes)
- Cross Shared updates/deletes, Global Atomic Transactions
Able to search ~5cr entries in 7 mins of average time with 4-5 where conditions
Strategies
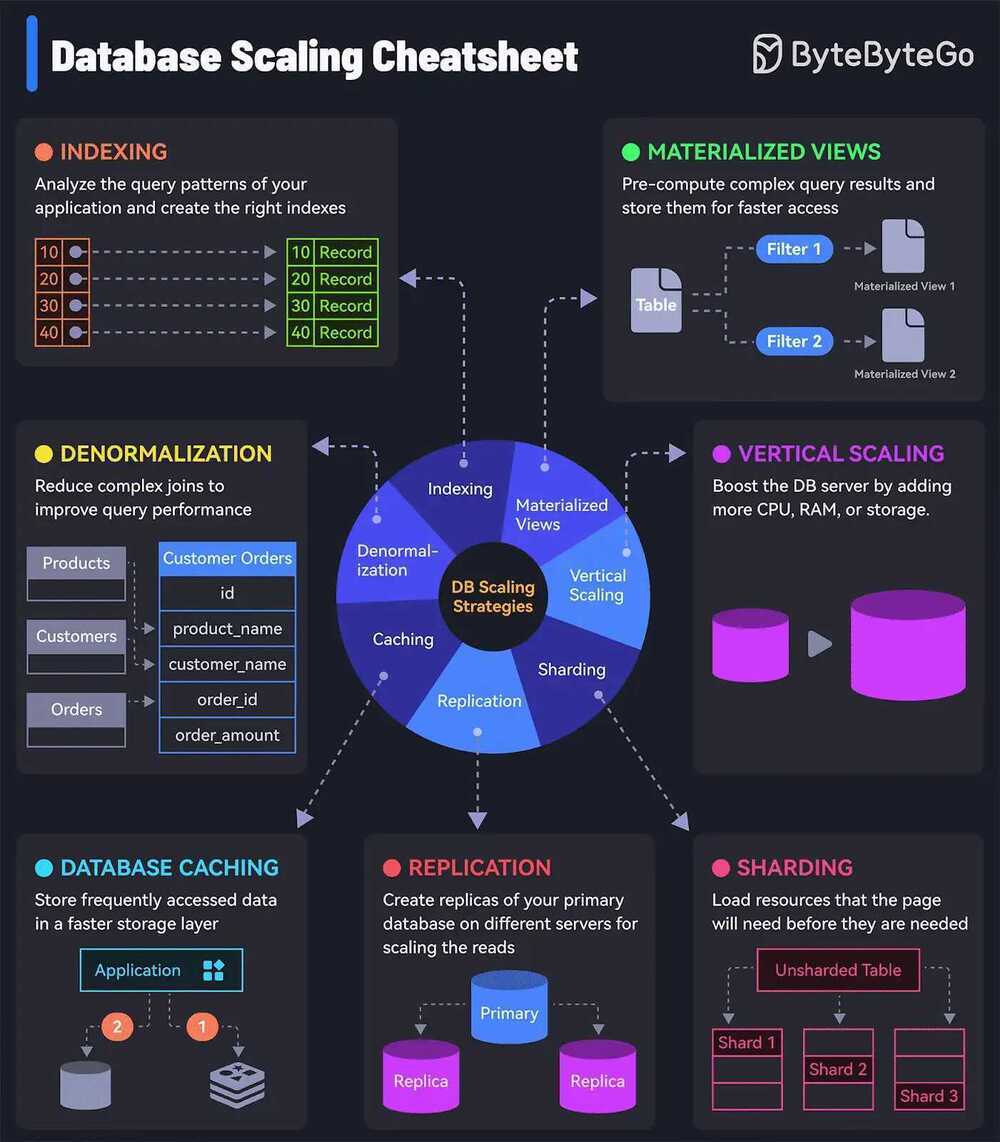
7 must-know strategies to scale your database.
- Indexing - Check the query patterns of your application and create the right indexes.
- Materialized Views - Pre-compute complex query results and store them for faster access.
- Denormalization - Reduce complex joins to improve query performance.
- Vertical Scaling - Boost your database server by adding more CPU, RAM, or storage.
- Caching - Store frequently accessed data in a faster storage layer to reduce database load.
- Replication - Create replicas of your primary database on different servers for scaling the reads.
- Sharding - Split your database tables into smaller pieces and spread them across servers. Used for scaling the writes as well as the reads.
Data Partitioning
-
Horizontal Partitioning
-
Vertical Partitioning
-
Pick a column
- Date
- Id (customer_id, card_id)
-
Pick a method
- Hash
- Range
Limitations
- ALTER TABLE ... ORDER BY. An ALTER TABLE ... ORDER BY column statement run against a partitioned table causes ordering of rows only within each partition.
- Prohibited constructs.The following constructs are not permitted in partitioning expressions:
- Stored procedures, stored functions, UDFs, or plugins.
- Declared variables or user variables.
- The query cache is not supported for partitioned tables, and is automatically disabled for queries involving partitioned tables. The query cache cannot be enabled for such queries.
- Partitioned tables using the InnoDB storage engine do not support foreign keys. More specifically, this means that the following two statements are true:
- No definition of an InnoDB table employing user-defined partitioning may contain foreign key references; no InnoDB table whose definition contains foreign key references may be partitioned.
- No InnoDB table definition may contain a foreign key reference to a user-partitioned table; no InnoDB table with user-defined partitioning may contain columns referenced by foreign keys.
https://dev.mysql.com/doc/mysql-partitioning-excerpt/5.7/en/partitioning-limitations.html
Replication
MySQL Replication Tutorial - YouTube
Performance Tuning
- Often the default value is the best value
- Ensure all tables have a PRIMARY KEY
- InnoDB organizes the data according to the PRIMARY KEY:
- The PRIMARY KEY is included in all secondary indexes in order to be able to locate the actual row
- Smaller PRIMARY KEY gives smaller secondary indexes
- A mostly sequential PRIMARY KEY is generally recommended to avoid inserting rows between existing rows
max_execution_timelimit for long running SQL Queries
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
Optimizations
Always do bulk inserts/updates wherever possible
if autoincrement is used, then for every query there is roundtrip to database to check the autoincrement value, so use bulk insert if possible
Explicitly ORDER BY After GROUP BY
By default, the database sorts all 'GROUP BY col1, col2, ...' queries as if you specified 'ORDER BY col1, col2, ...' in the query as well. If a query includes a GROUP BY clause but you want to avoid the overhead of sorting the result, you can suppress sorting by specifying 'ORDER BY NULL'.
SELECT age, COUNT(*) FROM employees WHERE age > 50
GROUP BY age **ORDER BY NULL;**
Instead of:
SELECT age, COUNT(*) FROM employees WHERE age > 50
GROUP BY age;
Avoid Comparing Columns From Different Types
Joining or filtering using columns of different types/lengths/signedness in the same condition may cause performance degradation. The database will have to perform a cast for each of these values before performing the comparison, which may also prevent the use of an index for these columns. Make sure to alter the column types so that common comparisons will be done between two columns of the same type
Avoid Correlated Subqueries
A correlated subquery is a subquery that contains a reference (column: loan_id) to a table that also appears in the outer query. Usually correlated queries can be rewritten with a join clause, which is the best practice. The database optimizer handles joins much better than correlated subqueries. Therefore, rephrasing the query with a join will allow the optimizer to use the most efficient execution plan for the query
Avoid Subqueries
We advise against using subqueries as they are not optimized well by the optimizer. Therefore, it's recommended to join a newly created temporary table that holds the data, which also includes the relevant search index
Use UNION ALL instead of UNION
Always use UNION ALL unless you need to eliminate duplicate records. By using UNION ALL, you'll avoid the expensive distinct operation the database applies when using a UNION clause
The LOAD DATA INFILE statement reads rows from a text file into a table at a very high speed
ANALYZE TABLE payments;
OPTIMIZE TABLE table_name;
CHECK TABLE table_name;
REPAIR TABLE table_name;
https://www.mysqltutorial.org/mysql-database-table-maintenance-statements.aspx
Defragmentation
OPTIMIZE TABLE sttash_website_LIVE.email_instance_moratorium;
During optimization, MySQL will create a temporary table for the table, and after the optimization it will delete the original table, and rename this temporary table to the original table.
You can use OPTIMIZE TABLE to reclaim the unused space and to defragment the data file. After extensive changes to a table, this statement may also improve performance of statements that use the table, sometimes significantly.
This statement requires SELECT and INSERT privileges for the table.
https://www.thegeekstuff.com/2016/04/mysql-optimize-table
https://dev.mysql.com/doc/refman/8.0/en/optimize-table.html
The Impacts of Fragmentation in MySQL
In MySQL RDS 8.0.36 this doesn't lock the tables
Optimizing data size
Table Columns
- Use the most efficient (smallest) data types possible. MySQL has many specialized types that save disk space and memory. For example, use the smaller integer types if possible to get smaller tables.MEDIUMINT is often a better choice than INT because a MEDIUMINT column uses 25% less space.
- Declare columns to beNOT NULLif possible. It makes SQL operations faster, by enabling better use of indexes and eliminating overhead for testing whether each value isNULL. You also save some storage space, one bit per column. If you really needNULLvalues in your tables, use them. Just avoid the default setting that allowsNULLvalues in every column.
Row Format
Indexes
- The primary index of a table should be as short as possible. This makes identification of each row easy and efficient. ForInnoDBtables, the primary key columns are duplicated in each secondary index entry, so a short primary key saves considerable space if you have many secondary indexes.
- Create only the indexes that you need to improve query performance. Indexes are good for retrieval, but slow down insert and update operations. If you access a table mostly by searching on a combination of columns, create a single composite index on them rather than a separate index for each column. The first part of the index should be the column most used. If youalwaysuse many columns when selecting from the table, the first column in the index should be the one with the most duplicates, to obtain better compression of the index.
- If it is very likely that a long string column has a unique prefix on the first number of characters, it is better to index only this prefix, using MySQL's support for creating an index on the leftmost part of the column. Shorter indexes are faster, not only because they require less disk space, but because they also give you more hits in the index cache, and thus fewer disk seeks
Joins
- In some circumstances, it can be beneficial to split into two a table that is scanned very often. This is especially true if it is a dynamic-format table and it is possible to use a smaller static format table that can be used to find the relevant rows when scanning the table.
- Declare columns with identical information in different tables with identical data types, to speed up joins based on the corresponding columns.
- Keep column names simple, so that you can use the same name across different tables and simplify join queries. For example, in a table namedcustomer, use a column name ofnameinstead ofcustomer_name. To make your names portable to other SQL servers, consider keeping them shorter than 18 characters.
Normalization
- Normally, try to keep all data nonredundant (observing what is referred to in database theory asthird normal form). Instead of repeating lengthy values such as names and addresses, assign them unique IDs, repeat these IDs as needed across multiple smaller tables, and join the tables in queries by referencing the IDs in the join clause.
- If speed is more important than disk space and the maintenance costs of keeping multiple copies of data, for example in a business intelligence scenario where you analyze all the data from large tables, you can relax the normalization rules, duplicating information or creating summary tables to gain more speed.
https://dev.mysql.com/doc/refman/8.0/en/data-size.html
SQL Server Performance Essentials -- Full Course
Others
Building and deploying MySQL Raft at Meta - Engineering at Meta