Configurations / Optimizations / Best Practices
Database Configuration
There are two types of Aurora MySQL parameter groups: DB parameter groups and DB cluster parameter groups. Some parameters affect the configuration for an entire DB cluster, like binary log format, time zone, and character set defaults. Others limit their scope to a single DB instance.
Key Performance Indicators
- CPU utilization
- Number of database connections
- Memory utilization
- Cache hit rates
- Query throughput
- Latency
Classifying Parameters
- Parameters that control the database's behavior and functionality but have no impact on resource utilization and instance stability
- Parameters that might affect performance by managing how resources, such as caching and internal memory-based buffers, are allocated in the instance
Others
- innodb_additional_mem_pool_size
- innodb_log_buffer_size
- long_query_time
- server_audit_events
- server_audit_excl_users - Wildcard - %test%
- server_audit_incl_users
Commands
call mysql.rds_show_configuration;
call mysql.rds_set_configuration('binlog retention hours', 24);
Recommendations and impact
autocommit
Recommended setting: Use the default value (1 or ON) to ensure that each SQL statement is automatically committed as you run it, unless it's part of a transaction opened by the user.
Impact: A value of OFF might encourage incorrect usage patterns such as transactions that are held open longer than required, not closed, or committed at all. This can affect the performance and stability of the database.
max_connections
Recommended setting: Default (variable value). When using a custom value, configure only as many connections as the application actively uses to perform work.
Impact:Configuring a too-high connection limit can contribute to higher memory use even if connections are not actively used. It can also cause high database connection spikes that affect the databases' performance and stability.
This variable parameter is automatically populated based on your instance's memory allocation and size using the following formula, so use the default value first:
GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000})
For example, for an Aurora MySQL db.r4.large instance with 15.25 GiB of memory, it is set to 1,000:
DBInstanceClassMemory = 16374562816 bytes
max_connections = GREATEST({log(16374562816/805306368,2)*45},{log(16374562816/8187281408,2)*1000})
max_connections = GREATEST(195.56,1000) = 1000
If you are encountering connection errors and getting excessiveToo many connectionsin your error logs, you can set this parameter to a fixed value instead of the variable setting.
When you're considering settingmax_connectionsto a fixed value if your application requires a higher number of connections, consider using a connection pool or proxy between the application and the database. You can also do this if connections can't be predicted or controlled reliably.
When you manually configure a value for this parameter that exceeds the recommended number of connections, Amazon CloudWatch metrics for DB connections show a red line where the threshold is exceeded. This is the formula that CloudWatch uses:
Threshold value for max_connections = {DBInstanceClassMemory/12582880}
For example, for a db.r4.large instance whose memory size is 15.25 GiB (15.25 x 1024 x 1024 x 1024 = 16374562816 bytes), the warning threshold is approximately 1,300 connections. You can still use the maximum number of configured connections, provided that there are enough resources on the instance.
max_allowed_packet
Recommended setting: Default (4,194,304 bytes). Use a custom value only if required by your database workload. Tune this parameter when you are dealing with queries returning large elements, like long strings or BLOBs.
Impact:Setting a large value here doesn't affect the initial size of the message buffers. Instead, it allows them to grow up to the defined size if required by your queries. A large parameter value coupled with a large number of concurrent eligible queries can increase the risk of out-of-memory conditions.
The following example error is shown when setting this parameter too small:
ERROR 1153 (08S01) at line 3: Got a packet bigger than 'max_allowed_packet' bytes
group_concat_max_len
Recommended setting: Default (1,024 bytes). Use a custom value only if your workload requires it. You need to tune this parameter only when you want to alter the return of theGROUP_CONCAT()statement and allow the engine to return longer column values. This value should be used in parallel withmax_allowed_packet, as this determines the maximum size of a response.
Impact:Some of the symptoms of setting this parameter too high are high memory use and out-of-memory conditions. Setting it too low causes queries to fail.
innodb_ft_result_cache_limit
Recommended setting: Default (2,000,000,000 bytes). Use a custom value depending on your workload.
Impact:As the value is already close to 1.9 GiB, increasing it beyond its default can result in out-of-memory conditions.
max_heap_table_size
Recommended setting: Default (16,777,216 bytes). Limits the maximum size of tables created in memory as defined by a user. Altering this value only has effect on newly created tables, and doesn't affect existing ones.
Impact:Setting this parameter too high causes high memory utilization or out-of-memory conditions if in-memory tables grow.
performance_schema
Recommended setting: Disable for t2 instances due to its high memory utilization.
Impact:In Aurora MySQL 5.6, Performance Schema memory is preallocated heuristically. This preallocation is based on other configuration parameters such asmax_connections, table_open_cache, andtable_definition_cache. In Aurora MySQL 5.7, Performance Schema memory is allocated on-demand. The Performance Schema typically consumes around 1 to 3 GB of memory depending on the instance class, workload, and database configuration. If a DB instance is running low on memory, enabling Performance Schema can lead to out-of-memory conditions.
binlog_cache_size
Recommended setting: Default (32,768 bytes). This parameter controls the amount of memory that the binary log cache can use. By increasing it, you can improve performance on systems with large transactions by using buffers to avoid excessive disk writes. This cache is allocated on a per connection basis.
Impact:Limit this value in environments with a large number of DB connections to avoid causing an out-of-memory condition.
bulk_insert_buffer_size
Recommended setting: Leave as is, because it doesn't apply to Aurora MySQL.
innodb_buffer_pool_size
Recommended setting: Default (variable value), as it is preconfigured in Aurora to 75 percent of instance memory size. You can see buffer pool use in the output of SHOW ENGINE INNODB STATUS.
Impact: A larger buffer pool improves overall performance by allowing less disk I/O when accessing the same table data repeatedly. The actual amount of allocated memory might be slightly higher than the actual configured value due to InnoDB engine overhead.
InnoDB Buffer Pool Resizing: Chunk Change
innodb_sort_buffer_size
Recommended setting: Default (1,048,576 bytes)
Impact:Higher-than-default values can increase the overall memory pressure on systems with a large number of concurrent queries
join_buffer_size
Recommended setting: Default (262,144 bytes). This value is preallocated for various types of operations (such as joins) and a single query may allocate multiple instances of this buffer. If you want to improve the performance of your joins, we recommend that you add indexes to such tables.
Impact:Changing this parameter can cause severe memory pressure in environments with a large number of concurrent queries. Increasing this value doesn't provide faster JOIN query performance, even when you add indexes.
key_buffer_size
Recommended setting: Leave as the default value (16,777,216 bytes), because it is not relevant to Aurora and affects only MyISAM table performance.
Impact:No impact on Aurora's performance.
myisam_sort_buffer_size
Recommended setting: Leave as the default value (8,388,608 bytes). It's not applicable for Aurora because it has no effect on InnoDB.
Impact:No impact on Aurora's performance.
innodb_flush_method
In MySQL InnoDB, background tasks like flushing dirty pages from the buffer pool to disk are crucial for maintaining database performance and integrity. Understanding and configuring the innodb_flush_method system variable can significantly impact your database’s efficiency, especially under heavy write loads. Here’s a breakdown of the different flush methods and recommendations for tuning them according to your needs.
-
fsync (Default): Operation: Flushes data, metadata, and log files. Consideration: Can lead to double buffering.
-
O_DSYNC: Operation: Flushes only data files, still causes double buffering.
-
O_DIRECT: Operation: Flushes only data files, uses fsync without double buffering. Benefit: Direct read/write operations go directly to disk, bypassing OS cache.
-
O_DIRECT_NO_FSYNC: Operation: Similar to O_DIRECT but skips fsync. Caution: Not recommended for XFS file systems due to potential integrity issues.
Recommendations
Heavy Write Workloads: Opt for O_DIRECT_NO_FSYNC to minimize the overhead caused by double buffering and fsync operations.
General Use: Either O_DIRECT or O_DIRECT_NO_FSYNC can be effective. Evaluate based on your specific workload and file system compatibility (avoid O_DIRECT_NO_FSYNC on XFS).
Query Cache
Aurora has two query-cache related metrics
- Buffer cache hit ratio : The percentage of requests that are served by the Buffer cache.
- Resultset cache hit ratio : The percentage of requests that are served by the Resultset cache.
"Resultset Cache Hit Ratio" is related to the query cache, which is a feature that enables caching the read queries' results (that's why called result set cache hit). So, if the engine started to execute a new read query, it will check the cached results before executing the query itself and if it found that this same query has been executed before and that its result wasn't invalidated yet, then it will serve the result of the new query from the cache. This is generally useful & shows up high in number when the workload contains a lot of similar select queries that has the similar values and conditions.
On the other hand, "Buffer Cache Hit Ratio" is more related to the innodb page caching hit ratio (& not the query result cache), and this should increase with increasing all types of read queries, as this process is called by bufferpool warm up which will cause the engine to load all the needed pages from the storage to the memory for faster access to the data. However, with increased amount of writes to the writer, this will make the readers to invalidate there in memory pages then load these pages again from the storage when needed. The "ratio" here depends on the percentage of hitting the in memory pages which should be very high ex: more than 99%.
Query cache is generally considered with low connections, similar type of queries over & over again (based on few observations on mysql/aurora, query cache might be actually bad for performance if you have high no. of connections & lots of adhoc style, changing queries).- It is rarely good to enable the Query Cache
-
Guarded by a single mutext
-
Most workloads is best left with the Query Cache disabled:
- query_cache_type = 0
-
If you think your workload benefits from the Query Cache, test it
- The more writes, the less benefit
- The more data fitting into the buffer pool, the less benefit
- The more complex queries and the larger scans, the more benefit
-
Often other caching solutions are a better option
Removed in MySQL 8.0
http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Aurora.Monitoring.html
query_cache_size
Recommended setting: Default (variable value). The parameter is pretuned in Aurora, and the value is much larger than MySQL default. Aurora's query cache doesn't suffer from scalability issues (as the query cache does in MySQL). It's an acceptable practice to modify it for high-throughput, demanding workloads.
Impact:Query performance is affected when accessing queries through this cache. You can see query cache use in the output of a SHOW STATUS command under the "QCache" section.
query_cache_type
Recommended setting: Enabled. By default, the query cache is enabled in Aurora and is recommended to keep it enabled for its performance gains and low overhead. However, it's fine to disable the query cache if you know that your workload doesn't benefit from it. An example is a write-heavy workload with limited to no read queries.
Impact:Disabling query caching in Aurora might affect database performance if your workload reuses queries, like repeatable SQL statements. You can see query cache use in the output of a SHOW STATUS command under the "Qcache" section.
read_buffer_size
Recommended setting: Default (262,144 bytes).
Impact:Large values cause higher overall memory pressure and provoke out-of-memory issues. Don't increase the setting unless you can prove that the higher value benefits performance without compromising stability.
read_rnd_buffer_size
Recommended setting: Default (524,288 bytes). There's no need to increase the setting for Aurora, due to the performance characteristics of the underlying storage cluster.
Impact:Large values might cause out-of-memory issues.
table_open_cache
Recommended setting: Leave as is, unless your workload requires accessing a very large number of tables simultaneously. The table cache is a major memory consumer, and the default value in Aurora is significantly higher than the MySQL defaults. This parameter is automatically adjusted based on instance size.
Impact:A database with a large number of tables (in the hundreds of thousands) requires a larger setting, because not all tables fit in memory. Setting this value too high might contribute to out of memory conditions. This setting also indirectly contributes to Performance Schema memory usage, if the Performance Schema is enabled.
table_definition_cache
Recommended settings: Defaults. This setting is pretuned in Aurora to be significantly larger than in MySQL, and it's automatically adjusted based on instance size and class. If your workload requires it and your database requires a very large number of tables to be opened concurrently, increasing this value might speed up opening tables operations. This parameter is used in conjunction with table_open_cache.
Impact:This setting also indirectly contributes to Performance Schema memory usage, if the Performance Schema is enabled. Watch out for higher-than-default settings as they might provoke out-of-memory issues.
tmp_table_size
Recommended settings: Default (16,777,216 bytes). Together withmax_heap_table_size, this parameter limits the size for in-memory tables used for query processing. When the temporary table size limit is exceeded, tables are then swapped to disk.
Impact:Very large values (hundreds of megabytes or more) are notorious for causing memory issues and out-of-memory errors. This parameter doesn't affect tables created with the MEMORY engine.
https://aws.amazon.com/blogs/database/best-practices-for-amazon-aurora-mysql-database-configuration
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithParamGroups.html
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Reference.html
Others
- require_secure_transport
- mysqlx_max_connections
Optimizations
Aurora IO Costs/Optimization
Read I/O Cost Optimization
- Tune SQL queries to optimize read operations and avoid full scans on large tables.
- Scale DB Instance when needed to optimize buffer cache for reads (monitor CloudWatch metrics Buffer Cache Hit Ratio (Percent)).
- Tune autovacuum process on Aurora PostgreSQL for tables with high DML operations to avoid bloated table/index access.
- Use Aurora native backup and snapshots when possible. Logical backups (mysqldump, pg_dump) will generate excessive reads.
- Use Aurora native replication (Aurora replicas) when possible. Avoid logical replication (binlog WAL based) which uses additional read I/Os.
Write I/O Cost Optimization
- Remove unused or duplicate indexes from tables.
- Make use of appropriate fill factor so HOT (Heap Only Tuple) updates can be used in Aurora PostgreSQL.
- Utilize Table partitioning to manage large tables and use partition drops instead of large DELETE operations.
- Use Aurora native replication (read replicas) when possible. Avoid logical replication (binlog WAL based) which uses additional write I/Os.
Amazon Aurora I/O Cost Optimization Methodology | Amazon Web Services
select * from sys.user_summary_by_file_io;
innodb_flush_log_at_trx_commit
innodb_flush_log_at_timeout
Aurora I/O Optimized Databases
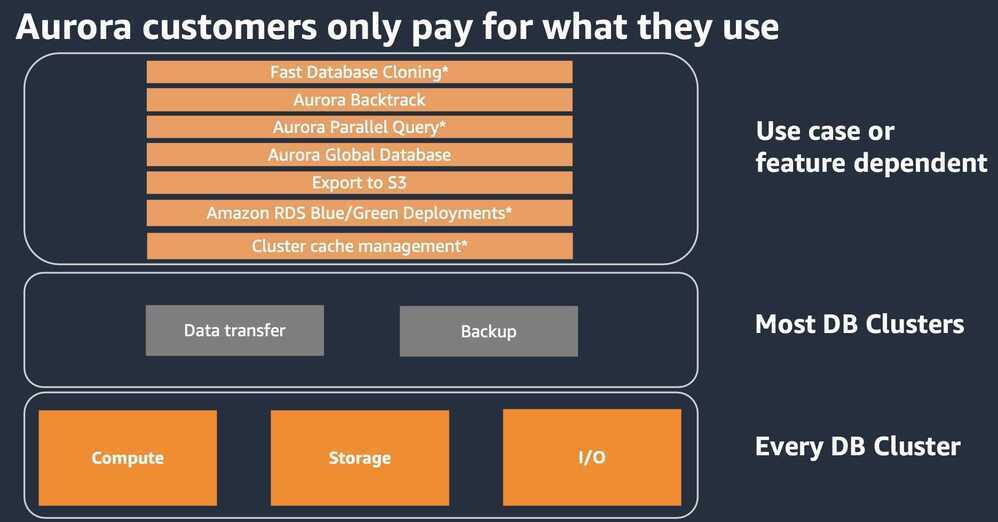
- Aurora cluster configuration with the option to pay for compute and storage only with no charges for read and write I/O operations
- Price predictability: no pay-per-request I/O charges making it easy to estimate database spend upfront
- For customers whose I/O spend exceeds 25% of total Aurora database spend, customers can save up to 40% cost savings
- Improved performance: increasing throughput and reducing latency for I/O-intensive applications
- Available for Aurora PostgreSQL-Compatible Edition and Aurora MySQL-Compatible Edition
- Supported on Aurora Serverless v2 and provisioned (on-demand and reserved) instances
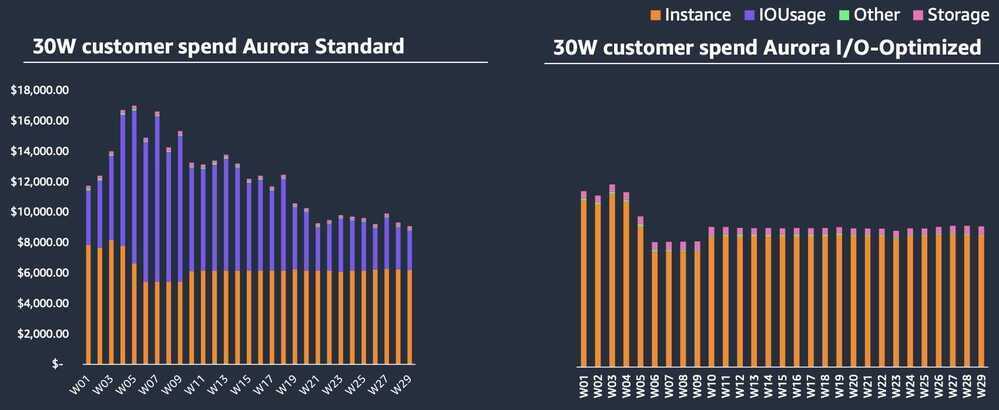
Pricing
- Compute (On-demand / RI) + 30%
- Storage (Standard – pay-per-use) + 125%
- I/O – No additional charges for read and write I/Os (not applicable for Aurora Global DB)
- Other cost components
I/O-Optimized can be configured at a cluster level
- Aurora I/O-Optimized is a cluster storage configuration
- Aurora cluster can modify storage option (standard to I/O-Optimized) once in a month and switch back anytime
- Available from Aurora PostgreSQL 13.x and Aurora MySQL 3.0.3.1 onwards
- Compatible with
- Intel-based Aurora database instance types such as t3, r5, r6i
- Graviton-based database instance types such as t4g, r6g, r7g, and x2g
- Aurora Serverless v2
- Aurora Global database cluster can have different Aurora storage config at cluster level i.e. primary & secondary clusters can configure with different configuration
Getting Started with Amazon Aurora I/O-Optimized - AWS Databases in 15 - YouTube
AWS announces Amazon Aurora I/O-Optimized
Binlog
- Configuring Aurora MySQL binary logging - Amazon Aurora
- Schedule Amazon RDS MySQL DB instance binlog file uploads to Amazon S3 | AWS re:Post
- Binary logging optimizations in Amazon Aurora MySQL version 3 | AWS Database Blog
DB instance RAM recommendations
An Amazon RDS performance best practice is to allocate enough RAM so that yourworking setresides almost completely in memory. The working set is the data and indexes that are frequently in use on your instance. The more you use the DB instance, the more the working set will grow.
To tell if your working set is almost all in memory, check the ReadIOPS metric (using Amazon CloudWatch) while the DB instance is under load. The value of ReadIOPS should be small and stable. If scaling up the DB instance class - to a class with more RAM - results in a dramatic drop in ReadIOPS, your working set was not almost completely in memory. Continue to scale up until ReadIOPS no longer drops dramatically after a scaling operation, or ReadIOPS is reduced to a very small amount. For information on monitoring a DB instance's metrics, see Viewing DB instance metrics.
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_BestPractices.html
https://aws.amazon.com/premiumsupport/knowledge-center/rds-instance-high-cpu
Wait Events
https://aws.amazon.com/premiumsupport/knowledge-center/aurora-mysql-synch-wait-events
RDS Proxy
https://aws.amazon.com/rds/proxy