Understanding Database Indexing
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
An index is a copy of selected columns of data from a table that can be searched very efficiently that also includes a low-level disk block address or direct link to the complete row of data it was copied from. Some databases extend the power of indexing by letting developers create indexes on functions or expressions. For example, an index could be created on upper(last_name), which would only store the upper-case versions of the last_name field in the index. Another option sometimes supported is the use of partial indices, where index entries are created only for those records that satisfy some conditional expression. A further aspect of flexibility is to permit indexing on user-defined functions, as well as expressions formed from an assortment of built-in functions.
Types of indexes
Bitmap index
A bitmap index is a special kind of indexing that stores the bulk of its data as bit arrays (bitmaps) and answers most queries by performing bitwise logical operations on these bitmaps. The most commonly used indexes, such as B+ trees, are most efficient if the values they index do not repeat or repeat a small number of times. In contrast, the bitmap index is designed for cases where the values of a variable repeat very frequently. For example, the sex field in a customer database usually contains at most three distinct values: male, female or unknown (not recorded). For such variables, the bitmap index can have a significant performance advantage over the commonly used trees.
Dense index
A dense index in databases is a file with pairs of keys and pointers for every record in the data file. Every key in this file is associated with a particular pointer toa recordin the sorted data file. In clustered indices with duplicate keys, the dense index pointsto the first recordwith that key.
Sparse index
A sparse index in databases is a file with pairs of keys and pointers for every block in the data file. Every key in this file is associated with a particular pointerto the blockin the sorted data file. In clustered indices with duplicate keys, the sparse index pointsto the lowest search keyin each block.
Reverse index
A reverse-key index reverses the key value before entering it in the index. E.g., the value 24538 becomes 83542 in the index. Reversing the key value is particularly useful for indexing data such as sequence numbers, where new key values monotonically increase. It is an index of keywords that stores records of documents that contain keywords in the list.
Use Case - Create a complete Tweet index.
https://en.wikipedia.org/wiki/Database_index
Partial Index
A partial index can save space by specifying which values get indexed.
A partial index is an index built over a subset of a table; the subset is defined by a conditional expression (called the predicate of the partial index). The index contains entries only for those table rows that satisfy the predicate. Partial indexes are a specialized feature, but there are several situations in which they are useful.
One major reason for using a partial index is to avoid indexing common values. Since a query searching for a common value (one that accounts for more than a few percent of all the table rows) will not use the index anyway, there is no point in keeping those rows in the index at all. This reduces the size of the index, which will speed up those queries that do use the index. It will also speed up many table update operations because the index does not need to be updated in all cases.
CREATE INDEX orders_completed_user_id
ON orders (user_id)
WHERE completed IS TRUE;
https://www.postgresql.org/docs/12/indexes-partial.html
How Instagram efficiently serves HashTags ordered by count - YouTube
Tips
- B Tree / B+ Tree index is not good for columns with low cardinality (since it's create a full tree for the columns)
- BitMap index is good for low cardinality columns
Index Data Structures
Search engine architectures vary in the way indexing is performed and in methods of index storage to meet the various design factors.
Suffix tree
Figuratively structured like a tree, supports linear time lookup. Built by storing the suffixes of words. The suffix tree is a type of trie. Tries support extendible hashing, which is important for search engine indexing.Used for searching for patterns in DNA sequences and clustering. A major drawback is that storing a word in the tree may require space beyond that required to store the word itself.An alternate representation is a suffix array, which is considered to require less virtual memory and supports data compression such as the BWT algorithm.
Inverted index
Stores a list of occurrences of each atomic search criterion, typically in the form of a hash table or binary tree.
Citation index
Stores citations or hyperlinks between documents to support citation analysis, a subject of bibliometrics.
Ngram index
Stores sequences of length of data to support other types of retrieval or text mining.
Document-term matrix
Used in latent semantic analysis, stores the occurrences of words in documents in a two-dimensional sparse matrix.
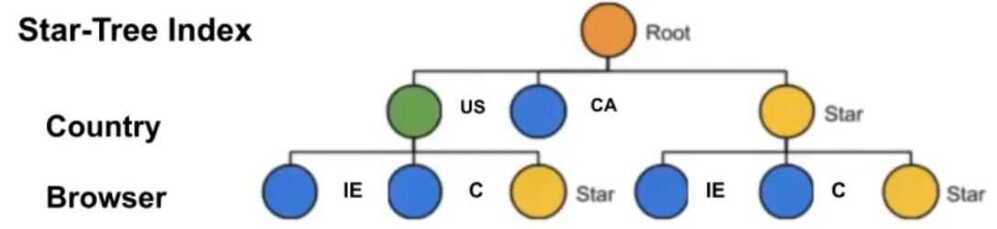
Star Tree Index
Allows us to maintain pre-aggregated values for some combination of dimensions example country and browser in below example. Incredible fast lookup.
https://engineering.linkedin.com/blog/2019/06/star-tree-index--powering-fast-aggregations-on-pinot
https://docs.pinot.apache.org/basics/indexing/star-tree-index
https://en.wikipedia.org/wiki/Search_engine_indexing