Deployment
Milvus Lite
Milvus Lite is a Python library that can be imported into your applications. As a lightweight version of Milvus, it is ideal for quick prototyping in Jupyter Notebooks or running on smart devices with limited resources. Milvus Lite supports the same APIs as other Milvus deployments. The client-side code interacting with Milvus Lite can also work with Milvus instances in other deployment modes.
To integrate Milvus Lite into your applications, run pip install pymilvus to install it and use the MilvusClient("./demo.db") statement to instantiate a vector database with a local file that persists all your data. For more details, refer to Run Milvus Lite.
Milvus Standalone
Milvus Standalone is a single-machine server deployment. All components of Milvus Standalone are packed into a single Docker image, making deployment convenient. If you have a production workload but prefer not to use Kubernetes, running Milvus Standalone on a single machine with sufficient memory is a good option.
Milvus Distributed
Milvus Distributed can be deployed on Kubernetes clusters. This deployment features a cloud-native architecture, where ingestion load and search queries are separately handled by isolated nodes, allowing redundancy for critical components. It offers the highest scalability and availability, as well as the flexibility in customizing the allocated resources in each component. Milvus Distributed is the top choice for enterprise users running large-scale vector search systems in production.
Recommendation
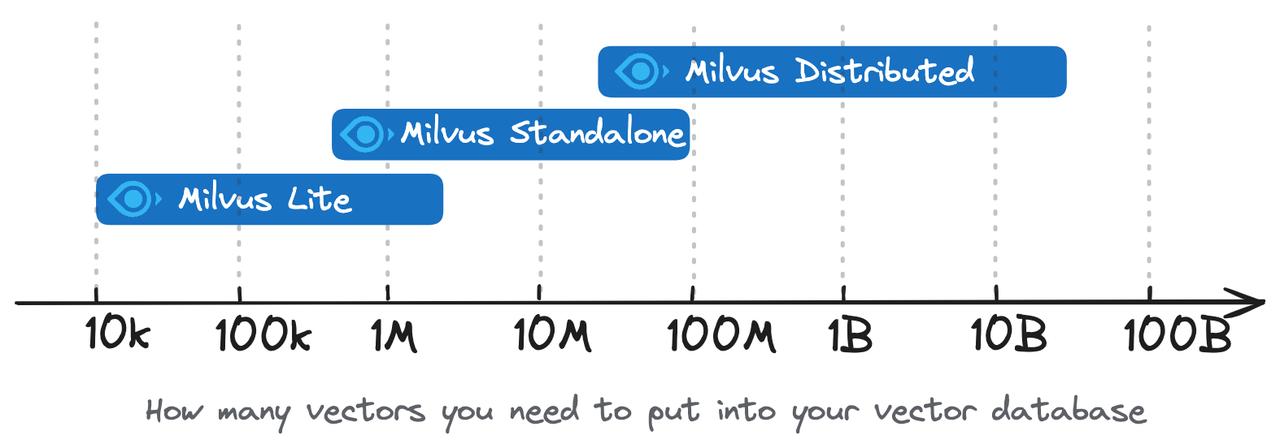
- Milvus Lite is recommended for smaller datasets, up to a few million vectors.
- Milvus Standalone is suitable for medium-sized datasets, scaling up to 100 million vectors.
- Milvus Distributed is designed for large-scale deployments, capable of handling datasets from 100 million up to tens of billions of vectors.
Overview of Milvus Deployment Options | Milvus Documentation