Understanding Consensus Protocols in Distributed Systems
There are a number of ways we can go about replicating the log data. Broadly speaking, we can group the techniques into two different categories:
Gossip / Multicast Protocols
These tend to be eventually consistent and/or stochastic.
- Epidemic broadcast trees
- Bimodal multicast
- SWIM
- HyParView
- NeEM
Consensus Protocols
These tend to favor strong consistency over availability.
- 2PC/3PC
- Paxos
- Raft
- Zab (Zookeeper atomic broadcast)
- Chain replication
Paxos - Consensus over distributed hosts
Ex - doing a leader election among a distributed host.
Multi-paxos - models the log as a series of consensus problems, one for each slot in the log
Paxos is the original distributed consensus algorithm, with modified versions used by Chubby and many others. (Zookeeper's ZAB is similar to Paxos as well.)
https://lamport.azurewebsites.net/tla/paxos-algorithm.html
Paxos lecture (Raft user study)
https://engineering.fb.com/2022/03/07/core-data/augmenting-flexible-paxos-logdevice
Raft - Consensus Algorithm
RAFT is a much simpler consensus algorithm.
Used by
- Consul
- Used by etcd (distributed key value store)
http://thesecretlivesofdata.com/raft
SWIM
SWIM is a distributed gossip protocol for group membership (e.g. for determining members of a caching ring, etc)
Two-Phase Commit Protocol
In transaction processing, databases, and computer networking, thetwo-phase commit protocol(2PC) is a type of atomic commitment protocol(ACP). It is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit orabort(roll back) the transaction (it is a specialized type of consensus protocol). The protocol achieves its goal even in many cases of temporary system failure (involving either process, network node, communication, etc. failures), and is thus widely used.However, it is not resilient to all possible failure configurations, and in rare cases, manual intervention is needed to remedy an outcome. To accommodate recovery from failure (automatic in most cases) the protocol's participants use logging of the protocol's states. Log records, which are typically slow to generate but survive failures, are used by the protocol's recovery procedures. Many protocol variants exist that primarily differ in logging strategies and recovery mechanisms. Though usually intended to be used infrequently, recovery procedures compose a substantial portion of the protocol, due to many possible failure scenarios to be considered and supported by the protocol. In a "normal execution" of any single distributed transaction(i.e., when no failure occurs, which is typically the most frequent situation), the protocol consists of two phases:
-
The commit-request phase (or voting phase / prepare phase), in which a coordinator process attempts to prepare all the transaction's participating processes (named participants, cohorts, or workers) to take the necessary steps for either committing or aborting the transaction and to vote, either "Yes": commit (if the transaction participant's local portion execution has ended properly), or "No": abort (if a problem has been detected with the local portion), and
-
The commit phase, in which, based on voting of the participants, the coordinator decides whether to commit (only if all have voted "Yes") or abort the transaction (otherwise), and notifies the result to all the participants. The participants then follow with the needed actions (commit or abort) with their local transactional resources (also called recoverable resources; e.g., database data) and their respective portions in the transaction's other output (if applicable).

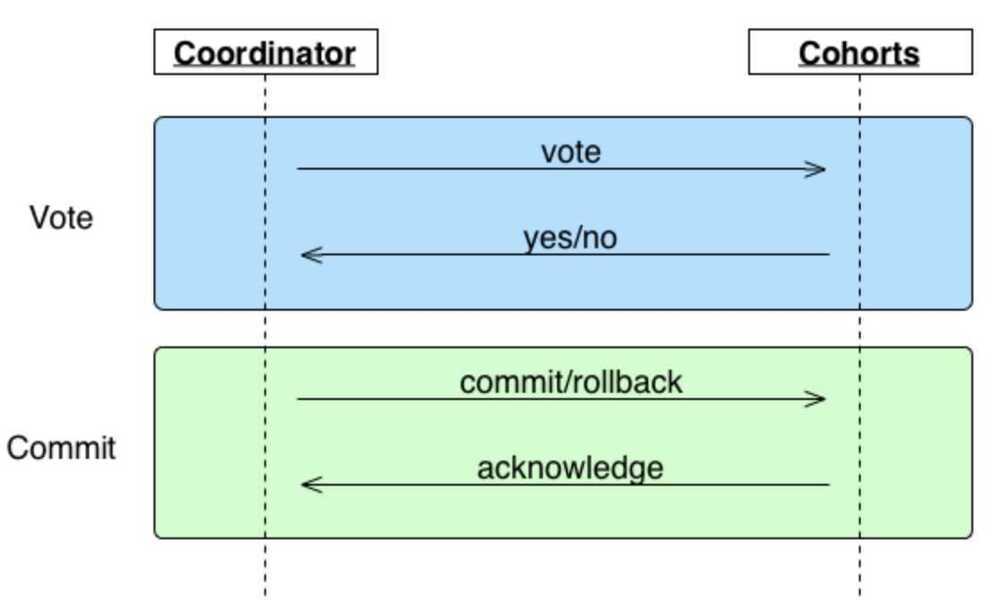
Two-phase commit is a blocking protocol. The coordinator blocks waiting for votes from its cohorts, and cohorts block waiting for a commit/rollback message from the coordinator. Unfortunately, this means 2PC can, in some circumstances, result in a deadlock, e.g. the coordinator dies while cohorts wait or a cohort dies while the coordinator waits. Another problematic scenario is when a coordinator and cohort simultaneously fail. Even if another coordinator takes its place, it won't be able to determine whether to commit or rollback.
https://en.wikipedia.org/wiki/Two-phase_commit_protocol
https://bravenewgeek.com/understanding-consensus/
3 Phase Commit

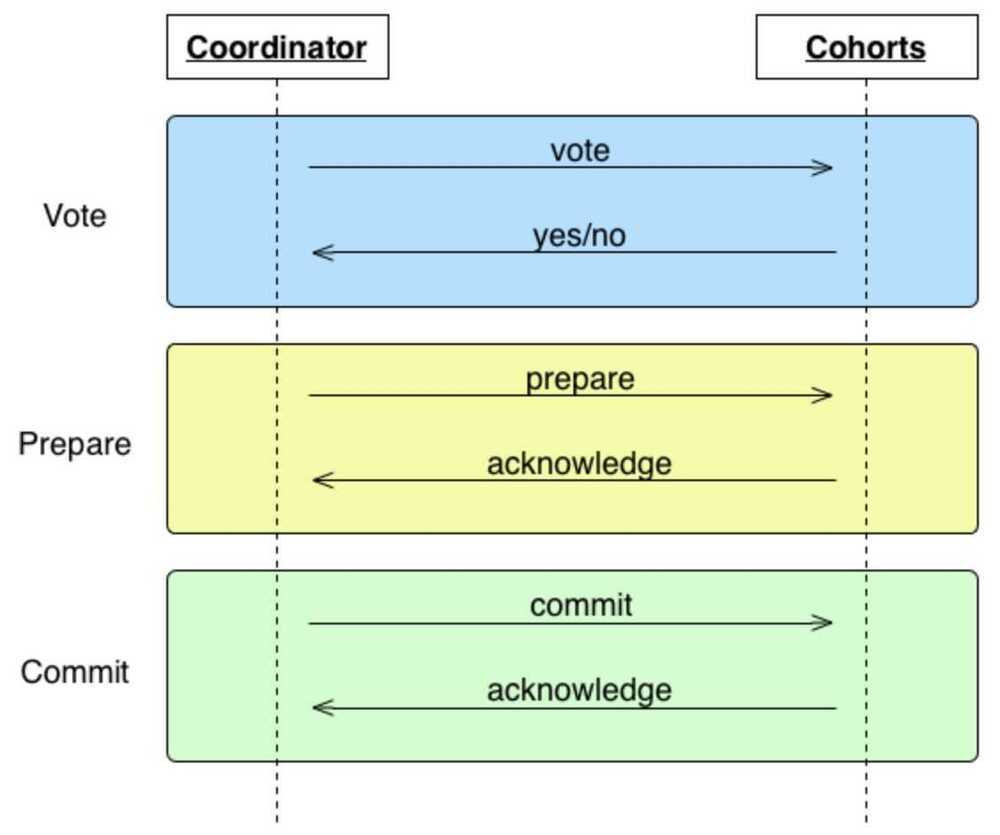
Three-phase commit (3PC) is designed to solve the problems identified in two-phase by implementing a non-blocking protocol with an added "prepare" phase. Like 2PC, it relies on a coordinator which relays messages to its cohorts.
Unlike 2PC, cohorts do not execute a transaction during the voting phase. Rather, they simply indicate if they are prepared to perform the transaction. If cohorts timeout during this phase or there is one or more "no" vote, the transaction is aborted. If the vote is unanimously "yes," the coordinator moves on to the "prepare" phase, sending a message to its cohorts to acknowledge the transaction will be committed. Again, if an ack times out, the transaction is aborted. Once all cohorts have acknowledged the commit, we are guaranteed to be in a state where all cohorts have agreed to commit. At this point, if the commit message from the coordinator is not received in the third phase, the cohort will go ahead and commit anyway. This solves the deadlocking problems described earlier. However, 3PC is still susceptible to network partitions. If a partition occurs, the coordinator will timeout and progress will not be made.
https://bravenewgeek.com/understanding-consensus
State Replication
Protocols like Raft, Paxos, and Zab are popular and widely used solutions to the problem of distributed consensus. These implement state replication or primary-backup using leaders, quorums, and replicas of operation logs or incremental delta states.
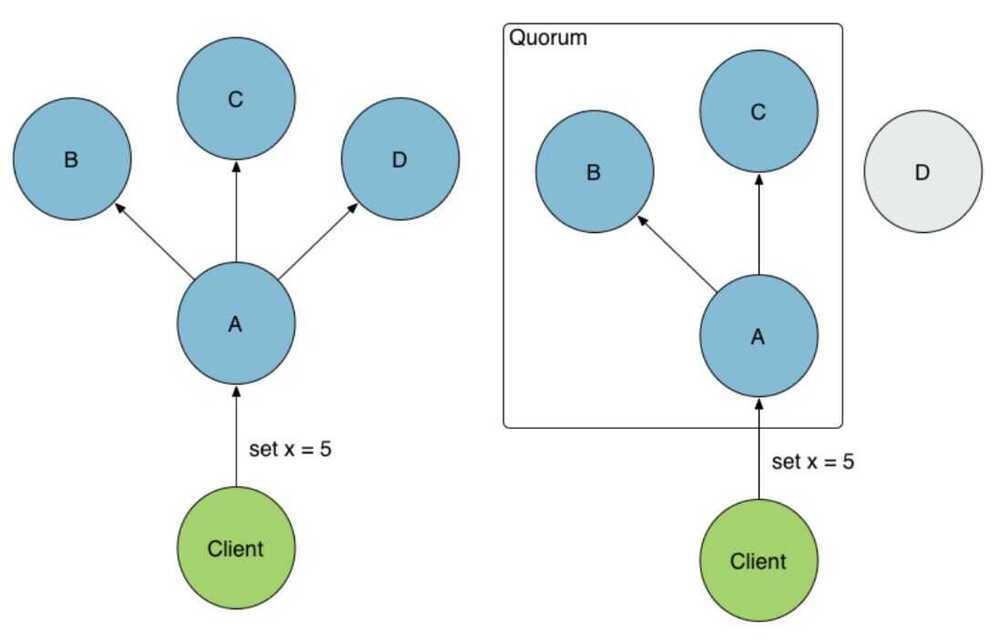
These protocols work by electing a leader (coordinator). Like multi-phase commit, all changes must go through that leader, who then broadcasts the changes to the group. Changes occur by appending a log entry, and each node has its own log replica. Where multi-phase commit falls down in the face of network partitions, these protocols are able to continue working by relying on a quorum (majority). The leader commits the change once the quorum has acknowledged it.
The use of quorums provide partition tolerance by fencing minority partitions while the majority continues to operate.This is the pessimistic approach to solving split-brain, so it comes with an inherent availability trade-off. This problem is mitigated by the fact that each node hosts a replicated state machine which can be rebuilt or reconciled once the partition is healed.
Google relies on Paxos for its high-replication datastore in App Engine as well as its Chubby lock service. The distributed key-value store etcd ⭐ 52k uses Raft to manage highly available replicated logs. Zab, which differentiates itself from the former by implementing a primary-backup protocol, was designed for the ZooKeeper coordination service. In general, there are several different implementations of these protocols, such as the Go implementation ⭐ 2.4k of Raft.
https://bravenewgeek.com/understanding-consensus
SAGA Pattern (Asynchronous Distributed Transactions)
Context
You have applied the Database per Service pattern. Each service has its own database. Some business transactions, however, span multiple service so you need a mechanism to implement transactions that span services. For example, let's imagine that you are building an e-commerce store where customers have a credit limit. The application must ensure that a new order will not exceed the customer's credit limit. Since Orders and Customers are in different databases owned by different services the application cannot simply use a local ACID transaction.
Solution
Implement each business transaction that spans multiple services is a saga. A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
Types of SAGA Implementation
1. Choreography - Event based
Each local transaction publishes domain events that trigger local transactions in other services

2. Orchestration - Command based
An orchestrator (object) tells the participants what local transactions to execute
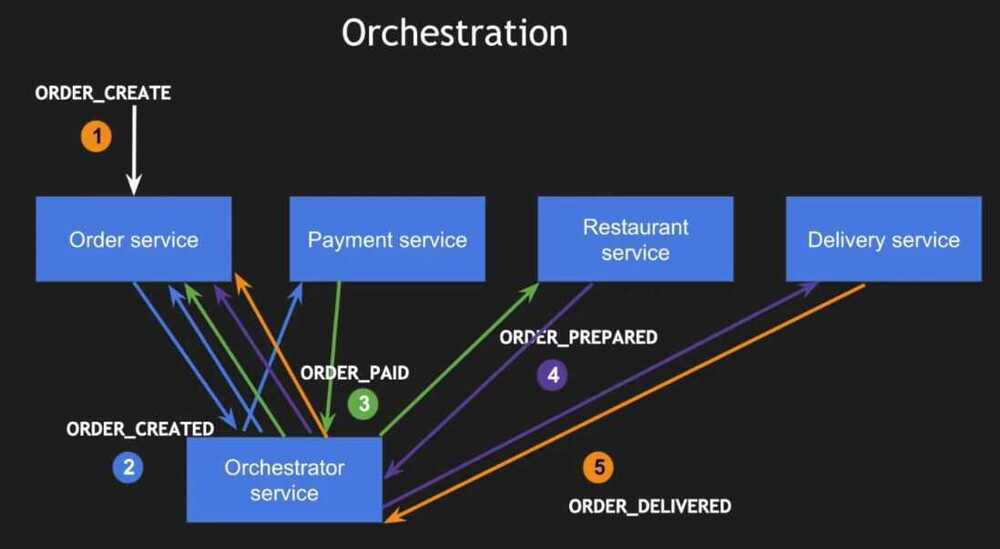
Youtube - SAGA | Microservices Architecture Patterns | Tech Primers
Youtube - Do you know Distributed transactions?
https://microservices.io/patterns/data/saga.html
Gossip / Gossiping
A gossip protocol is a procedure or process of computer peer-to-peer communication that is based on the way that epidemics spread. Some distributed systems use peer-to-peer gossip to ensure that data is routed to all members of an ad-hoc network. Some ad-hoc networks have no central registry and the only way to spread common data is to rely to each member to pass it along to their neighbors.
The term epidemic protocol is sometimes used as a synonym for a gossip protocol, because gossip spreads information in a manner similar to the spread of a virus in a biological community.
https://en.wikipedia.org/wiki/Gossip_protocol
FLP Impossibility
States that reaching a multi-party consensus in a asynchronous system is not possible and, in order for consensus to be reachable, we need Failure Detectors.
In order for processes to agree, several invariants have to be persevered:
- value that's being agreed on has to be "proposed" by one of the participants
- all active (non-crashed) participants have to decide on the value
- value they eventually decide on has to be the same for all processes
In a paper by Fisher, Lynch and Paterson, famously known as FLP Impossibility Problem (derived from the first letters of authors' last names), authors discuss a weak form of consensus in which processes start with an initial value and have to achieve an agreement on a new value. This new value has to be the same for all non-faulty processes.
Paper concludes that in an asynchronous system, no consensus protocol can be totally correct in presence of even a single fault. If we do not consider an upper time bound for process to complete the algorithm steps and if process failures can't be reliably detected, FLP paper shows that there's no deterministic algorithm to reach a consensus.
However, FLP proof does not mean we have to pack our things and go home, as reaching consensus is not possible. It only means that it can't always be reached in bounded time. In practice, systems exhibit partial synchronicity, which puts partially synchronous system between the cases of asynchronous and synchronous ones. Nancy Lynch, one of the FLP proof authors, has later authored Consensus in the Presence of Partial Synchrony paper, where several partially synchronous models are discussed, one of them holding timing assumptions that are not known in advance and the other one, where timing assumptions are known, but start holding up at an unknown time.
https://medium.com/databasss/on-ways-to-agree-part-1-links-and-flp-impossibility-f6bd8a6a0980